Analysis is concerned with building an abstract model of the problem and an object structure for solving the problem. The details are stripped off, leaving a highly abstract description how the problem can be solved. The goal is to make the problem domain understandable and to provide a framework for the design.
A message has a structure. The structure decomposes the message at different levels of
abstraction. The highest level of abstraction is represented as an object describing the entire
message. Lesser abstract levels consist of objects that may represent the parts of the message etc.
Each of these objects has relations to attributes, data and to other
objects. Typically a message
object has relations to a header object and a body object (figure 1). Note that the object
structure itself does not contain any data obtained from the message, it describes the structure of
the message, using the message format, and the objects of this structure has relations to some
pieces of data that may be part of the message.
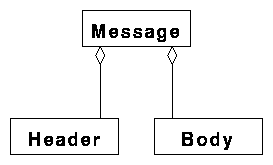
Figure 1. Rudimentary structure of a message.
The Message Object has a few attributes that are common to the entire message. Some of these attributes are:
Typically the values of these attributes are found in the envelope and the header of the message. However, the format type of the message can not always be unambiguously derived from the header, it may be necessary to perform a scan of the body aswell.
The header of a message is also structured. It may consist of several lines of text conforming with a syntactical pattern described by the message format, each having some semantic meaning and containing some data or information.
A header line consists of a pattern and some data, or arguments
to the format. These arguments are contained in data objects (figure 2).
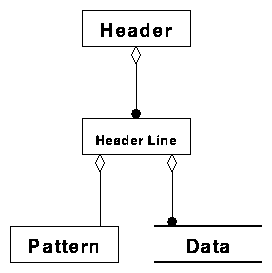
Figure 2. The Header Object and it's relations.
The body may also contain structured data or information. Data may have a type in which case it is information. Data may be encoded and it may be represented in a character set. Data may also be binary and this is a distinction from text, see below.
RFC822 defines that the body of a message contains lines of text. Text is typically represented in a particular character set. It may be encoded and it may also contain encoded binary parts, this is a wide definition of text. MIME elaborates this and defines a grammar for body type and encoding . Still, a MIME text is no different from a general text and can thus contain encoded binary parts.
There are two types of bodies; single part bodies and multi part bodies. This distinction is handled by a boolean attribute of the body object. Each body object has relations to body part objects. When the body object has relations to more than one body part object it is a multi part body.
The body part object has some attributes describing the body part. Among those are:
In case of a MIME message those attributes can be retrieved from the data objects in the header structure (The attributes are references to other objects). In some cases the attributes can only be retrieved from the body part data itself. The character set may also be retrieved from the configuration files.
The body part objects has relations to data objects containing the data of the body part
(figure 3).

Figure 3. The Body Object.
As was described in the previous section a message is a structured body of data. But it is important to understand the relationships within the structure aswell, understanding the structure only is not enough.
The envelope contains information about the sender and the recipient of a message. The header of a message contains To-address and From-address but these have no direct relation to the information in the envelope. While the envelope gives information about the origin and destination of the message to the MTA (Mail Transfer Agent), the header gives similar, but not necessarily identical, information to the recipient. The relationship of the envelope is to the Message object, the message itself.
The format (For example MIME) is a description of the structure and the syntax of a message. It describes what the message should look like for it to be properly handled by the MTA and the UA (User Agent). If the message does not conform with the mutually agreed format, chances are that the transport of the message will fail, and even if transport does not fail the recipient may not be able to view the message as intended. The format describes the message but the format is not part of the message. The relationships between the format and the message are primarily to the message object, the header line object and the body part object.
The objects within the message also have relations other than those of the structure itself. One of these is the relationship between the header line data and the body part object; In a MIME message filename and type is described in a header line for each body part. Another relation is the one between the body part object and the body part data; A BinHexed attachment contains file name and file type within the attachment.
Another relationship is between the body part data and the message object; In a MIME multi part message the body parts can be seen as message objects, they contain headers and a body. Although some body parts may contain an empty header, this is actually supported by the structure. This makes MIME multi part messages very different from other message types with multiple parts. This difference needs a workaround for the structure to be suitable.
The relations described above are displayed in figure 4.
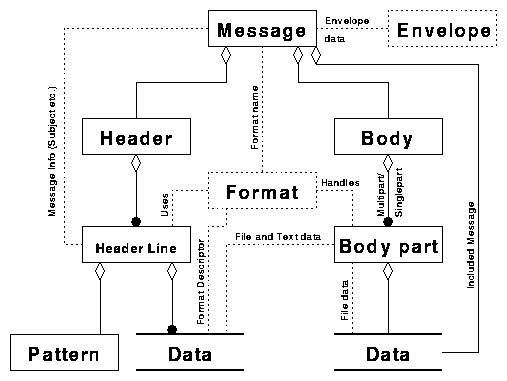
Figure 4. Relations between objects within a message.
The previous section described the format as one object. By looking at the relationships it is quite easy to see that the format must be described in a more complex manner. Indeed the structure of the format is not so much different from the structure of the message.
The format needs to declare what kinds of header lines and what types of body part objects it supports. If dealing with encoded body part data, the format also declares what methods of encoding are available for use.
Elaborating the format yields figure 5.
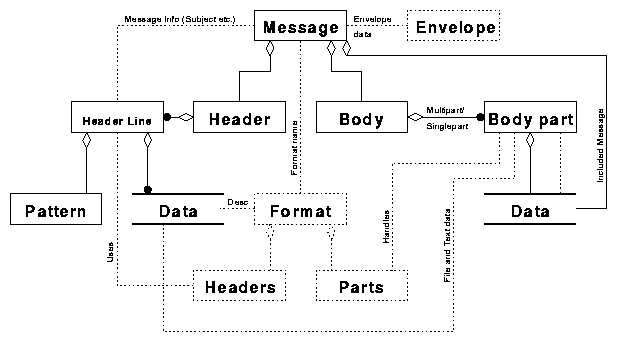
Figure 5. Including a structured format object.
Looking back at the basic structure of a message, it is obvious that different formats generate
different structures (figure 6). The greatest difference is between the unstructured formats of 6a and 6c and
the structured formats of 6b and 6d. Converting between these two methods of structure is not so easy.
Making the problem simpler would be to change the internal representation of the unstructured formats
towards the representation of the structured formats (figure 7). Here the top level of the message (named
0, zero) is common to all formats, while the lower level 1 is only available for structured
formats. The MIME formats allows an arbitrary depth of the structure while SUN Mailtool allows
only level 0 and 1.
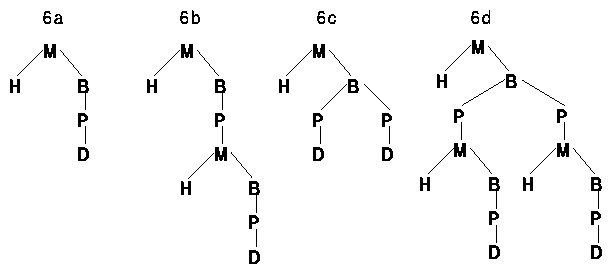
Figure 6. Basic message structures. The object names are abbreviated
according to: M = message object, H = header object, B = body object,
P = body part object, D = data object. 6a shows a single part message.
6b shows a message with a single part attachment in SUN Mailtool
format. 6c shows a multipart unstructured format message. 6d shows
a multipart message according to MIME and SUN Mailtool.
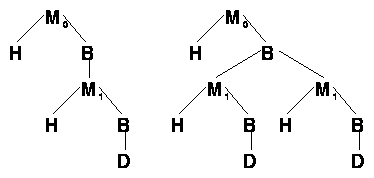
Figure 7. Preparing structure levels in the message structure.
Using this representation it will be possible to structure a message similarly for different formats. A non structured format must ignore the effects of message objects other than level 0 while a SUN Mailtool format ignores level 2 and deeper. Care must be taken while constructing the structure that the recursiveness of this representation is strictly controlled, avoiding unwanted loops. A message object generated because of a single body part object should be marked so that the descendant of the body part object one level below always is a data object.
One of the main problems of parsing a message is identifying the delimiters of the body parts. The end delimiter of a header is easy to find; a CRLF on a line on it's own. The end delimiter of a text is somewhat more hard to find.
If the body parts of an unstructured message is divided into two groups, parts of type text and parts of type encoded data, the classification becomes:
There are two more methods of decomposing a message:
When a message comes in Emil must be able to recognize the structure and format information to use when parsing it. Other information that can be of great importance is the default character set used by the sender. MIME and SUN Mailtool formats are specified in the message itself by specific header lines. When the message is not in either of those formats a default character set for the sender must be used.
The differences between input and output, although at the same level of abstraction, is to great to span in a single step. Emil uses a multipass design to accomplish transformation. Because of this, it is possible to divide the problem of transformation into several smaller problems making it easier to grasp.
Decomposing the overall function of Emil into clearly defined functions yields:
This is a rough model of the functions performed by Emil.
|
March 1996
ITS Uppsala university
|
Martin Wendel |

|