This chapter describes the architecture of sendmail X. It presents some possible design choices for various parts of sendmail X and explains why a particular choice has been made. Notice: several decisions haven't been made yet, there are currently a lot of open questions.
sendmail X consists of several communicating modules. A strict separation of functionality allows for a flexible, maintainable, and scalable program. It also enhances security by running only those parts with special privileges (e.g., root, which will be used as a synonym for the required privileges in this text) that really require it.
Some terms relevant for e-mail are explained in a glossary 2.17.
sendmail X consists of the following modules:
sendmail X uses persistent databases for content (CDB) and for envelope (routing) information (EDB). The content DB is written by the SMTP servers only, and read by the delivery agents. The envelope DBs are under complete control of the queue manager.
There are other components for sendmail X, e.g., a recovery program that can reconstruct an EDB after a crash if necessary, a program to show the content of the mail queue (EDB), and at least hooks for status monitoring.
Since sendmail X is designed to have a lifetime of about one decade, it must not be tuned to specific bottlenecks in common computers as they are known now. For example, even though it seems common knowledge that disk I/O is the predominant bottleneck in MTAs, this isn't true in all cases. There is hardware support (e.g., disk system with non-volatile RAM) that eliminates this bottleneck2.1. Moreover, some system tests show that sendmail 8 is CPU bound on some platforms. Therefore the sendmail X design must be well-balanced and it must be easy to tune (or replace) subsystems that become bottlenecks in certain (hardware) configurations or situations.
This section contains some general remarks about configuring sendmail X. Todo: fill this in, add a new section later on that defines the configuration.
sendmail X must be easy enough to configure such that it does not require reading lots of files or even large section of a single file (see also Section 1.4). A ``default'' configuration may not require any configuration at all, i.e., the defaults should be stored in the binary and most of the required values should be automagically be determined at startup. A small configuration file might be necessary to override those defaults in case the system cannot determine the right values. Moreover, it is usually required to tell the MTS for which domain name to accept mail - by default a computer should have a FQDN but it is not advisable to decide to accept mail for the domain name itself2.2
The configuration file must be suitable for all kinds of administrators: at one end of the spectrum are those who just want to have an MTA installed and running with minimum effort, at the other end are those who want to tweak every detail of the system and maybe even enhance it by other software.
Only a few configuration options apply globally, many have
exceptions or suboptions that apply in specific situations.
For example, sendmail 8 has timeouts for most SMTP commands
and there are separate timeouts to return queued messages
for different precedence values.
Moreover, some features can be determined by rulesets,
some options apply on a per connection basis, etc.
In many cases it is useful to group configuration options together
instead of having those options very fine grained.
For examples, there are different SMTP mailers in sendmail 8
that create configuration groups (with some preselected set of options)
which can be selected via mailertable (or rules).
Instead of having mailer options per destination host (or other criteria),
different options are grouped together and then an option set is selected.
This can reduce the amount of configuration options that need to be stored
(e.g., it's a two level mapping:
address ![]() mailer
mailer ![]() mailer flags,
instead of just one level in which each argument
can have different function values:
address
mailer flags,
instead of just one level in which each argument
can have different function values:
address ![]() mailer and mailer flags).
mailer and mailer flags).
However, it might be complicated to actually structure options in a tree like manner. For example, a rewrite configuration option may be
Question: can we organize options into a tree structure? If not, how should we specify options and how should we implement them? Take the above example: there might be rewrite options per mailer and per address type (seems to make sense). However, in which order should those rewrite options be processed? Does that require yet another option?
A simple tree structure is not sufficient. For example, some option groups may share common suboptions, e.g., rewrite rules. Instead of having to specify them separately in each group, it makes more sense to refer to them. Here is an example from sendmail 8: there are several different SMTP mailers, but most of them share the same rewrite rulesets. In a strict tree structure each mailer would have a copy of the rewrite rulesets, which is neither efficient nor simple to maintain. Hence there must be something like ``subroutines'' which can be referenced. In a sendmail 8 configuration file this means there is a list of rulesets which can be referenced from various places, e.g., the binary (builtin ruleset numbers) and the mailers.
This means internally a configuration might be represented as a graph with references to various subconfigurations. However, this structure can be unfolded such that is actually looks like a tree. Hence, the configuration can conceptually be viewed as a tree.
There should be a way to query the system about the current configuration and to change (some) options on the fly. A possible interface could be similar to sysctl(8) in BSD. Here options are structured in a tree form with names consisting of categories and subscategories separated by dots, i.e., ``Management Information Base'' (MIB) style. Such names could be daemon.MTA.port, mailer.local.path, etc. If we can structure options into a tree as mentioned in the previous section then we can use this naming scheme. Whether it will be possible to change all parts on the fly is questionable, esp. since some changes must be done as transaction (all at once or none at all).
Each section of this chapter that describes a module of sendmail X has a subsection about security considerations for that particular part. More discussion can be found in Section 2.14.
This section gives an overview over the control and data flow for a typical situation, i.e., e-mail received via SMTP. This should give an idea how the various components interact. More details can be found in the appropriate sections.
Question: can we treat a configuration file like a programming language with
Definitions do not depend on anything else, they define the basic structure (and behavior?) of the system. There are fixed attributes which cannot be changed at runtime, e.g., port number, IP address to listen on. Attributes which can change at runtime, e.g., the hostname to use for a session, fall in category 3, i.e., they are functions which can determine a value at runtime.
The distinction between definitions and functions is largely determined by the implementation and the underlying operating system as well as the application protocol to implement and the underlying transport protocol. When defining an SMTP daemon (or a DA) some of its attributes must be fixed (defined/specified) in the configuration, these are called immutable. For example, it is not possible to dynamically change the port of the SMTP daemon because that's the way the OS call bind(2)2.4 works. However, the IP address of the daemon does not need to be fixed (within the capabilities of the OS and the available hardware), i.e., it could listen on exactly one IP address or on any. Such configuration options are called variable or mutable2.5.
It seems to be useful to make a list of configuration options and their ``configurability'', i.e., whether they are fixed, or at which places they can change, i.e., on which other values they can depend.
As required, the semantics of the configuration file does not depend on its layout, i.e., spaces are only important for delimiting syntactic entities, tabs (whitespace) do not have a special meaning.
The syntax of the sendmail X configuration files is as follows:
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | "{" |
This can be shortened to (remove the rule for entries):
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | ||
| ::= | "{" |
Generic definition of ``list'':
| ::= |
That is, a configuration file consists of a several entries,
each of which is either a section or an option.
A section starts with a keyword, e.g., mailer, daemon, rewriterules,
and has an optional name, e.g., daemon MTA.
Each section contains a section of entries which is embedded in curly braces.
Each syntactic entity that isn't embedded in braces
is terminated with a semicolon.
An entry in a section can be an option or a (sub)configuration.
To make writing configuration files simpler,
lists can have a terminating comma and a semicolon
can follow after ![]() values
values![]() .
That makes these symbols terminators not separators.
.
That makes these symbols terminators not separators.
Examples:
mailer smtp {
Protocol = SMTP;
Connection = TCP;
Port = mtp;
flags { DSN }
MaxRecipientsPerSession = 5;
};
mailer lmtp {
Protocol = LMTP;
flags = { LocalRecipient, Aliases }
Path = "/usr/bin/lmtp";
};
Daemon MTA {
smtps-restriction = { qualified-sender, resolvable-domain }
};
Map Mailertable { type = hash; file = "/etc/smx/mailertable"; };
Rewrite {
Envelope {
sender = { Normalize, Canonify },
recipient = { Normalize, Virtual, Mailertable }
};
Header {
sender = { Normalize },
recipient = { Normalize }
};
};
Check {
DNSBL MyDNSBL { Orbd, Maps }
Envelope {
sender = { Qualified, MyDNSBL },
recipient = { Qualified, AuthorizedRelay }
};
};
The usual rules for identifiers
(list of characters, digits, and underscores) apply.
Values (![]() name
name![]() ) that contain spaces must be quoted,
other entries can be quoted, but don't need to.
Those quotes are stripped in the internal representation.
Backslashes can be used to escape meta-symbols.
) that contain spaces must be quoted,
other entries can be quoted, but don't need to.
Those quotes are stripped in the internal representation.
Backslashes can be used to escape meta-symbols.
Todo: completely specify syntax.
Note: it has been proposed to make the equal sign optional for this rule:
| ::= |
However, that causes a reduce/reduce conflict when the grammar is fed into yacc(1)2.6because it conflicts with
| ::= |
That is, with a lookahead of one it can not be decided whether something
reduces to ![]() option
option![]() or
or ![]() section
section![]() .
If the parser ``knows'' whether some identifier is a keyword or
the name of an option then the equal sign can easily be optional.
However, doing so violates the layering principle
because it ``pushes'' knowledge about the actual configuration file
into the parser where it does not really belong:
the parser should only know about the grammar.
Of course if would be possible to write a more specific grammar
that includes lists of options and keywords.
However, keeping the grammar abstract (hopefully) allows for simpler tools
to handle configuration files.
Moreover, if new options or keywords are added the parser does not
need to change, it is only the upper layers that perform semantic
analysis of a configuration file.
.
If the parser ``knows'' whether some identifier is a keyword or
the name of an option then the equal sign can easily be optional.
However, doing so violates the layering principle
because it ``pushes'' knowledge about the actual configuration file
into the parser where it does not really belong:
the parser should only know about the grammar.
Of course if would be possible to write a more specific grammar
that includes lists of options and keywords.
However, keeping the grammar abstract (hopefully) allows for simpler tools
to handle configuration files.
Moreover, if new options or keywords are added the parser does not
need to change, it is only the upper layers that perform semantic
analysis of a configuration file.
Most configuration/programming languages provide at least one way to add comments: a special character starts a comment which extends to the end of the line. Some languages also have constructs to end comments at a different place than the end of a line, i.e., they have characters (or character sequences) that start and end a comment. To make it even more complicated, some languages allow for nested comments. Text editors make it fairly easy to replace the begin of a line with a character and hence it is simple to ``comment out'' entire sections of a (configuration) file. Therefore it seems sufficient to have just a simple comment character (``#'') which starts a comment that extends to the end of the current line. The comment character can be escaped, i.e., its special meaning disabled, by putting a backslash in front of it as usual in many languages.
For now all characters are in UTF-8 format which has ASCII has a proper subset. Hence it is possible to specify texts in a different language, which might be useful in some cases, esp. if the configuration syntax is also used in other projects than sendmail X.
Strings are embedded (as usual) in double quotes.
To escape special characters inside strings the usual C conventions
are used, probably enhanced by a way to specify unicode characters
(``![]() uVALUE'').
Strings can not continue past the end of a line,
to specify longer strings they can be continued by starting
the next line (after any amount of white space) with a double quote
(just like in ANSI C).
uVALUE'').
Strings can not continue past the end of a line,
to specify longer strings they can be continued by starting
the next line (after any amount of white space) with a double quote
(just like in ANSI C).
The parser should be able to to some basic semantic checks for various types. That is, it can detect whether strings are well formed (see above), and it must understand basic types like boolean, time specification, file names, etc.
There has been a wish to include configuration data via files or even databases, e.g., OpenLDAP attributes.
There are some suggestions for alternative configuration formats:
option = value
This syntax is not flexible enough to describe the configuration of an MTA, unless some hacks are employed as done by postfix which uses an artificial structuring by naming the options ``hierarchically''. For example, sendmail 8 uses a dot-notation to structure some options, e.g., timeouts (Timeout.queuereturn.urgent); postfix uses underscores for a similar purpose, e.g.,
smtpd_recipient_restrictions = smtpd_sender_restrictions = local_destination_concurrency_limit = default_destination_concurrency_limit =
An explicit hierarchical structure is easier to understand and to maintain.
SMTP defines a structure which influences how a SMTP server (and client) can be configured. The topmost element in SMTP is a session, which can contain multiple transactions, which can contain multiple recipients and one messsage. Each of these elements has certain attributes (properties). For example
This structure restricts how a SMTP server can be configured. Some things can only be selected (``configured'') at a certain point in a session, e.g., a milter can not be selected for each recipient2.7, neither can a server IP address selected per transaction, other options have explicit relations to the stage in a session, e.g., MaxRecipientsPerSession, MaxRecipientsPerTransaction (which might be better expressed as Session.MaxRecipients and Transaction.MaxRecipients or Session.Transaction.MaxRecipients). Some options do not have a clear place in a session at all, e.g., QueueLA, RefuseLA: do these apply to a session, a transaction or a recipient? It is possible to use QueueLA per recipient, but only in sendmail X because it does scheduling per recipient, in sendmail 8 scheduling is done per transaction and hence QueueLA can only be per transaction. This example shows that an actual implementation restricts the configurability, not just the protocol itself.
If a SMTP session is depicted as a tree (where the root is a session) then there is a ``maximum depth'' for each option at which it can be applied. As explained before, that depth is determined
Question: taking these restrictions into consideration, can we specify the maximum depth for each configuration option at which the setting the option is possible/makes sense? Moreover, can we specify a range of depths for options? For example: QueueLA can be a global option, an option per daemon, an option per session, etc. If such a range can be defined per option, then the configuration can be checked for violations. Moreover, it restricts the ``search'' for the value of an option that must be applied in the current stage/situation.
Question: it seems the most important restriction is the implementation (beside the structure of SMTP of course). If the implementation does not check for an option at a certain stage, then it does not make any sense to specify the option at that stage. While for some options it is not much effort to check it at a very deep level, for others that means that data structures must be replicated or be made significantly more complex. Examples:
recipient postmaster { reject-client-ip {map really-bad-abusers} }
recipient * { reject-client-ip {map all-abusers} }
This brings us back to the previous question: Question: can we specify the maximum depth for each configuration option at which the setting the option makes sense or at which it is possible without making the implementation too complex.
There are other configuration options which do not really belong to that structure, e.g., ``mailers'' (as they are called in sm8). A mailer defines a delivery agent (DA), it is selected per recipient. Hence a DA describes the behavior of an SMTP client, not an SMTP server. In turn, many options are per DA too, while others only apply to the server, e.g., milters are server side only2.9.
Problem: STARTTLS is a session atttribute, i.e., whether it is used/offered is defined per client/server (per session). However, it is useful (and possible) to require certain STARTTLS features per recipient2.10(as sm8 does via access db and ruleset). It is not possible to say: only offer STARTTLS feature X if the recipient is R, but it is possible to say: if the recipient is R then STARTTLS feature X must be in use (active). Moreover, it's not possible to say: "if the recipient is R, the milter M must be used." How do those configuration options fit into the schema explained above? What's the qualitative difference between these configuration options?
Questions: What's the qualitative difference between these examples? What is the underlying structure? How does the structure define configurability, i.e., what defines why a behavior/option can be dependent on something but not on something else?
For example: STARTTLS in client (SMTPC): this isn't really: ``use STARTTLS with feature X if recipient R will be send'', but it is: ``if recipient R will be send then STARTTLS with feature X must be active'' (similar to SMTPS). However, it is conceivable to actually do the former, i.e., make a session option based on recipient because smX can do per recipient scheduling, i.e., a DA is selected per recipient. Hence it can be specified that a session to deliver recipient R must have STARTTLS feature X. However, doing that makes connection reuse significantly more complicated (see Section 3.4.10.2). Question: doesn't this define a specific DA? Each DA has some features/options. Currently the use of STARTTLS is orthogonal to DAs (e.g., almost completely independent) hence the connection reuse problem (a connection is defined by DA and server, not DA and server and specific features because those features should be in the DA definition). Hence if different DAs are defined based on whether STARTTLS feature X should be used, then we tied a session to DA and server. This brings us to the topic of defining DAs. Question: what do we need ``per DA'' to make things like connection reuse simple? Note: if we define DAs with all features, then we may have a lot of DAs. Hence we should restrict the DA features to those which are really specific to a DA (connection/session/transaction) behavior, and cannot be defined independently. For example, it doesn't seem to be useful to have a DA for each different STARTTLS and AUTH feature, e.g., TLS version, SASL mechanism, cipher algorithm, and key length. However, can't we leave that decision up to the admin?
In addition to simple syntax checks, it would be nice to check a configuration also for consistency. Examples?
As explained in Section 2.1.3.2 there are some issues with the structuring of the configuration options. Here is a simple example that should serve as base for a discussion:
Daemon MTA {
smtps-restriction { qualified-sender, resolvable-domain }
mailer smtp { Protocol SMTP; Port smtp; flags { DSN }
MaxRecipientsPerSession 25;
};
Aliases { type hash; file /etc/smx/aliases; };
mailer lmtp { Protocol LMTP; flags { LocalRecipient, Aliases }
Path "/usr/bin/lmtp";
};
Map Mailertable { type hash; file /etc/smx/mailertable; };
Rewrite {
Envelope { sender { Normalize },
recipient { Normalize, Virtual, Mailertable }
};
Header { sender { Normalize }, recipient { Normalize } };
};
};
Daemon MSA {
mailer smtp { Protocol SMTP; Port submission; flags { DSN }
MaxRecipientsPerSession 100;
};
Aliases { type hash; file /etc/smx/aliases; };
mailer lmtp { Protocol LMTP; flags { LocalRecipient, Aliases }
Path "/usr/bin/lmtp";
};
Rewrite {
Envelope { sender { Normalize, Canonify },
recipient { Normalize, Canonify }
};
Header { sender { Normalize, Canonify },
recipient { Normalize, Canonify } };
};
};
This configuration specifies two daemons: MTA and MSA which share several subconfigurations, e.g., aliases and lmtp mailer, that are identical in both daemons. As explained in Section 2.1.3.2 it is better to not duplicate those specifications in various places. Here is the example again written in the new style:
aliases MyAliases { type hash; file /etc/smx/aliases; };
mailer lmtp { Protocol LMTP; flags { LocalRecipient, Aliases }
Path "/usr/bin/lmtp";
};
Daemon MTA {
smtps-restriction { qualified-sender, resolvable-domain }
mailer smtp { Protocol SMTP; Port smtp; flags { DSN }
MaxRecipientsPerSession 25;
};
aliases MyAliases;
mailer lmtp;
Map Mailertable { type hash; file /etc/smx/mailertable; };
Rewrite {
Envelope { sender { Normalize },
recipient { Normalize, Virtual, Mailertable }
};
Header { sender { Normalize }, recipient { Normalize } };
};
};
Daemon MSA {
mailer smtp { Protocol SMTP; Port submission; flags { DSN }
MaxRecipientsPerSession 100;
};
aliases MyAliases;
mailer lmtp;
Rewrite {
Envelope { sender { Normalize, Canonify },
recipient { Normalize, Canonify }
};
Header { sender { Normalize, Canonify },
recipient { Normalize, Canonify } };
};
};
Here the subconfigurations aliases and lmtp mailer are referenced explicitly from both daemon declarations. This is ok if there are only a few places in which a few common subconfiguration are referenced, but what if there are many subconfigurations or many places? In this case a new root of the tree would be used which declares all ``global'' options which can be overridden in subtrees. So the configuration tree would look like:
generic declarations
common root
daemon
mailer
?
Question: what is the complete structure of the configuration tree? Question: can the tree be specified by the configuration file itself, or is its structure fixed in the binary?
The next problem is how to find the correct value for an option. For example, how to determine the value for MaxRecipientsPerSession in this configuration:
MaxRecipientsPerSession 10;
Daemon MTA {
MaxRecipientsPerSession 25;
mailer smtp { ... }; };
mailer relay { MaxRecipientsPerSession 75; }; };
Daemon MSA {
MaxRecipientsPerSession 50;
mailer smtp { MaxRecipientsPerSession 100; }; };
Does this mean the system has to search in the tree for the correct value? This wouldn't be particularly efficient.
sendmail 8 also offers configuration via the access database, i.e., some tagged key is looked up to find potential changes for the configuration options that are specified in the cf file. For example, srv_features allows to set several options based on the connecting client (see also Section 2.2.6.2). This adds another ``search path'' to find the correct value for a configuration option. In this case there are even two tree structures that need to be searched which are defined by the host name of the client and its IP address, both of which are searched for in the database by removing the most significant parts of it, e.g., Tag:host.sub.tld, Tag:sub.tld, Tag:tld, Tag:.
What about a ``dynamic'' configuration, i.e., something that contains conditions etc? For example:
if client IP = A and LA < B then accept connection else if client IP in net C and LA < D and OpenConnections < E then accept connection else if OpenConnections < F then accept connection else if ConnectionRate < G then accept connection else reject connection fi
Note: it might be not too hard to specify a functional configuration language, i.e., one without side effects. However, experience with sm8 shows that temporary storage is required too2.13. As soon as assignments are introduced, the language becomes significantly more complex to implement. Moreover, having such a language introduces another barrier to the configuration: unless it is one that is established and widely used, people would have to learn it to use smX efficiently. For example, the configuration language of exim allows for runtime evaluation of macros (variables) and the syntax is hard to read (as usual for unknown languages). There are a few approaches to deal with this problem:
One proposal for the smX syntax includes conditionals in the form of
In sendmail 8 it proved to be useful to have some configuration options stored in maps. These can be as simple as reply codes to certain phases in ESMTP and for anti-relay/anti-spam checks, and as complex as the srv_features rulesets (see also Section 2.2.5).
There are several reasons to have configuration options in maps:
If not just anti-spam data is stored in maps but also more complicated options (as explained before: map entries for srv_features) then those options are usually not well structured, e.g., for the example it is just a sequence of single characters where the case (upper/lower) determines whether some features is offered/required. This does not fulfill the readability requirements of a configuration syntax for smX.
Question: how to integrate references to maps that provide configuration data into the configuration file syntax and how should map entries look like? One possibility way is to have a set of option combined into a group and reference that group from the map. For example, instead of using
SrvFeatures:10 l Vit would be
LocalSrvFeatures { RequestClientCertificate=No; AUTH=require; };
SrvFeatures:10 LocalSrvFeatures
The defaults of the configuration should be compiled into the binary instead of having a required configuration file which contains all default values.
Advantages:
Disadvantages:
It must be possible to query the various smX components to print their current configuration settings as well as their current status. The output should be formatted such that it can be used as a configuration file to reproduce the current configuration.
It must be possible to tell the various smX components to change their current configuration settings. This may not be practical for all possible options, but at least most of them should be changeable while the system is running. That minimizes downtime to make configuration changes, i.e., it must not be required to restart the system just to change some ``minor'' options. However, options like the size of various data structures may not be changeable ``on the fly''.
sendmail X.0.0.PreaAlpha9 has the following configuration parameters:
Various other definitions: postmaster address for double bounces2.14, log level and debug level could be more specific, i.e., per module in the code, but probably not per something external, configuration flags, time to wait for SMAR, SMTPC to be ready.
It doesn't seem to be very useful to make these dependent on something: minimum and ``ok'' free disk space (KB).
definitions (see Section 2.2.1, 2): log level and debug level (see above), heap check level, group id (numeric) for CDB, time to wait for QMGR to be ready.
run in interactive mode, serialize all accept() calls, perform one SMTP session over stdin/stdout,
socket over which to receive listen fd, specify thread limits per listening address,
create specified number of processes, bind to specified address - multiple addresses are permitted, maximum length of pending connections queue,
I/O timeout: could be per daemon and client IP address,
client IP addresses from which relaying is allowed, recipient addresses to which relaying is allowed.
All of these are definitions:
log level and debug level (see above), heap check level, time to wait for QMGR to be ready, run in interactive mode, create specified number of processes, specify thread limits.
These could be dependent on DA or even server address: socket location for LMTP, I/O timeout, connect to (server)port.
All of these are runtime options, i.e., they are specified when the binary is started (hence definitions in the sense of Section 2.2.1, 2):
log level and debug level (see above), IPv4 address for name server, DNS query timeout, use TCP for DNS queries instead of UDP, use connect(2) for UDP.
All of these are definitions: name: string (name of program/service); port: number or service entry (optional); socket.name: name of socket to listen on: path (optional); tcp: currently always tcp (could be udp); type: type of operation: nostartaccept, pass, wait; exchange_socket: socket over which fd should be passed to program; processes_min: minimum number of processes; processes_max: maximum number of processes; user: run as which user (user name, i.e., string); path: path to executable; args: arguments for execv(3) call.
MCP {
processes_min=1; processes_max=1; type=wait;
smtps {
port=25;
type=pass;
exchange_socket=smtps/smtpsfd;
user=smxs;
path="../smtps/smtps";
arguments="smtps -w 4 -d 4 -v 12 -g 262 -i -l . -L smtps/smtpsfd"; }
smtpc {
user=smxc;
path="../smtpc/smtpc";
arguments="smtpc -w 4 -P 25 -d 4 -v 12 -i -l ."; }
qmgr {
user=smxq;
path="../qmgr/qmgr";
arguments="qmgr -w 4 -W 4 -B 256 -A 512 -d 5 -v 12"; }
smar {
user=smxm;
path="../smar/smar";
arguments="smar -i 127.0.0.1 -d 3 -v 12"; }
lmtp {
socket_name="lmtpsock";
socket_perm="007";
socket_owner="root:smxc";
type=nostartaccept;
processes_min=0;
processes_max=8;
user=root;
path="/usr/local/bin/procmail";
arguments="procmail -z"; }
};
Note: some definitions could be functions (see Section 2.2.1), e.g., I/O timeout could be dependent on the IP address of the other side or the protocol, debug and log level could have similar dependencies. As explained in Section 2.2.4 the implementation restricts how ``flexible'' those values are.
Currently hostname is determined by the binary at runtime. If it is set by the configuration then it could be: global, per SMTP server, per IP address of client, per SMTP client, per IP address of server. This is one example of how an options can be set at various depths in the configuration file. Would this be a working configuration file?
Global { hostname = my.host.tld; }
Daemon SMTPS1 { Port=MTA; hostname=my2.host.tld;
IP-Client { IP-ClientAddr=127.*; hostname=local.host.tld;} }
DA SMTPC1 { hostname=out1.host.tld;
IP-Server { IP-ServerAddr=127.*; hostname=local.host.tld;}
IP-Server { IP-ServerAddr=10.*; hostname=net.host.tld;} }
The lines that list an IP address are intended to act as restrictions, i.e., if the IP address is as follows then apply this setting. Question: Is this the correct way to express that? What about more complicated expressions (see Section 2.2.6)?
In principle these are conditionals:
hostname = my.host.tld;
if (Port==MTA) { hostname=my2.host.tld;
if (IP-ClientAddr==127.*) hostname=local.host.tld; }
Question: what are the requirements for anti-spam configuration for a (pre-)alpha version of sendmail X?
Not yet available: allow relaying based on TLS.
This brings in all the subtleties from sm8, especially delay-checks. What's a simple way to express this?
The Control flow in sm8 is explained in Section 3.5.2.6.
Note: for the first version it seems to the best to use a simple configuration file without any conditionals etc. If an option is dependent on some data, then the access method from sm8 should be used. This allows us to put that data into a well known place and treat it in a matter that has been successfully used before. Configuration like anti-relaying should be ``hard-wired'' in the binary and their behavior should only be dependent on data in a map. This is similar to the mc configuration ``level'' in sm8; more control over the behavior is archievable in sm8 by writing rules which in smX may have some equivalent in modules.
The configuration files must be protected from tampering. They should be owned by root or a trusted user. sendmail must not read/use configuration files from untrusted sources, which not just means wrong owners, but also files in unsecure directories.
Some processes require root privileges to perform certain operations. Since sendmail X will not have any set-user-id root program for security reasons, those processes must be started by root. It is the task of the supervisor process (MCP: Master Control Process) to do this.
There are a few operations that usually require root privileges in a mail system:
The MCP will bind to port 25 and other ports if necessary before it starts the SMTP server daemons (see Section 2.5) such that those processes can use the sockets without requiring root access themselves.
The supervisor process will also be responsible for starting the various processes belonging to sendmail X and supervising them, i.e., deal with failures, e.g., crashes, by either restarting the failed processes or just reporting those crashes if they are fatal. The latter may happen if a system has a hardware or software failure or is (very) misconfigured. The MCP is also responsible for shutting down the entire sendmail X system on request.
The configuration file for the supervisor specifies which processes to start under which user/group IDs. It also controls the behavior in case of problems, i.e., whether they should be restarted, etc. This is fairly similar to inetd, except that the processes are not started on demand (incoming connection) but at startup and whenever a restart is necessary.
The supervisor process runs as root and hence must be carefully written (just like any other sendmail X program). Input from other sources must be carefully examined for possible security implications (configuration file, communication with other parts of the sendmail X system).
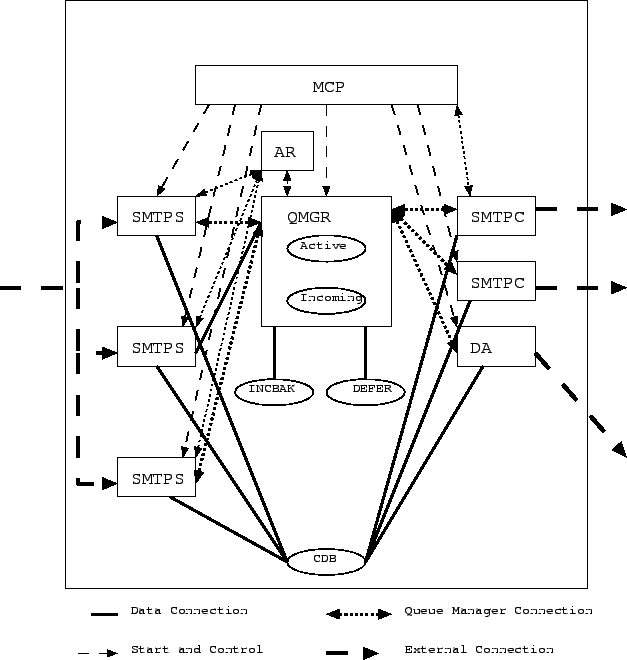
The queue manager is the central coordination instance in sendmail X. It controls the flow of e-mail throughout the system. It implements (almost) all policies and coordinates the receiving and sending processes. Since it controls several processes it is important that it will not slow them down. Hence the queue manager will be a multi-threaded program to allow for easy scalability and fast response to requests.
The queue manager will handle several queues (see Section 2.4.1); there will be at least queues for incoming mails, for scheduling delivery of mails, and for storing information about delayed mails.
The queue manager also maintains the state of the various other processes with which it communicates and which it controls, e.g., the open connections of the delivery agents. It should also have knowledge about the system to which it sends e-mails, i.e., whether they are accepting e-mails, probably the throughput of the connections, etc.
Todo: add a complete specification what the QMGR does; at least the parts that aren't related to incoming SMTP.
One proposal for a set of possible queues is:
Having several on-disk queues has the following advantages:
Disadvantages of several on-disk queues are:
Since the disadvantages outweigh the advantages the number of on-disk queues will be minimized. The deferred queue will become the main queue and contains also entries that are on hold or waiting for ETRN. Envelopes for bounces should go to the main queue too. This way the status for an envelope is available in one place (well, almost: the incoming queue may have the current status). Only the ``corrupt'' queue is different since nobody ever schedules entries from this queue and it probably needs a different format (no decision yet). To achieve the ``effect'' of having different queues it might be sufficient to build different indices to access parts of the queue (logical queues). For example, the ETRN queue index has only references to items in the queue that are waiting for an ETRN command.
The ``active'' and the ``incoming'' queues are resident in memory for fast access. The incoming queue is backed up on stable storage in a form that allows fast modifications, but may be slow to reconstruct in case the queue manager crashes. The active queue is not directly backed up on disk, other queues act as backup. That is, the active queue is a restricted size cache (RSC) of entries in other queues. The deferred queue contains items that have been removed from the active queue for various reasons, e.g., policy (deliver only on ETRN, certain times, quarantine due to milter feedback, etc), delays (temporary failures, load too high, etc), or as the result of delivery attempts (success/failure/delay). The active queue must contain the necessary information to schedule deliveries in efficient (and policy based) ways. This implies that there is not just one way to access the data (one key), but several to accommodate different needs. For example, it might be useful to MX-piggyback deliveries, which requires to store (valid, i.e., not-expired) MX records together with recipient domains. Another example is a list of recipients that wait for a host to be able to receive mail again, i.e., a DB which is keyed on hosts (IP addresses or names?) and the data is a list of recipients for those hosts.
Normally entries in the incoming queue are moved into the deferred queue only after a delivery attempt, i.e., via the active queue. However, the active queue itself is not backed up on persistent storage. Hence an envelope must be either in the incoming queue or in the deferred queue at any given time (unless it has been completely delivered). Moving an entry into the deferred queue must be done safely, i.e., the envelope must be safely in the deferred queue before it is removed from the incoming queue. Question: When do we move the sender data over from the incoming to the deferred queue? Do we do it as soon as one recipient has been tried or only after all have been tried? Since we are supposed to try delivery as soon as we have the mail, we probably should move the sender data after we tried all recipients. ``Trying'' means here: figure out a DA, check flags/status (whether to try delivery at all, what's the status of the system to which the mail should be delivered), if normal delivery: schedule it, otherwise move to the deferred queue.
The in-memory queues are limited in size. These sizes are specified in the configuration file. It is not yet clear which form these specifications may have: amount of memory, amount of entries, percentage of total memory that can be used by sendmail X or specific processes. The specification should include percentages at which the behavior of the queue manager changes, esp. for the incoming queue. If the incoming queue becomes almost full the acceptance of messages must be throttled. This can be done in several stages: just slow down, reduce the number of concurrent incoming connections (just accept them slower), and in the extreme the SMTP server daemons will reject connections. Similarly the mail acceptance must be slowed down if the active queue is about to overflow. Even though the queue manager will normally favor incoming mail over other (e.g., deferred) mail, it must not be possible to starve those other queues. The size of the active queue does not need to be a direct feedback mechanism to the SMTP daemon, it is sufficient if this is happening indirectly through the incoming queue (which will fill up if items can't be moved fast enough into the active queue). However, this may not be intended, maybe we want to accept messages for some limited time faster than we can send them.
It might be nice for the in-memory queues to vary in size during runtime. In high-load situation those queues may grow up to some maximum, but during lower utilization they should shrink again. Maximum and minimum sizes should be user-configurable. However, in general the OS (VM system) should solve the problem for us.
Here's the list of queues that are currently used:
One proposal for a set of possible queues is:
There's currently no decision about the queue for corrupted entries.
The incoming queue must be backed up on stable storage to ensure reliability. The most likely implementation right now is a logfile, in which entries are simply appended since this is the fastest method to store data on disk. This is similar to a log-structured filesystem and we should take a look at the appropriate code. However, our requirements are simpler, we don't need a full filesystem, but only one file type with limited access methods. There must be a cleanup task that removes entries from the backup of the incoming queue when they have been taken care of. For maximum I/O throughput, it might be useful to specify several logfiles on different disks.
The other queues require different formats. The items on hold are only released on request (e.g., for ETRN). Hence they must be organized in a way that allows easy access per domain (the ETRN argument) or other criteria, e.g., a hold message for quarantined entries.
The delayed queue contains items that could not be delivered before due to temporary errors. These are accessed in at least two ways:
The queue manager needs to keep a reference count for an envelope to decide when an entry can be removed. This may become non-trivial in case of aliases (expansion). If the LDA does alias expansion then one question is whether it injects a new mail (envelope) with a new body. Otherwise reference counting must take care of this too.
The MAIL (sender) data, which includes the reference counter, is stored in the deferred queue if necessary, i.e., as long as there are any recipients left (reference count greater than zero). Hence we must have a fast way to access the sender data by transaction id. At any time the envelope sender information must be either in the incoming queue or in the deferred queue.
Problem: mailing lists require to create new envelope sender addresses, i.e., the list owner will be the sender for those mails. An e-mail can be addressed to several mailing lists and to ``normal'' recipients, hence this may require to generate several different mail sender entries. Question: should the reference counter only be in the original sender entry and the newly created entries have references to that? Distributing the reference count is complicated. However, this may mean that a mail sender entry stays around even though all of its (primary) recipients have been taken care of.
It might be necessary to have a garbage collection task: if the system crashes during an update of a reference counter the value might become incorrect. We must assure that the value is never too small, because we could remove data that is still needed. If the stored value is bigger than it should be, the garbage collection task must deal with this (compare fsck for file systems).
Envelopes received by the SMTP servers are put into the incoming queue and backed up on disk. If an envelope has been completely received, the data is copied into the active queue unless that queue is full2.16. Entries in the active queue are scheduled for delivery. If delivery attempts are done, the results of those attempts are written to the incoming queue (mark it as delivered) or deferred queue as necessary. Entries from the deferred queue are copied into the active queue based on their ``next time to try'' time stamp.
It would be nice to define some terms for
A delivery attempt consists of:
This section explains how data is added to the various queues, what happens with it, and under which circumstances data is read from a queue if there is no queue into which the data is read, i.e., this is a consumer oriented view.
This section gives a bit more details about the data flow than the previous section. It does only deal with data that is stored by QMGR in some queue, it does not specify the complete data flow, i.e., what happens in the SMTP server or the delivery agents.
Question: should we keep entries in the incoming queue only during delivery attempts, or should we move the envelope data into the deferred queue while the attempts are going on? If we move the envelopes, we have more space available in the incoming queue and can accept more mail. However, moving envelopes costs of course performance. In the ``normal'' case we don't need the envelope data in the deferred queue, i.e., if delivery succeeds for all recipients and no SUCCESS DSNs are requested, we don't need the envelope data ever in the deferred queue. Question: do we want a flexible algorithm that moves the envelope data only under certain conditions? Those conditions could include how much space is free in the incoming queue and how long an entry is already in the queue. There should be two different modes (selectable by an option):
We need the envelope data in the deferred queue, if and only if
If no DSN must be sent and all recipients have been taken care of, the envelope does not need to be moved into the DEFEDB, and it can be removed from the INCEDB afterwards without causing additional data moving.
Note: it should be possible to remove recipient and transaction data from IQDB as soon as it has been transferred to AQ and safely committed to IBDB; at this moment the data is in persistent storage and it is available to the scheduler, hence the data is not really needed anymore in IQDB. There are some implementations issues around this2.19, hence it is not done in the current version, this is something that should be optimized in a subsequent version.
When a delivery attempt (see 4d in Section 2.4.3.2) has been made, the recipient must be taken care of in the appropriate way. Note that a delivery attempt may fail in different stages (see Section 2.4.3.1), and hence updating the status of a recipient can be done from different parts of QMGR. That is, in all cases the recipient address is removed from ACTEDB and
The data is stored in DEFEDB (persistent storage) to avoid retrying a failed delivery, see also Section 2.4.6.
Notice: it is recommended to perform the update for a delivery attempt in one (DB) transaction to minimize the amount of I/O and to maintain consistency. Furthermore, the updates to DEFEDB should be made before updates to INCEDB are made as explained in Section 2.4.1.
Note: this section does not discuss how to deal with a transaction whose recipients are spread out over INCEDB and DEFEDB. For example, consider a transaction with two recipients, all data is in INCEDB. A delivery attempt for one recipient causes a temporary failure, the other recipient is not tried yet. Now the transaction and the failed recipient are written to DEFEDB. However, the recipient counters in the transaction do not properly reflect the number of recipients in DEFEDB but in both queues together. The recovery program must be able to deal with that.
According to item 10 in Section 2.4.3.3 entries are read from the deferred queue into the active queue based on their ``next time to try'' (or whatever criteria the scheduler wants to apply). Instead of reading through the entire DB -- which is on disk and hence expensive disk I/O is involved -- each time entries should be added, an in-memory cache (EDBC) is maintained which contains references to entries in DEFEDB sorted based on the ``next time to try''. Note: it might be interesting to investigate whether an DEFEDB implementation based on Berkeley DB would make this optimization superfluous because Berkeley DB maintains a cache anyway. However, it is not clear which data the cache contains, most likely it is not ``next time to try'' but only the key (recipient/transaction identifiers).
Even though each entry in the cache is fairly small (recipient identifier, next time to try, and some management overhead), it might be impossible to hold all references in memory because of the size. Here is a simple size estimation: an entry is about 40 bytes, hence 1 million entries require 40 MB. If a machine actually has 1 million entries in its deferred queue then it has most likely more than 1 GB RAM. Hence it seems fairly unlikely to exceed the available memory with EDBC. Nevertheless, the system must be prepared to deal with such a resource shortage. This can be done by changing into a different mode in which DEFEDB is regularly scanned and entries are inserted to EDBC such that older entries will be removed if newer entries are inserted and EDBC is full2.20.
If the MTS is busy it might not be possible to read all entries from DEFEDB when their next time to try is actually reached because AQ might be full. Hence it is necessary to establish some fairness between the two producers for AQ: IQDB (SMTP servers) and DEFEDB. A very simple approach is to reserve a certain amount, e.g., half, for each of the producers. However, that does not seem to be useful:
A slightly better approach is as follows:
This approach will
sendmail 8 provides a delivery mode called interactive in which a mail is delivered before the server acknowledges the final dot. An enhanced version of this could be implemented in sendmail X, i.e., try immediate delivery but enforce a timeout after which the final dot is acknowledged. A timeout is necessary because otherwise clients run into a timeout themselves and resend the mail which will usually result in double deliveries.
This mode is useful to avoid expensive disk I/O operations; in a simple mode at least the fsync(2) call can be avoided, in a more complicated mode the message body could be shared directly between SMTP server and delivery agent to even avoid creation of file on disk (this could be accomplished by using the buffered file mode from sendmail 8 with large buffers, however, this requires some form of memory sharing2.21). Various factors can be used to decide whether to use interactive delivery, e.g., the size of the mails, the number of recipients and their destinations, e.g., local versus remote, or other information that the scheduler has about the recipient hosts, e.g., whether they are currently unavailable etc.
Cut-through delivery requires a more complicated protocol between QMGR and SMTP server. In normal mode the SMTP server calls fsync(2) before giving the information about the mail to QMGR and then waits for a reply which in turn is used to inform the SMTP client about the status of the mail, i.e., the reply to the final dot. For cut-through delivery the SMTP server does not call fsync(2) but informs QMGR about the mail. Then the following cases can happen:
For case 1b the SMTP server needs to send another message to QMGR telling it the result of fsync(2). If fsync(2) fails, the message must be rejected with a temporary error, however, QMGR may already have delivered the mail to some recipients, hence causing double deliveries.
Items from the delayed queue need to be read into the active queue based on different criteria, e.g., time in queue, time since last attempt, precedence, random walk.
The queue manager must establish a fair selection of items in the incoming queue and items in the delayed queue. This algorithm can be influenced by user settings, which includes simple options (compare QueueSortOrder in sendmail 8), table driven decisions, e.g., no more than N connections to a given host, and a priority (see Section 2.4.4.1). A simple way to achieve a fair selection is to establish a ratio (that can be configured) between the queues from which entries are read into the active queue, e.g., incoming: 5, deferred: 1. Question: do we use a fixed ratio between incoming and deferred queue or do we vary that ratio according to certain (yet to determine) conditions? These ratios are only honored if the system is under heavy load, otherwise it will try to get as many entries into the active queue as possible (to keep the delivery agents busy). However, the scheduler will usually not read entries from the deferred queue whose next time to try isn't yet reached, unless there is a specific reason to do so. Such a reason might be that a connection to the destination site became available, an ETRN command has been given, or deliver is forced by an admin via a control command. Question: does the ratio refer to the number of recipients or the number of envelopes?
The QMGR must at least ensure that mail from one envelope to the same destination site is send in one transaction (unless the number of recipients per message is exceeded). Hence there should be a simple way to access the recipients of one envelope, maybe the envelope id is a key for the access to the main queue. See also 2.4.4.4 for further discussion. Additionally MX piggybacking (as in 8.12) should be implemented to minimize the required number of transactions.
Question: how to schedule deliveries, how to manage the active queue? Scheduling: Deliveries are scheduled only from the active queue, entries are added to this queue from the incoming queue and from the deferred queue.
To reduce disk I/O the active queue has two thresholds: the maximum size and a low watermark. Only if too few entries are in the cache entries are read from the deferred queue. Problem: entries from the incoming queue should be moved as fast as possible into the active queue. To avoid starvation of deferred entries a fair selection must be made, but this must be done on a ``large'' scale to minimize disk I/O. That is, if the ratio is 2-1 (at least one entry from the deferred queue for every two from the incoming queue), then it could be that 100 entries are moved from the incoming queue, and then 50 from the deferred queue. Of course the algorithm must be able to deal with border conditions, e.g., very few incoming entries but large deferred queue, or only a few entries trickling in such that the number of entries in the active queue is always in the range of the low watermark.
Question: where/when do we ask the address resolver for the delivery tuple? That's probably a configuration option. The incoming queue must be able to store addresses in external and in ``resolved'' form. See also Section 3.12.6 for possible problems when using the resolved form.
Here's a list of scheduling options people (may) want (there are certainly many more):
Question: how to specify such scheduling options and how to do that in an efficient way? It doesn't make much sense to evaluate a complicated expression each time the QMGR looks for an item in the deferred queue to schedule for delivery. For example, if an entry should only be sent at certain times, then this should be ``immediately'' recognizable (and the item can be skipped most of the time, similar to entries on hold).
Remark: qmail-1.03/THOUGHTS [Ber98] contains this paragraph:
Mathematical amusement: The optimal retry schedule is essentially, though not exactly, independent of the actual distribution of message delay times. What really matters is how much cost you assign to retries and to particular increases in latency. qmail's current quadratic retry schedule says that an hour-long delay in a day-old message is worth the same as a ten-minute delay in an hour-old message; this doesn't seem so unreasonable.
Remark: Exim [Haz01] seems to offer a quite flexible retry time calculcation:
For example, it is possible to specify a rule such as `retry every 15 minutes for 2 hours; then increase the interval between retries by a factor of 1.5 each time until 8 hours have passed; then retry every 8 hours until 4 days have passed; then give up'. The times are measured from when the address first failed, so, for example, if a host has been down for two days, new messages will immediately go on to the 8-hour retry schedule.
Courier-MTA has four variables to specify retries:
,
,
,
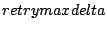
These control files specify the schedule with which Courier tries to deliver each message that has a temporary, transient, delivery failure.
Courier will first makeamount of time before another
amount of time long, the next one
, and so on.
amount of time before making
The default values are:
This results in Courier delivering each message according to the following schedule, in minutes: 5, 5, 5, 15, 5, 5, 30, 5, 5, 60, 5, 5, then repeating 120, 5, 5, until the message expires.
There are two levels of scheduling:
We could assign each entry a priority that is dynamically computed. For example, the priority could incorporate:
However, it is questionable whether we can devise a formula
that generates the right priority.
How do we have to weight those parameters (linear functions?),
and how to combine them (
![]() )?
It might be simpler (better) to specify the priority in some
logical formula (if-then-else) in combination with arithmetic.
Of course we could use just arithmetic (really?) if we use the
right operations.
However, we want to be able to short-cut the computation,
e.g., if one parameter specifies that the entry certainly will
not be scheduled now.
For example:
if time-next-try
)?
It might be simpler (better) to specify the priority in some
logical formula (if-then-else) in combination with arithmetic.
Of course we could use just arithmetic (really?) if we use the
right operations.
However, we want to be able to short-cut the computation,
e.g., if one parameter specifies that the entry certainly will
not be scheduled now.
For example:
if time-next-try ![]() now then Not-Now unless
connections-open(recipient-site)
now then Not-Now unless
connections-open(recipient-site) ![]() .
.
On system with low mail volume the schedulers will not be busy all the time. Hence they should sleep for a certain time (in sendmail 8 that's the -q parameter). However, it must be possible to wake them up whenever necessary. For example, when a new mail comes in the first level scheduler should be notified of that event such that is can immediately put that mail into the active queue if that is possible, i.e., there is enough free space. The sleep time might be a configurable option, but it should also be possible to just say: wake up at the next retry time, which is the minimum of the retry times in the deferred queue.
The next retry time should not be computed based on the message/recipient, but on the destination site (Exim does that). It doesn't make much sense to contact a site that is down at random intervals because different messages are addressed to it. Since the status of a destination site is stored in the connection cache, we can use that to determine the next retry time. However, we have the usual problem here: a recipient specifies an e-mail address, not the actual host to contact. The latter is determined by the address resolver, and in general, it's not a single host, but a list of hosts. In theory, we could base the retry time on the first host in the list. However, what should we do if another host in the list has a different next retry time, esp. an earlier one? Should we use the minimum of all retry times? We would still have to try the hosts in order (as required by the standard), but since a lower priority host may be reachable, we can deliver the mail to it. Question: under which circumstance can a host in the list have an earlier retry time? This can only happen if the list changes and a new host is added to it (because of DNS changes or routing changes). In that case, we could set the retry time for the new host to the same time as all the other hosts in the list. However, this isn't ``fair'', it would penalize all mails to that host. So maybe it is best to use the retry time of the first host in the list as the retry time of a message.
Note: There are benefits to some randomness in the scheduling. For example, if some systematic problem knocks down a site every 3 hours, taking 15 minutes to restore itself, then delivery attempts should not accidentally synchronize with the periodic failures. Hence adding some ``fuzz'' factor might be useful.
Notice: it might be useful to have a pre-emptive scheduler. That is, even if the active queue is full, there might be reasons to remove entries from it and replace them with higher priority entries from the incoming queue. For example, the active queue may be filled with a lots of entries from a mailing list and new mail is coming in. If the delivery is slow, then some of those new entries may replace entries in the active queue that aren't actually given to a delivery agent. Theoretically, this could be handled by priorities too.
Whenever there is sufficient free space (number of entries falls below low watermark), then the first level scheduler must put some entries from the incoming and the deferred queue into the active queue.
Problem: we have to avoid using up all delivery agents (all allowed connections) for one big e-mail, e.g., an e-mail to a mailing list with thousands of recipients. Even if we take the number of recipients into account for the priority calculation, we don't want to put all recipients behind other mails with fewer recipients (do we?). This is just another example how complicated it is to properly calculate the priority. Moreover, expansion of an alias to a large list must be done such that it doesn't overflow the incoming queue. That is: where do we put those expanded addresses? We could schedule some entries immediately and put others into the deferred queue (which doesn't have strict size restrictions).
Entries from the incoming queue are placed into the active queue in FIFO order in most cases.
Question: do we put an entry from the incoming queue into the active queue even though we know the destination is unavailable or do we move it in such a case directly to the deferred queue? We could add some kind of probability and a time range to the configuration (maybe even per host). Get a random number between 0 and 100 and check it against the specified probability. If it is lower try the connection anyway. Another way (combinable?) is to specify a time range (absolute or as percentage) and check whether the next time to try is within this range.
Whenever new entries are added to the active queue, a ``micro scheduler'' arranges those in an appropriate order. Question: how to do micro scheduling within the active queue?
Question: do we treat the active queue strictly as queue? Probably not because we want to reuse open connections (as much as allowed by the configuration). So if we have an open connection and we move an entry ``up front'' to reuse the connection, how do we avoid to let other entries ``lie around'' forever in the queue? We could add a penalty to this connection (priority calculcation), such that after some usages the priority becomes too bad and hence entries can't leapfrog others anymore. The problem is still the same: how to properly calculate the priority without causing instabilities? Courier moves the oldest entry (from the tail) to the head of the queue in such a case to prevent starvation. Question: does this really prevent starvation or is it still possible that some entries may stay in the queue forever?
The second level scheduler must be able to preempt entries in the queue. This is required at least for entries that are supposed to be sent to a destination which turns out to be unavailable after the entry has been placed in the active queue. This can happen if an ``earlier'' entry has the same destination and that delivery attempt fails. Then all entries for the same destination will be removed from active queue. In such a case, they will be marked as deferred (assuming it was a temporary delivery failure). Notice: this is complicated due to the possibility of multiple destination sites, so all of them have to be unavailable for this to happen. It may also be useful to just remove entries from the active queue based on request by the first level scheduler. Question: how can this be properly coordinated?
As described in Section 2.4.4 the scheduler should at least ensure that mail from one envelope to the same destination site is sent in one transaction (unless the number of recipients per message is exceeded). However, this isn't as trivial to achieve as it seems on first sight. If MX piggybacking is supposed to implemented then all addresses of one envelope must be resolved first before any delivery is scheduled. This may reduce throughput since otherwise delivery attempts can be made as soon as a recipient address is available. If those recipient addresses would be for different destinations then starting delivery as soon as possible is more efficient (assuming the system has not yet reached its capacity). If the recipient addresses are for the same destination then putting them into one transaction will at least reduce the required bandwidth (and depending on the disk I/O system and its buffer implementation maybe also the number of disk I/O operations). Recipient coalescing based on the domain parts is easier to implement since it can be done before addresses are resolved; it still requires walking through the entire recipient list of course (some optimized access structure, e.g., a tree with sublists, could be implemented). Depending on when addresses are resolved and where they are stored, MX piggybacking may be as easily to achieve, i.e., if the resolved addresses are directly available.
Entries must not stay in the AQ for unlimited time (see Section 2.4.3.2, item 4e) hence some kind of timeout must be enforced. There are two situations in which timeouts can occur:
The queue manager keeps a connection cache that records the number of open connections, the last time of a connection attempt, the status (failure?), etc. For details, see Section 3.4.10.10. Question: if the retry time for a host isn't reached, should an incoming message go directly into the deferred queue instead of being tried? That might be a configuration option. See also 2.4.4.2.2.
For SMTP clients, mail might have multiple possible destinations due to the use of MX records. The basic idea is to provide a metric of hosts that are ``nearer'' to the final delivery host (where usually local delivery occurs). A SMTP client must try those hosts in order of their preference ``until a delivery attempt succeeds''2.22. However, this description is at least misleading, because it seems to imply that if mail delivery fails other destinations hosts should (MUST) still be tried, which is obviously wrong. So the question is: when should a SMTP client (or in this case, the QMGR) stop trying other hosts? One simple reason to stop is of course when delivery succeeded. But what about all the other cases (see Section 3.8.4.1)? qmail stops trying other hosts as soon as a connection succeeded, which is probably not a good idea since the SMTP server may greet with a temporary error or cause temporary errors during a transaction.
The QMGR should maintain the following data structures (``connection caches'', ``connection databases'') to help the scheduler making its decisions:
The last structure (3: AQRD) is just one way to access recipients in AQ, in this case via the DA and the next hop (``destination''). It can be used to access recipients that are to be sent to some destination, e.g., to reuse an open connection. All recipients that have the same destination are linked together.
OCC (1) keeps track of the currently open connections and how busy they are as well as the current ``load'', i.e., the number of open sessions/transactions per destination. This can be used to implement things like slow-start (see 2.4.7) and overall connection limits. Note: these limits should not be implemented per DA, but for the complete MTS. Question: should there be only (global) one open connection cache, not one each per DA?
DCC (2) keeps track of previously made/tried connections (not those that are currently open), it can be compared to the hoststatus cache of sendmail 8. This can be used by the scheduler to decide whether trying to connect to hosts at all, e.g., because they are down for some time already.
All three structures are basically accessed via the same key (DA plus next hop); the structures AQRD (3) and OCC (1) keep an accurate state, while DCC (2) might be implemented in a way that some information is lost in order to keep the size reasonable (it is not feasible to keep track of all connections that have ever been made, nor is it reasonable to keep track of all connections for a certain amount of time if that interval is too large, see 3.4.10.10 for a proposal).
Question: is it useful to merge AQRD (3) and OCC (1) together because they basically provide two parts of a bigger picture (and hence merging them avoids having to update and maintain them separately, e.g., memory (de-)allocation and lookups are done twice for each update). However, keeping them separate seems cleaner from a software design standpoint: AQRD is ``just'' one way to access entry in AQ, while OCC is an overview of the current state of all delivery agents.
There are (at least) two more access methods that are useful for the scheduler:
It might be useful to organize recipients that are waiting for an AR or DA result into a list which is sorted according to their potential timeout.
The administrator should have the chance the trigger a delivery attempt or complete queue runs manually. For example, if the admin notices that a site or a network connection is up again after a problem, she should be able to inform the scheduler about this change, see also Section 2.11.1.2.
According to RFC 1894 five types of DSNs are possible:
Using the terms ``mailing list'' and ``alias'' as defined in RFC 2821 [Kle01], section 3.10.1 and 3.10.2: An action-value of ``expanded'' is only to be used when the message is delivered to a multiple-recipient ``alias''. An action-value of ``expanded'' should not be used with a DSN issued on delivery of a message to a ``mailing list''.
The queue manager collects the delivery status informations from the various delivery agents (temporary and permanent failures). Based on the requested delivery status notifications (delay, failure, success), it puts this information together and generates a DSN as appropriate. DSNs are added to the appropriate queue and scheduled for delivery.
Question: how to coalesce DSNs? We don't want to send a DSN for each (failed) recipient back to the sender individually. After each recipient has been tried at least once (see also 3.4.10.6) we can send an initial DSN (if requested) which includes the failed recipients (default setting). Do we need to impose a time limit after which a DSN should be sent even if not all recipients have been tried yet? Assuming that our basic queue manager policy causes all recipients to be tried more or less immediately, we probably don't need to do this. Recipients would not be tried if the policy says so (hold/quarantine), or if the destination host is known to be down and the retry time for each hasn't been reached yet. In these cases those recipients would be considered ``tried'' for the purpose of a DSN (they are delayed). After the basic warning timeout (either local policy or due to deliver-by) a DSN for the delayed recipients is sent if requested. This still leaves open when to send DSNs for failed recipients during later queue runs. Since the queue manager doesn't schedule deliveries per envelope but per recipient, we need to establish some policy when to send other DSNs. Todo: take a look at other MTAs (postfix) how they handle this. Note: RFC 1891, 6.2.8 DSNs describing delivery to multiple recipients: a single DSN may describe attempts to deliver a message to multiple recipients of that message. Hence the RFC allows to send several DSNs, it doesn't require coalescing.
Notice: it is especially annoying to get several DSNs for the same message if the full message is returned each time. However, it would probably violate the RFCs to return the entire mail only once (which could be fairly easily accomplished). BTW: the RET parameter only applies to ``failed'' DSNs, for others only headers should be returned (RFC 1891, 5.3).
Additional problem: different timeouts for warnings. It is most likely possible to assign different timeouts for DELAY DSNs to different recipients within a single mail. In that case the algorithm to coalesce DELAY DSNs will be even more complicated, i.e., it can't be a simpler counter whether all recipients have been tried already.
Question: where do we store the data for the DSN? Do we store it in the queue and generate the DSN body ``on the fly'' or do we create a body in the CDB? Current vote is for the former.
A MTA must be able to distinguish between different types of recipient addresses:
Note: RFC 1891, 6.2.7.4 explains confidential forwarding addresses which should be somehow implemented in sendmail X.
It doesn't seem to be easy to maintain this data. First of all, the types are only known after address expansion. Even then, they may not be complete because a LDA may perform further alias expansion. Question: must the sum of these counters be the same as the number of original recipients? That is, ``all'' we have to do is to classify the original recipients into those three cases and then keep track of them? Answer: no. DSNs can be requested individually for each recipient. Hence the question should be: must the sum of these counters be less than or equal the number of original recipients?
The main problem is how to deal with address expansions, i.e., addresses that resolve (via aliases) to others. RFC 1891 lists the following cases:
user "|/usr/bin/vacation user"
If DSNs are implemented properly the sender can determine herself whether she wants the full body or just the headers of her e-mail returned in a DSN. sendmail 8 has a configuration option to not return the body of an e-mail in a bounce (to save bandwidth etc). In addition to that, it might be useful to have a configuration option to return the body only in the first bounce but not in subsequent DSNs (see Section 2.4.6 about the problem to send only one DSN). So at least two options are necessary:
These options need to be combined with the DSN requests such that the ``minimum'' is returned, e.g., if option 2 is selected but the sender requests only headers, then only the headers are sent.
There are two aspects of load control:
Some of the measures can be applied to both cases (local/remote load, incoming/outgoing connections).
The queue manager must control local resource usage, by default it should favor mail delivery over incoming mail. To achieve this, the queue manager needs to keep the state of the entire system or at least it must be able to gather the relevant data from the involved sendmail X programs and the OS. This data must be sufficient to make good decisions how to deal with an overload situation. Local resources are:
Therefore the system state (resource usage) should include:
The queue manager must be able to limit number of messages/resources devoted to a single site. This applies to incoming connections as well as to outgoing connections. It must also be possible to allow all the time connections from certain hosts/domains, e.g., localhost for submissions. This can be a fixed number or a percentage of the total number of connections or the maximum of both.
The queue manager must assure that the delivery agents do not overload a single site. It should have an adaptive algorithm to use ``optimal'' number of connections to a single site, these must be within specified limits (lower/upper bound) for site/overall connections. Question: how can the QMGR determine the ``optimal'' number of connections? By measuring the throughput or latency? Will the overhead for measurements kill the potential gain? Proposal: Check whether the aggregate bandwidth increases with a new connection, or if it stays flat. If connections are refused: back off.
The queue manager may use a ``slow start'' algorithm (TCP/IP, postfix) which gradually increases the number of simultaneous connections to the same site as long as delivery succeeds, and gradually decreases the number of connections if delivery fails.
Idea (probably not particularly good): use ``rate control'': don't just check how full the INCEDB is, but also the rate of incoming and ``leaving'' mails. Problem: how to count those? Possible solution: keep the numbers over certain intervals (5s), count envelopes (not recipients, deal with envelope splitting). If the incoming rate is higher than the departure rate and a certain percentage (threshold) is reached: slow down mail reception. If the leaving rate is higher than the incoming rate, the threshold (usage of INCEDB) could be increased. However, since more data is removed than added, the higher threshold shouldn't be reached at all. This can only be useful if we have different thresholds, e.g., slow down a bit, slow down more, stop, and we want to dynamically change them based on the rates of incoming and outgoing messages.
All parts of sendmail X, esp. the queue manager, must be able to deal with local resource exhaustion, see also Section 2.15.7.
The queue manager must implement proper policies to ensure that sendmail X is resistant against denial of service attacks. Even though this can't be completely achieved (at least not against distributed denial of service attacks), there are some measure that can be taken. One of those is to impose restrictions on the number of connections a site can make. This applies not only to the currently open connections, but also to those over certains time intervals. For this purpose appropriate connection data must be cached, see Section 3.12.8.
Todo: structure the following items.
The queue manager does not need any special privileges. It will run as an unprivileged user.
The communication channels between the various modules (esp. between the QMGR and other modules) must be protected. Even if they are compromised, the worst that is allowed to happen is a local denial of service attack and the loss of e-mail. Getting write access to the communication channel must not result in enhanced privileges. It might sound bad enough that compromising the communicaton channels may cause the loss of e-mail, but consider that an attacker with write access to the mail queue directory may accomplish the same by just removing queued mail. There is one possible way to protect the communication even if an attacker can get write access to them: by using cryptography, i.e., an authenticated and encrypted communication channel (e.g., TLS). However, this is most likely not worth the overhead. It could be considered if the communication is done over otherwise unsecured channels, e.g., a network.
There are several alternatives how to implement an SMTP server daemon. However, before we take a look at those, some initial remarks. We have to distinguish between the process(es) that listen(s) for incoming connections (on port 25 by default, in the following we will only write ``port 25'' instead of ``all specified ports'') and those processes that actually deal with an SMTP session. We call the former SMTP listener and the latter SMTP server, while SMTP server daemon is used for both of them. It might be that listeners and servers are different processes (passing open file descriptors from the listener to the server) or the same.
Interesting references about the architecture of internet servers are: [Keg01] for WWW server models and evaluations, [SV96c], [SV96a], and [SV96b] for some comparisons between C, C++, and CORBA for various server models, and [SGI01] for one particular thread model esp. designed for internet server/client applications. Papers about support of multi-threading by the kernel and in libraries are [ABLL92], [NGP02], [Dre02], and [Sol02].
An internet server application (ISA) reads data from a network, performs some actions based on it, and sends answer(s) back. The interesting case is when the ISA has to serve many connections concurrently. Each connection requires a certain amount of state. This state consists at least of:
There is a certain amount of hardware concurrency that must be efficiently used: processors (CPU, I/O), asynchronously operating devices, e.g., SCSI (send a command, do something else, get result) and network I/O. There should be one process per CPU assuming the process is runnable all the time (or it invokes a system call that executes without giving up the CPU for the duration of the call); if the process can block then more processes are required to keep the CPU busy. We need to have always one thread of execution that is runnable. Unix provides preemptive, timesliced multitasking, which might not the best scheduling mechanism for ISA purposes. Assuming that context switches are (more or less) expensive, we want to minimize them. This can be achived by ``cooperative'' multitasking, i.e., context switches occur only when one thread of execution (may) block. Notice: this requires that no thread executes too long such that other threads may starve. This will be a problem if a thread executes a long (compute-intensive) code sequence, e.g., generation of an RSA key. Question: how can we avoid this problem? Maybe use preemptive multitasking, but make the timeslice long enough? As long as each thread only performs a small amount of work, it is better to let it executes its entire work up to a blocking function to minimize the context switch overhead. Question: can we influence the scheduling algorithm for threads? POSIX threads allow for different scheduling algorithms, but most OS implement only one (timesliced, priority based scheduling).
An ISA should answer I/O requests as fast as possible since that allows clients (which are waiting for an answer) to proceed. Hence threads that are able to answer a request should have priority. However, a thread that performs a long computation must proceed too, otherwise its client may time out. So we have a ``classic'' scheduling problem. Question: do we want to get into these low-level problems or leave it to the OS?
The alternatives to implement SMTP server daemons are at least:
Disadvantage: threads require very careful programming, the program must never crash, even if running out of memory or "fatal" errors in one of the threads (connections). Only that connection must be aborted and the problem must be logged.
Advantages: "crash resistent" (if one thread goes down, it can take down only one process). The probably most important part of this solution is: it doesn't bind us to any particular model which may show deficiencies on a particular OS, configuration, or even in the long run of further OS development. We can easily tune the usage of processes and threads based on the OS requirements/restrictions. It is the most flexible (and most complicated) model, with which we can get around limitations in different OSs.
Disadvantages: pretty complicated. Selecting this model shouldn't be necessary for crash resistence since we don't have plugins that could easily kill smtpd, but we use external libraries (Cyrus SASL, OpenSSL). It requires extra efforts to share data since we have multiple processes.
Todo: we have to figure out which of those models works best. A comparison [RB01] between 4a, 4b, and one process per connection clearly points to 4b. However, the tests listed in that article are not really representable for SMTP because no messages have been sent. Moreover, it misses model 5. Even though there might be some data available about the performance of different models, most of those probably apply to HTTP servers (Apache) or caches (Squid). These are not really representative for SMTP because HTTP/1.0 is only one request/one response exchange where the response is often pretty short. SMTP uses several exchanges (some of which can be pipelined) and often transports larger data. HTTP/1.1 can be used to keep a connection open (multiple requests and answers) and might be better comparable in its requirements to SMTP. Question: is there performance data available for this? How about FTP (larger data transports, but often only one request)?
Notice: slow connections must be taken into account too. Those connections have very little (I/O, computational) requirements per time slice, but they take up as much context data as fast connections. It should be tried to minimize any additional data, e.g., process contexts, for these connections. If we for example use one thread per connection, then slow connections will take up an entire thread context, but rarely use it. A worker thread model reduces this overhead.
We need some basic prototypes to do comparisons, esp. on different OS to find out whether threading really achieves high performance (probably on Solaris, less likely on *BSD).
Question: if we choose 5 (current favorite), how do we handle incoming connections? Do we have a single process listen on port 25 and handing over the socket to another process (3.15.15)? This may create a bottleneck. Alternative: similar to postfix have multiple processes do a select() on the port. One of them will get the connection. Possible problem(s):
Question: how much data sharing do we need in SMTPS? We need to know the number of open connections (overall, per host) and the current resource usage. It might be sufficient to have this only in the listener process (if we decide to go for only one) or it can be in the queue manager (which implements general policy and has data about past connections too). Another shared resource is the CDB which may require shared data (locking). If the transaction and session ids are not generated by the queue manager, then these require some form of syncronization too. In the simplest form, the process id might be used to generate unique ids (the MCP may be able to provide ids instead if process ids will not be useful for this purpose because they may be reused too fast).
A SMTP session may consist of several SMTP transactions. The SMTP server uses data structures that closely follow this model, i.e., a session context and a transaction context. A session context contains (a pointer to) a transaction context, which in turn points back to the session context. The data is stored by the queue manager. The transaction context ``inherits'' its environment from the session context. The session context may be a child of a server daemon context that provides general configuration information. The session context contains for example information about the sending host (the client) and possibly active security and authentication layers.
Todo: describe a complete transaction here including the interaction with other components, esp. queue manager.
The basic control flow of an incoming SMTP connection has already been described in Section 2.1.5.
The whole command is passed to the QMGR which stores the relevant data in the incoming queue. Questions: whole or only relevant parts? Are there irrelevant parts? Do we send the original text or a decoded version? A decoded version seems better to avoid double work.
Notice: the server must check whether the first line it reads is a header line. If it isn't, it must put a blank line after its Received: header as a separator between header and body. If the first line starts with a white space character (LWSP), then a blank must be inserted too. This should be covered by the ``is a header'' check because a header can't start with LWSP (it would be folded into the previous line).
Other commands (like NOOP, HELP, etc) can be treated fairly simple and are not (yet) described here.
Question: who removes entries from the CDB? Why should it be the SMTP server? The idea from the original paper was to avoid lockings overhead since the SMTP server is the only one which has write access to the CDB. Note: if we use multiple SMTP server processes then we may run into locking issues nevertheless. The QMGR controls the envelope databases which contain the reference counters for messages. Hence it is the logical place to issue the removal command. However, it's still not completely clear which part of sendmail X actually performs the removal.
Misc:
Questions: which storage format should be used? Most likely: network format (CR LF, dot-stuffed). What about BDAT handling?
The SMTP server must provide similar anti-spam checks as sendmail 8 does. However, it must be more flexible. Currently it is very complicated to change the order in which things are tested. This causes problems in various situations. For example, before 8.12 it could have been that relaying has been denied due to temporary failures even though the mail could have gone through. This was due to the fixed order in which the checks where run and the checks were stopped as soon as an error occurred even if it was just a temporary error. This has been fixed in 8.12 but it was slightly complicated to do so.
The anti-spam checks belong in the SMTP server. It has all the necessary data, i.e., client connection and authentication (AUTH and STARTTLS) data, sender and recipient addresses. If the anti-spam checks are done by an outside module, all these data need to be sent to it. However, anti-spam checks most likely have to perform map requests, and such calls may block. It might be interesting to ``parallelize'' those requests, esp. for DNS based maps, i.e., start several of those requests and collect the data later on. This of course makes programming more complicated, it might be considered as an enhancement later on. We need to define a clean API and then it may be available as library which can be linked into the SMTPS or the AR or another module.
The SMTP server must offer a way to check for valid (local) users (see Section 2.6.6). Otherwise mail to local addresses will be rejected only during local delivery and hence a bounce must be generated which causes problems due to forged sender addresses, i.e., they result in double bounces and may clog up the MTS.
See also Section 2.6.4.
There must be an option to rewrite envelope addresses. This should be separately configurable for sender and recipient addresses.
If sendmail acts as a gateway, it may rewrite addresses in the headers. This can be done by contacting an address rewrite engine. Question: should this be just another mode in which the address resolver can operate?
Question: what is the best way to specify when address rewriting should be used? It might be useful to do this based on the connection information, i.e., when sendmail acts as a gateway between the internal network and the internet.
It would be nice to implement the address rewriting as just another file type. In this case the SMTP servers could just open a file and output the data (message header) to that file. This file type is a layer on top of the CDB file type. The file operations are in this case stateful (similar to those for TLS). As soon as the body is reached, no more interference occurs. Using this approach makes the SMTP server simpler since it doesn't have to deal with the mail content itself.
It must be specifyable to which headers address rewriting is applied. There are be two different classes of header addresses: sender and recipient. These should relate to two different configuration options.
The SMTP server must bind to port 25, which can be done by the supervisor before the server is actually started provided the file descriptor can be transferred to the SMTP server. sendmail 8 closes the socket if the system becomes overloaded which requires it to be reopened later on, which in turn requires root privileges again.
The SMTP server may need access to an authentication database which contains secret information (e.g., passwords). In most systems access to this information is restricted to the root user. To minimize the exposure of the root account, access to this data should be done via daemons which are contacted via protected communication means, e.g., local socket, message queues.
In some cases it might be sufficient to make secret information only available to the user id under which the SMTP server is running, e.g., the secret key for a TLS certificate. This is esp. true if the information is only needed by the SMTP server and not shared with other programs. An example for the latter might be ``sasldb'' for AUTH as used by Cyrus SASL which may be shared with an IMAP server.
The address resolver (AR) has at least two tasks:
Hence the AR is not just for address resolving but also address rewriting. Other tasks might include anti-spam checks. Question: should the two main tasks (rewriting and resolving) be strictly separated?
Question: what kind of interfaces should the address resolver provide? Does it take addresses in external (unparsed) form and offer various modes, e.g., conversion into internal (tokenized) form, syntax check, anti-spam checks, return of a tuple containing delivery agent, host, address and optionally localpart and extension?
Question: who communicates with the AR? The amount of data the AR has to return might be rather large, at least if it is used to expand aliases (see Section 2.6.7). Using IPC for that could cause a significant slowdown compared to intra-process communication. So maybe the AR should be a library that is linked into the queue manager? Possible problems: other programs need easy access to the AR; security problems since AR and QMGR run with the same privileges in that case? Moreover, the AR certainly performs blocking calls which probably should not be in the QMGR. See also Section 3.6.3.4.
Usually the address resolver determines the next hop (mailer triple in sendmail 8) solely based on the envelope and connection information and the configuration. However, it might be useful to take also headers or even the mail body into account. Question: should this be a standard functionality of the AR or should this be only achievable via milters (see Section 2.10) or should this not be available at all? Decision: make this functionality only available via milters, maybe not even at all. It might be sufficient to ``quarantine'' mails (even individual recipients), or reject them as explained in Section 2.10.
sendmail 8 uses a two stage approach for most address lookups:
This approach has the advantages that it can avoid map lookups - which may be expensive (depending on the kind of maps) and in most case several variations are checked - if the entry is not in a class. It has the disadvantages that the class data and the map data must be kept in sync, e.g., it is not sufficient to simply add some entries to a map, the domain part(s) must be added to the corresponding class first2.24.
sendmail 8 provides several facilities for mail routing (besides ruleset hacking):
As can be seen from the previous sections, there are operations that solely affect mail routing and there are operations that solely affect address rewriting. However, some operations affect both, because address rewriting is done before mail routing. Hence the order of operations is important. If address rewriting is performed before mail routing, then the latter is affected. If address rewriting is done after mail routing, then it applies only to the address part of the resolved address (maybe it shouldn't be called resolved address since it is more than an address).
Proposal: provide several operations (rewriting, routing) and let the user specify which operations to apply to which type of addresses and the order in which this happens.
Operations can be:
It might be useful for routing operations to not modify the actual address, i.e., if user@domain is specified, it can be redirected to some other host with the original address or with some new address, e.g., user@host.domain.
Some operations - like masquerading - only modify the address without affecting routing.
So for a clear separation it might be useful to provide two strictly separated set of operations for routing and rewriting. However, in many cases both effects (routing and rewriting) are required together.
Address types are: envelope and header addresses, recipient and sender addresses (others), so there are (at least) four combination.
envelope-sender-handling { canonify }
envelope-recipient-handling { canonify, virtual, mailertable }
Question: is this sufficient?
It must be possible to specify valid recipients via some mechanism. In most cases this applies to local delivery, but there is also a requirement to apply recipient checks to other domains, e.g., those for which the system allows relaying.
Note that local recipients can often only be found in maps that do not specify a domain part, hence the local domains are separately specified. Question: is it sufficient if (unqualified) local recipients are valid for every local domain or is it necessary to have for each local domain a map which specifies the valid recipients? For example, for domain A check map M(A), for domain B check map M(B), etc. Moreover, the domain class would specify whether the corresponding map contains qualified or unqualified addresses. Other attributes might be: preserve case for local part, allow +detail handling, etc.
Configuration example:
local-addresses {
domains = { list of domains };
map { type=hash, name=aliases, flags={rfc2821}}
map { type=passwd, name=/etc/passwd, flags={local-parts}}
}
Valid remote recipients can be specified via entries in an access map to allow relaying to specific addresses, e.g.,
To:user@remote.domain RELAY
If not all valid recipient are known for a domain for which the MTA acts as backup MX server, then an entry of the form:
To:@remote.domain error:451 Please try main MX
should be used.
There are different types of aliases: those which expand to addresses and those which expand to files or programs. Only the former can be handled by the address resolver, the latter must be handled by the local delivery agent for security reasons. Note: Courier-MTA also allows only aliases that expand to e-mail addresses, postfix handles aliases in the LDA. If alias expansion is handled by the LDA then an extra round trip is added to mail delivery. Hence it might be useful to have two different types of alias files according to the categorization above.
Problem: if the SMTP server is supposed to reject unknown local addresses during the RCPT stage, then we need a map that tells us which local addresses are valid. There are two different kinds: real users and aliases. The former can be looked up via some mailbox database (generalization of getpwnam()), the latter in the aliases database. However, if we have two different kinds of alias files then we don't have all necessary information unless the address resolver has access to both files. This might be the best solution: the address resolver just returns whether the address is valid. The expansion of non-address aliases happens later on.
The address resolver expands address aliases when requested by the queue manager. It provides also an owner address for mailing lists if available. This must be used by the queue manager when scheduling deliveries for those expanded addresses to change the envelope sender address.
The queue manager changes the envelope sender for mailing list expansions during delivery. RFC 2821 makes a distinction between alias (3.10.1) and list (3.10.2). Only in the latter case the enveloper sender is replaced by the owner of the mailing list. Whether an address is just an alias or a list is a local decision. sendmail 8 uses owner-address to recognize lists.
Question: what to do about delivery to files or programs? For security reasons, these should never end up in the queue (otherwise someone could manipulate a queue file and cause problems; sendmail would have to trust the security of the queue file, which is a bad idea). In postfix aliases expansion is done by the local delivery agent to avoid this security problem. It introduces other problems because no checkpointing will be done for those deliveries (remember: these destinations - they are not addresses - never show up in queue files).
Notice: alias expansion can result in huge lists (large number of recipients). If we want to suppress duplicates, we need to expand the whole list in memory (as sendmail 8 does now). This may cause problem (memory usage). Since we can't act the same as older sendmail versions do (crash if running out of memory), we need to restrict the memory usage and we need to use a mechanism that allows us to expand the alias piecewise. One such algorithm is to open a DB (e.g., Berkeley DB; proposed by Murray) on disk and add the addresses to it. This will also detect duplicates if the addresses are used as keys. To avoid double delivery, expansion should be done in the local delivery agent and it must mark mails with a Delivered-To: header as postfix [Ven98] and qmail do. Should attempted double delivery (delivery to a recipient that is already listed as Delivered-To:) in this case cause a DSN? Question: is it ok to list all those Delivered-To: headers in an email? Does this cause an information leak? Question: is ok to use Delivered-To: at all? Is this sanctioned by some RFC? Question: do we only do one level expansion per alias lookup? This minimizes the problem about ``exploding'' lists, but it may have a significant performance impact (n deliveries for n-level expansion).
Question: should there be special aliases, e.g., ERROR, DEFER, similar to access map, that cause (temporary) delivery errors, or can those be handled by the access map?
Question: Who does .forward expansion?
551-try <new@address1> 551-try <new@address2> 551-try <new@address3> 551 try <new@address4>
Notice: whether a .forward file is in the home directory of a user, or whether it's in a central directory, or whether it's in a DB doesn't matter much for the design of sendmail X. Even less important is how users can edit their .forward files. sendmail X.0 will certainly not contain any program that allows users to authenticate and remotely edit their .forward file that is stored on some central server. Such a task is beyond the scope of the sendmail X design, and should be solved (in general) by some utilities that adhere to local conventions. Those utilities can be timsieved, scp, digitally signed mails to a script, updates via HTTP, etc.
How about the qmail approach to aliasing? Everything is just handled via one mechanism: HOME(user)/.alias[-extension]. System aliases are in HOME(aliases)/.alias[-extension]. This results in lots of file I/O which probably should be avoided.
Of course this wouldn't be flexible enough for sendmail, it must have the possibility to specify aliases via other means, e.g., maps. It might be better to put everything into maps instead of files spread out over the filesystem. In that case a program could be provided that allows a user to edit her/his own alias entry. However, such a program is certainly security critical, hence it may add a lot of work to implement properly; compare the passwd(1) command.
There have been requests to have other mechanisms than just aliases/.forward to expand an address to multiple recipients. We should consider making the AR API flexible enough to allow for this. However, there is (at least) one problem: the inheritance of ESMTP attributes, e.g., DSN parameters (see also Section 2.4.6). There are rules in RFC 1894 [Moo96a] which explain how to pass DSN requests for mailing lists and aliases. Hence for DSN parameters the rules for aliases should probably apply.
It would be nice to have per-user virtual hosting. This can relieve the admin from some work. Todo: Compare what other MTAs offer and at least make sure the design doesn't preclude this even though it won't be in sendmail X.0. Is contrib/buildvirtuser good enough?
qmail allows to delegate virtual hosts to users via an entry in a configuration file, e.g., virthost.domain: user. Mail to address@virthost.domain goes to user-address. To keep the virtual domain use virthost.domain: user-virthost.domain. address@virthost.domain goes to user-virthost.domain-address then. Problem: lots of little files instead of a table.
FallbackMXHost can be used in sendmail 8 to specify a host which is used in case delivery to other hosts fails (applies only to mailers for which MX expansion of the destination host is performed). It might be useful to make this more flexible:
The advantages/disadvantages of these proposals are not yet clear.
In theory, we could use the the second proposal to have generic bounce and defer mailers. That is, if mail delivery fails with a permanent error, the default ``fallback'' will be a bounce mailer, if mail delivery fails with a temporary error, the ``fallback'' will be a defer mailer. This would allow maximum flexibility, but the impact on the QMGR (which has to deal with all of this) is not clear.
The address resolver should run without any privileges. It needs access to user information databases (mailbox database), but it does not need access to any restricted information, e.g., passwords or authentication data.
Initial mail submission poses interesting problems. There are several ways to submit e-mail all of which have different advantages and disadvantages. In the following section we briefly list some approaches. But first we need to state our requirements (in addition to the general sendmail X requirements that have been given in Chapter 1).
Don't use SMTP (because it's complicated and may reject mail), but SMSP (simple mail submission protocol), submission via socket. Possible problem: how to identify other side? Always require authentication (SMTP AUTH)? Way too complicated. It's in general not possible to get the uid of the sender side, even for local (Unix socket) connections.
At the MotM (2002-08-13) option 3 was clearly favored.
See also [Ber] for more information about the problem of secure interprocess communication (for Unix).
Does this work? The files should be not world writable, so there must be some common group. Since it is not practical to have all users in the same group (and making sure that that group is used when a queue file is written), this may not work after all. Run a daemon as root, notify it of new entries: cd queuedirectory, set*uid to owner of queuedirectory, run the entry.
Possible pitfalls: chown on some systems possible for non-root!
Notice: in the first version we may be able to reuse the sendmail 8 MSP. This gives us a complete MHS without coding every part.
Since the initial mail submission program is invoked by users, it must be careful about its input. The usual measures about buffer overflows, untrusting data, parsing user input, etc. apply esp. to this program. See the Section 2.14 for some information.
Todo: Depending on the model selected above describe the possible security problems in more detail.
There are several types of mail delivery agents in sendmail X similar to sendmail 8. One of them acts as SMTP client which is treated separately in Section 2.9. Another important one is the local delivery agent treated in the Section 2.8.3.
Question: does a DA (esp. SMTP client) check whether a connection is ``acceptable''? Compare sendmail 8: TLS_Srv, TLS_RCPT. It could also be done by the QMGR. The DA has the TLS information, it would need to send that data to the QMGR if the latter should perform the check. That might make it simpler for the QMGR to decide whether to reuse a connection (see also Section 3.4.10.2; maybe the QMGR doesn't need this additional restriction for reuse). However, if it is a new connection it is simpler (faster) to perform that check in the DA.
Idea: instead of having a fixed set of delivery agents and an address resolver that ``knows'' about all of them, maybe a more modular approach should be taken. Similar to Exim [Haz01] and Courier-MTA [Var01] delivery agents would be provided as modules which provide their own address rewriting functions. These are called in some specified order and the first which returns that it can handle the address will be selected for delivery.
sendmail 8 uses a centralized approach: all delivery agents must be specified in the .cf file and the address rewriting must select the appropriate delivery agent.
sendmail X must provide a simple way to add custom delivery agents and to select them. It seems best to hook them into the address resolver, that's the module which selects a delivery agent.
There must be a simple way to specify different delivery agents, i.e., their behavior and their features (see Section 3.8.2 for details). This not refers to local delivery agents (2.8.3) and SMTP clients (2.9), but also to variants of those.
In addition to specifying behavior, actual instances must be described, i.e., the number of processes and threads that are (or can be) started and are available. These two descriptions are orthogonal, i.e., they can be combined in almost any way. The configuration must reflect this, e.g., by having to (syntactical separate) structures that describe the two specifications. For practical reasons, the following approach might be feasible:
Note: sendmail 8 only specified delivery classes (called mailers), it does not have the need for delivery instances because it is a monolithic program that implements the mailers itself or invokes them as external programs without restrictions. In sendmail X certain restrictions are imposed, i.e., the number of processes that can run as delivery agents or the number of threads are in general limited. Even though these limits might be arbitrarily high, they must be specified.
Example:
delivery-class smtp { port = 25; protocol = esmtp; }
delivery-class msaclient { port = 587; protocol = esmtp; }
delivery-class lmtp { socket = lmtp.sock; protocol = lmtp; }
delivery-agent mailer1 { delivery-classes = { esmtp, lmtp };
max_processes = 4; max_threads = 255; }
delivery-agent mailer2 { delivery-classes = { msaclient };
max_processes = 1; max_threads = 16; }
delivery-agent mailer3 { delivery-classes = { esmtp };
max_processes = 2; max_threads = 100; }
Notes:
A local delivery agent usually needs to change its user id to that of the recipient (depending on the local mail store; this is the common situation in many Unix versions). Since sendmail X must not have any set-user-id root program, a daemon is the appropriate answer to this problem (started by the supervisor, see Section 2.3).
Alternatively, a group-writable mailstore can be used as it is done in most System V based Unix systems. A unique group id must be chosen which is only used by the local delivery agent. It must not be shared with MUAs as it is done in some OSs. There is at least one problem with this approach: a user mailbox must exist before the first delivery can be performed. That requires that the mailbox is created when the user account is created and no MUA must remove the mailbox when it is empty. There could be a helper program that creates an empty mailbox for a user which however must run as root and hence will have security implications.
The local delivery agent in sendmail X will be the equivalent of mail.local from sendmail 8. It runs as a daemon and speaks LMTP. By default, it uses root privileges and changes its user id to that of a recipient before writing to a mailbox.
There might be other local delivery agents which use the content database access API to maximize performance, e.g., immediate delivery while the sender is waiting for confirmation to the final dot of an SMTP session.
sendmail X.0 will use a normal SMTP client - which is capable of speaking also LMTP - as an interface between mail.local and the queue manager. That program implements the general DA API on which the queue manager relies. The API is described in Section 3.8.4. Later versions may integrate the API into mail.local.
If the LDA also takes care of alias (and .forward) expansion (see Section 2.6.7.1), then sendmail X must provide a stub LDA that interfaces with custom LDAs. The stub LDA must provide the interface to the QMGR and the ability to perform .forward expansion. Its interface to the custom LDAs should be via LMTP in a first approach.
The interface to the local delivery agents must be able to provide the full address as well as just the local part (plus extensions) in all required variations. There are currently some problems with LDAs that require the full address instead of just the local part which must be solved in sendmail X. Todo: explain problems and solution(s).
Mail delivery agents may require special privileges as explained above.
For obvious security reasons, the LDA will not deliver mail to a mailbox owned by root. There must be an alias (or some other method) that redirects mail to another account. The LDA should also not read files which require root privileges.
The SMTP client is one of the mail delivery agents (see Section 2.8).
Todo: describe functionality.
Similar to SMTPS there are several architectures possible, e.g., simple (preforked) processes, multi-threaded, event-driven, or using state-threads. We need to write similar prototypes to figure out the best way to implement the SMTP clients. It isn't clear yet whether it should be the same model as SMTPS. However, it might be best to use the same model to minimize programming effort.
There are basically two different situations for a SMTPC: open a new connection (new session) or reuse an existing connection (new transaction).
New session:
New transaction:
It might be useful if the data from the QMGR includes:
The SMTP client will run without root privileges. It needs only access to the body of an e-mail that it is supposed to deliver. However, it may need access to authentication data, e.g., for STARTTLS: a client certificate (can be readable by everyone) and a corresponding key (must be secured), for AUTH it needs access to a pass phrase (for most mechanisms) which also must be secured2.25. For these reasons it seems appropriate that an SMTP client uses a different user id than other sendmail X programs, and achieves access to shared data (mail body, interprocess communication) via group rights.
The first version of sendmail X will not support the milter API in the same way as sendmail 8 does. Any functions that allow for modifications of a mail will not be implemented. A basic milter version that supports policy decisions should be supported, however. This is necessary to implement local anti-spam features etc, especially since there is no easy extension via rulesets as in sendmail 8.
The Milter API should be extended in sendmail X, even though maybe not in the first version. However, sendmail X must allow for the changes proposed here.
Notice: if a milter is allowed to change recipient information (1) then the sendmail X architecture must allow for this. The architecture could be simpler if the address resolver solely depends on envelope information and the configuration. If it depends also on the mail content, then the address resolver must be called later during the mail transmission. This also defeats ``immediate'' delivery, i.e., delivery to the next hop while the mail is being received. The additional functionality will most likely be a requirement (too many people want to muck around with mail transmission). It would be nice to allow for both, i.e., mail routing solely based on envelope data, and mail routing based on all data (including mail content). There should be a configuration options which allows the MTA to speed up mail routing by selecting the first option.
Milters should run as a normal (unprivileged) user, but without any access to the sendmail X configuration/data files. The communication between the MTA and the milters must occur via protected means to prevent bogus milters to interfere with the operation of the MTA.
A program called mailq will show the content of the mail queue. Various options control the output format and the kind of data shown.
It might be useful to ask the queue manager to schedule certain entries for immediate (``as soon as possible'') delivery. This will also be necessary for the implementation of ETRN.
Some statistics need to be available. At least similar to mailstats in sendmail 8 and the data from the control socket. Data for SNMP should be made available. Maybe the rest is gathered from the logfile unless it can be provided in some other fashion. For example, it is probably not very useful to provide per-address statistics inside the MTA (QMGR). This would require too much resources and most people will not use that data anyway. However, it might be useful to provide hooks into the appropriate modules such that another program can collect the data in ``real-time'' without having to parse a logfile.
There should be some sophisticated programs that can give feedback about the performance of the MTA.
General question: how to allow access to the data? Should we rely on the access restriction of the OS? That might be complicated since we probably have to use group access rights to share data between various modules of sendmail X. It is certainly not a good idea to give out those group rights to normal users. Moreover, some OS only allow up to 8 groups for an account. Depending on the number of modules some program has to communicate with this may cause problems.
Maps can be used to lookup data (keys, LHS) and possibly replace a key with the result of the lookup, some lookups are only used to find out whether an entry exists in the map. Ordinary maps (databases) provide only a lookup function to find an exact match2.26. There are many cases in which some form of wildcard matching needs to be provided. This can be achieved by performing multiple lookups as explained in the following.
In many places we will use maps to lookup data and to replace it by the RHS of the map. Those places are: aliases, virtual hosting, mail routing, anti-spam, etc. There are some items which can be looked up in a map that need some form of wildcard matching. These are:
There's an important difference between 1 and 2: IP addresses have a fixed length2.27, while hostnames can have a varying length. This influences how map entries for parts (subnets/subdomains) can be specified: for the former it is clear whether a map entry denotes a subnet while this isn't defined for the latter, i.e., domain.tld could be meant to apply only to domain.tld or also to host.domain.tld.
We need a consistent way to define how a match occurs. This refers to:
| dom.ain | RHS |
| .dom.ain | RHS |
to match the domain itself and all of its subdomains.
So the lookup would be: full name, name without first component but with leading dot, if there is something left repeat previous step, until a lookup succeeds.
| *dom.ain | RHS |
This would be more in line with the expectation of normal users due to wildcard usage in shells or regular expressions.
| @dom.ain | RHS |
| dom.ain | RHS |
The first one will be an exact match, the second matches also all subdomains. However, this makes the lookup algorithm slightly more complicated: during the first lookup (full host name) it has to include the anchor (@), thereafter it must omit it. Moreover, the anchor is confusing if the entry doesn't apply to e-mail addresses but to connection information etc.
Lookup full address, Lookup address with ++ if +detail exists and detail not null, Lookup address with +* if +detail exists, Lookup address without +detail.
Replacement:
| 1 | user name |
| 2 | detail |
| 3 | +detail |
| 4 | omitted subdomain? |
As usual localparts are anchored with a trailing @ to avoid confusion with domain names.
Notice: the ``detail'' delimiter should be configurable. sendmail 8 uses +, other MTAs use -. This may interfere with aliases, e.g., owner-list. Question: how to solve this problem?
As explained in Section 1.1.3.4, sendmail X must provide hooks for extensions. One possible way are modules, similar to Apache [ASF]. Modules help to avoid having large binaries that include everything that could ever be used.
Modules must only be loaded from secure locations. They must be owned by a trusted user.
This section contains a hints and thought on how to design and implement programs, esp. those related to MTAs, to ensure they are secure.
It has not yet been decided whether the initial mail submission program (see Section 2.7) will be set-group-ID. No program in sendmail X is set-user-ID root.
A set-group-ID/set-user-ID program must operate in a very dangerous environment that can be controlled by a malicious user. Moreover, the items that must be checked varies from OS to OS, so it is difficult to write portable code that cleans up properly.
Only use root if absolutely necessary. Do not keep root privileges because they might be needed later on again, consider splitting up the program instead.
Avoid writing to root owned files. Question: is there any situation where this would be required? Avoid reading from files that are only accessible for root. This should only be necessary for the supervisor, since this program runs as root so its configuration file should be owned by root. Otherwise root would have to rely on the security of another account.
sendmail 8 treats programs and files as addresses. Obviously random people can't be allowed to execute arbitrary programs or write to arbitrary files, so sendmail 8 goes through contortions trying to keep track of whether a local user was ``responsible'' for an address. This must be avoided.
The local delivery agent can run programs or write to files as directed by $HOME/.forward, but it must always run as that user. The notion of ``user'' should be configurable, but root must never be a user. To prevent stupid mistakes, the LDA must make sure that neither $HOME nor $HOME/.forward are group-writable or world-writable.
Security impact: Having the ability to write to .forward, like .cshrc and .exrc and various other files, means that anyone who can write arbitrary files as a user can execute arbitrary programs as that user.
Do not assume that data written to disk is secure. If at all possible, assume that someone may have altered it. Hence no security relevant actions should be based on it.
The essence of user interfaces is parsing: converting an unstructured sequence of commands into structured data. When another program wants to talk to a user interface, it has to quote: convert the structured data into an unstructured sequence of commands that the parser hopefully will convert back into the original structured data. This situation calls for disaster. The parser often has bugs: it fails to handle some inputs according to the documented interface. The quoter often has bugs: it produces outputs that do not have the right meaning. When the original data is controlled by a malicious user, many of these bugs translate into security holes (e.g., find | xargs rm).
For e-mail, only a few interfaces need parsing, e.g., RFC 2821 [Kle01] (SMTP) and RFC 2822 [Res01] (for mail submission). All the complexity of parsing RFC 2822 address lists and rewriting headers must be in a program which runs without privileges.
Security holes can't show up in features that don't exist. That doesn't mean that sendmail X will have almost no features, but we have to be very carefull about selecting them and their security and reliability impact.
Especially the availability of several options can cause problems if a program can access data that is not directly accessible to the user who calls it. This applies not only to set-group/user-ID programs, but also daemons that answer requests. This has been demonstrated by sendmail 8, e.g., debug flags for queue runners, which reveal private data.
C ``strings'' are inherently dangerous. Use something else which prevents buffer overflows.
There are more things to security than just these programming advices. For example, a program should not leak privileged (private/confidential) information. This applies to data that is logged or made available via debugging options. A program must also prevent being abused to access data that it can read due to its rights and being tricked into making that data available to an attacker, neither for reading nor writing.
Question: where does sendmail need privileged access? The following sections provide a list and hopefully solutions.
LDAP with Kerberos: there should be a way to do this without root privileges. This might be a documentation issue (kinit before starting sendmail, chown ticket file)
PH map: it's possible... (how?)
Problem: the server may close(2) the socket due to errors or load conditions, e.g., RefuseLA, MaxChildren in sendmail 8. In that case the server needs to bind(2) to the port again later on. Since the server is not supposed to run with root privileges, another program (the MCP) must take care of that, i.e., it is notified of the problem and can either start a new server or pass an open fd to the server.
Note: To bind(2) to a reserved port may not require root on all OS variants, there might be other access control methods, e.g., a different, privileged user id that is allowed to bind(2) to certain ports.
Alternatively, a server might not close(2) the socket, Instead of close(2), accept(2) and give 421 error, then close(2) just the connection.
Side note: RefuseLA, MaxDaemonChildren should be configurable per DaemonPortOption.
Can we keep interfaces abstract and simple enough so we can use RPCs2.28? This would allow us to build a distributed system. However, this must be a compile time option, so we can "put together" an MTA according to our requirements (all in one; some via shared libraries; some via sockets; some via RPCs). See also Section 3.1.1.
Rulesets, esp. check_*: make the order in which things happen flexible. Currently it's fixed in proto.m4, which causes problems; (tempfail in parts: require rewrite, even then it's hard to maintain etc). Use subroutines and make the order configurable (within limits).
Use of mode bits to indicate status of file? e.g., for forward: it +t: being edited right now, don't use (temp.fail.) for queue files: +x completely written.
Can several processes listen on a socket? Yes, but there is a ``thundering herd'' problem: all processes are woken up, but only one gets the connection. That is inefficient for large number of processes. However, it can be mitigated by putting locks around the file such that only one process will do an accept(). See [Ste98] for examples.
Configuration: instead of having global configuration options why not have configuration functions? For example: Timeout.Queuereturn could be a function with user-defined input parameters (in form of macros?):
Timeout.Queuereturn(size, priority, destination) = some expression.
This way we don't have to specify the dependency of options on parameters, but the user can do it. Is this worthwhile and feasible? What about the expression? Would it be a ruleset? Too ugly and not really useful for options (only for addresses). Example where this is useful: the FFR in 8.12 when milters are used (per Daemon). Example where this is already implemented: srv_features in 8.12 allows something like this.
Problem: which macros are valid for options? For example, recipient can be a list for most mails.
Configuration changes may cause problems because some stored data refers to a part of the configuration that is changed or removed. For example, if there are several retry schedules and an entry in the queue refers to one which is removed during a configuration change, what should we do? Or if the retry schedule is changed, should it affect ``old'' entries? sendmail 8 pretty much treats a message as new every time it processes it, i.e., it dynamically determines the actual delivery agent, routing information, etc. This probably can solve the problem of configuration changes, but it is certainly not efficient. We could invalidate stored information if the configuration changes (see also Section 3.12.6).
Most sendmail X programs must have a compilation switch to turn on profiling (not just -pg in the compiler). Such a switch will turn on code (and data structures) that collect statistics related to performance. For example, usage (size, hit rate) of caches, symbol tables, general memory usage, maybe locking contentions, etc. More useful data can probably be gathered with getrusage(2). However, this system call may not return really useful data on most OS. On OpenBSD 2.8:
long ru_maxrss; /* max resident set size */ long ru_ixrss; /* integral shared text memory size */ long ru_idrss; /* integral unshared data size */ long ru_isrss; /* integral unshared stack size */
seem to be useless (i.e., 0). SunOS 5.7: NOTES: Only the timeval member of struct rusage are supported in this implementation.
A program like top might help, but that's extremely OS dependent. Unless we can just link a library call in, we probably don't want to use this.
There are various requirements for logging:
Note: a different approach to logging is to use the normal I/O (well, only O) operations and have a file type that specifies logging. The basic functionality for that is available in the sendmail 8/9 I/O layer. However, it seems that this approach does not fulfill the requirements that are stated in the following sections.
The logging in sendmail X must be more flexible than it was in older versions. There are two different issues:
About item 1: the current version (sendmail 8) uses: LogLevel and the syslog priorities (LOG_EMERG, LOG_ERR, ...). The latter can be used to configure where and how to log entries via syslog.conf(5). The loglevel can be set by the administrator to select how much should be logged. Note: in some sense these are overlapping: syslog priorities and loglevels are both indicators of how important an log event is. However, the former is not very fine grained: there are only 8 priorities, while sendmail allows for up to 100 loglevels. Question: is it useful to combine both into a single level or should they be kept separate? If they are kept separate, is there some correlation between them? For example, it doesn't make sense to log an error with priority LOG_ERR but only if LogLevel is at least 50. ISC [ISC01] combines those into a single value, but it basically uses only the default syslog priorities and then additionally debug levels.
An orthogonal problem (item 2) is logging per ``functionality''2.29. There are many cases where it is useful to select logging granularity dependent on functionalities provided by a system. This is similar to the debugging levels in sendmail 8. So we can assign a number to a functionality and then have a LogLevel per functionality. For example, -L8.16 -L20.4 would set the LogLevel for functionality 8 to 16 and for 20 to 4. Whether we use numbers or names is open for discussion.
syslog offers facilities (LOG_AUTH, LOG_MAIL, ..., LOG_LOCALx), however, the facility for logging is fixed during the openlog() call, it is not a parameter for each syslog() call. This is serious drawback and makes the facility fairly useless for software packages that consists of several parts within a single process like sendmail 8 (which performs authentication calls, mail operations, and acts as daemon (at least)).
ISC ([ISC01], see Section 3.15.16.1) offers categories and modules to distinguish between various invocations of the logging call. Logging parameters are per category, i.e., it is possible to configure how entries are logged per category and per priority. The category is similar to the syslog facility but it is an argument for each logging call and hence offers more flexibility. However, ISC does not offer loglevels beyond the priorities. A simple extension can associate loglevels with categories and modules. If the loglevel specified in the logging call is larger than the selected value, then the entry will not be logged.
Misc: should we use log number consisting of 16 bit category and 16 bit type number?
Logfiles must be easy to parse and analyze. For parsing it is very helpful if simple text tools like awk, sed, et.al. can be used instead of requiring a full parser, e.g., one that understands quoting and escaping.
The basic structure of logfile entries is a list of fields which consist of a name and a value, e.g.,
name1=value1, name2=value2, ...
The problems here are whether the delimiters (space or comma) are unique, i.e., whether they do not appear in the name or the value of a field. While this is easy to guarantuee for the name (because it's chosen by the program), values may contain those delimiters because they can be (indirectly) supplied by users. There are two approaches to solve this problem:
Proposal 1 is not easy to achieve since values are user controlled as explained before. Approach 2 seems to be more promising, even now there is some encoding happening in sendmail 8, i.e., non-printable characters are replaced by their octal representation (or in some cases simply by another character, e.g., '?'). A simple encoding scheme would be: replace space with underscore, escape underscore and backslash by a leading backslash. The decoding for this requires parsing to see whether underscores or backslashes where escaped. This encoding allows to use space as delimiter2.30. A different proposal is not to use spaces as delimiters (and hence not to change them), but commas or another fairly unique character. Which character (besides the obvious ',' and ';') would be a ``good'' delimiter, i.e., would not commonly appear in a value?
The logging functionality must be abstracted out, i.e., we have to come up with a useful API and provide one library for it, which would use syslog(). Other people can replace that library with their own, e.g., for logging into a database, files, or whatever.
A simple level of debugging can be achieved by turning on verbose logging. This may be via additional logging options, e.g., -dX.Y, similar to sendmail 8, but the output is logged not printed on stdout.
Additionally, there must be some way to start a program under a debugger. Remember: most programs are started by the supervisor, so it is not as simple as in sendmail 8 to debug a particular module. Take a look at postfix for a possible solution.
sendmail X must behave well in the case of resource shortages. Even if memory allocation fails, the program should not just abort, but act in a fail-safe manner. For example, a program that must always run even in the worst circumstances is the queue manager. If it can't allocate memory for some necessary operation, it must fall back to a ``survival'' mode in which it does only absolutely necessary things and shuts down everything else and then ``wait for better times'' (when the resource shortage is over). This might be accomplished by reserving some memory at startup which will be used in that ``survival'' mode.
postfix components just terminate when they run out of memory if a my*alloc() routine is used. This is certainly not acceptable by some parts of postfix nor sendmail X. Library routines especially shouldn't have this behavior.
sendmail X will be developed in several stages such that we have relatively soon something to test and to experiment with.
First, the design and architecture must be specified almost completely. Even if not every detail is specified, every aspect of the complete system must be mentioned and be considered in the overall design. We don't want to patch in later new parts which may require a redesign of some components, esp. if we already worked on those.
However, the implementation can be done in stages as follows: the first version will consist only of a relaying MTA, i.e., a system that can accept mail via SMTP and relay it to delivery agents that speak SMTP or LMTP. This way we will have an almost complete system with basic functionality. The ``only'' parts that are missing are other delivery agents, an MSP, and some header rewriting routines etc.
This section contains the explanation of terms used in this (and related) documents. The terms are usually taken from various RFCs.