This chapter describes the external functionality as well as the internal interfaces of sendmail X as much as required, i.e., for an implementation by experienced software engineers with some knowledge about MTAs etc. In each section it will be made clear what is the external functionality and which API or other interface (in the form of a protocol) will be provided.
The internal functionality describes the interfaces between the modules of sendmail X. As such they must never be used by anything else but the programs of which sendmail X consists. These interfaces are subject to changes without notice. It is not expected that modules from different versions work with each other, even though it might be possible.
An external interface is one which is accessible by a user.
Many of the sendmail X modules require that function calls do not block. If a function can block then an asynchronous API is required. Unfortunately it seems hard to specify an API that works well with blocking and non-blocking calls. Hence the APIs will be specified such that most (or all) blocking functions are split in two: one to initiate a function (the initiate function) and another one (the result function) to get the result(s) of the function call. To allow for a synchronous implementation, the first (initiate) function should also provide result parameters and a status return. The status indicates whether the result parameters have valid values, or whether the result will be returned later on via the second (get result) function. This convention seems to make it possible to provide APIs that work for both (synchronous and asynchronous) kind of implementations.
The calling program should not be required to poll for a result, but instead it should be notified that a result is available. This can be done via some interprocess notification mechanism, e.g., System V message passing or via a message over a socket through which both programs communicate. Then those programs can use select(2), poll(2), or something similar to determine whether a message is available. Note: this requires that both programs agree on a common notification mechanism which can be a problem in case of (third-party) libraries. For example, OpenLDAP [LDA] does provide an asynchronous interface (e.g., ldap_search(3)), but it does not provide an ``official'' notification mechanism3.1, it requires polling (ldap_result(3)). It should be possible to have a function associated with a message (type) such that the main loop is just a function dispatcher (compare engine in libmilter).
In this section we describe how asynchronous ``function'' calls can be handled. For the following discussion we assume a caller C and a callee S. The caller C creates a request RQ that contains the arguments for a function F, and a token T which uniquely identifies the request RQ (we could write RQ(T)). Note: it is also possible to let S generate the token if the argument is a result parameter (pointer to a token which can be populated by S). Additionally, the argument list may contain a result parameter PR in which a result can be immediately stored if the call can be handled synchronously. C enqueues the fact that it made the function call by storing data describing the current state St(T) in a queue/database DB along with the identifier T. The request is sent to S (may be appended to a queue for sending via a single communication task instead of sending it directly) unless it can be handled immediately and returned via the result parameter PR (the return status must specify that the result has been returned synchronously). A communication task receives answers A from S. The answer contains the identifier T which is used to lookup the current data St(T) in the DB. Then a function (the result or callback function RC) is invoked with St and A as parameters. It decodes the answer A (which contains the function result) and acts accordingly, also taking the current state St into account and probably modifying it accordingly. Additionally, it may use the result parameter PR to store the result in the proper location. The result parameter may provide some buffer (or allocated) structure in which to store the result such that the callee is not responsible for the allocation. However, the details of this depend on the functions and their requirements, e.g., their output values (it may be just a scalar).
To handle immediate status returns, the function that sends (enqueues) the request has to be able to deal with that. Such an implementation is an enhancement for a later version (probably not for 9.0).
There are several kinds of identifiers that are used within sendmail X for various purposes. Identifiers (handles, tags) in general must of course be unique during the time in which they are used to identify an object. Beyond this obvious purpose, some identifiers should fulfill other requirements.
If a handle is only used by the caller to identify an object in its memory, then it seems a good idea to use the memory address of that object as handle (as for example done by aio(3), see aio_return(3)). The advantages are:
Section 2.2.5 gives an example how two SMTP servers are defined and reference common parts (aliases). However, there are some problems due to the modularized implementation of the MTS: many operations are performed by the address resolver, e.g., access map lookups and routing decisions including whether a recipient address is local. It is easy to imagine a configuration in which different servers listen on different IP addresses and need different configurations, e.g., a map of local users or even anti-spam configurations. Most MTAs only offer virtual hosting, i.e., one MTA is responsible for several domains, but those domain have basically the same configuration. sendmail 8 has some options per ``daemon'' (DaemonPortOptions) and several requests have been made to have more options ``per daemon''. This is easy in sendmail X as long as those options are ``local'' to the server, but it is complicated when other modules provide the functionality.
There are two problems involved here:
Problem 1 could be solved as explained in Section 2.2.5.
Problem 2 could be solved by separating the functionality, e.g., mailertable could be split into two tables: one to decide where a recipient is local, and another one for routing addresses. However, this may increase maintainance costs as some information is duplicated in different tables which may cause consistency problems.
It is important to use consistent naming; not just in the source code but especially in the configuration file.
In the following some proposals are given to achieve this. First about the structure of entries:
Next about the (components of) names used:
Question: how should classes (lists, sets) be specified? Should it be just a lists of entries in the configuration file? sendmail 8 allows to load classes from other sources, e.g., from an external file, a program, or a map lookup. In the latter case a key is looked up in a map and the RHS (split?) is added to the specified class. It might be useful to have also a map which simply specifies the valid members as keys, i.e., lookup a value and if it is found, it is a member of the class for which the map is given. More complicated would be that the RHS contains a list of class names which would be compared against the class that is checked.
The supervisor doesn't have an external interface, except for starting/stopping it. Reconfiguring is probably done via stop/start, or maybe via sending it a HUP signal. The latter would be good enough to enable/disable parts of sendmail X, i.e., edit the configuration file and restart the supervisor. In the first version, there will be no special commands to enable/disable parts of sendmail X.
The supervisor can be configured in different ways for various situations. Example: on a gateway system local delivery is not required hence the LDA daemon is not configured (or started).
The MCP starts processes on demand, which can come from several sources:
The MCP keeps track of the number of processes and acts accordingly, i.e., when the upper limit is reached no further processes will be started, when a lower limit is reached more processes are started. Child processes also inform the MCP whenever they finished a task and are available for a new one.
Case 2: If there is no process available then the MCP listens on the communication channel and starts a process when a communication comes in. In that case the connection will be passed to the new process (in the form of an open file descriptor). This is similar to inetd or postfix's master program. Question: how to deal with the case where processes are available? Should those processes just call accept() on the connection socket? That's the solution that the postfix master program uses; the child processes have access to the connection socket and all(?) of them listen to it (Wietse claims the thundering herd problem isn't really a problem since the number of processes is small).
Question: would it be more secure if only a program can request to start more copies of itself? However, that would probably increase the program complexity (slightly) and communication overhead. Decision: designated programs can request to start other programs.
Question: should the MCP use only one file descriptor to receive requests from all processes it started or should it have one fd per process or process type? The latter seems better since it allows for a clean separation, even though it may require (a few) more fds.
There are several types of shutdown:
Question: how to distinguish between immediate shutdown and ``normal'' shutdown? The former is probably triggered by a signal (SIGTERM), the latter by a command from the MCP (or some other control program).
The supervisor is responsible for shutting down the entire sendmail X system. To achieve this, the receiving processes are first told to stop accepting new connections. Current connections are either terminated (if immediate shutdown is required, e.g., system will be turned off fast) or are allowed to proceed (up to a certain amount of time). The queue manager will not schedule any delivery attempts any more and wait for outstanding connections to terminate. Delivery agents will be told to terminate (again: either immediately or orderly). The helper programs, e.g., address resolver, will be terminated as soon as the programs which require them have stopped.
The configuration of the MCP might be similar to the master process in postfix. It contains a list of processes, their types, the uid/gid they should run as, the number of processes that should be available, how they are supposed to be started, etc. It should also list how the processes communicate with the MCP (fork()/wait(), pipe), how often/fast a process can be restarted before it is considered to fail permanently. The latter functionality should probably be similar to (x)inetd.
Here's the example master.cf3.2file from postfix:
Postfix master process configuration file. Each line describes how a mailer component program should be run. The fields that make up each line are described below. A "-" field value requests that a default value be used for that field.
Service: any name that is valid for the specified transport type (the next field). With INET transports, a service is specified as host:port. The host part (and colon) may be omitted. Either host or port may be given in symbolic form or in numeric form. Examples for the SMTP server: localhost:smtp receives mail via the loopback interface only; 10025 receives mail on port 10025.
Transport type: "inet" for Internet sockets, "unix" for UNIX-domain sockets, "fifo" for named pipes.
Private: whether or not access is restricted to the mail system. Default is private service. Internet (inet) sockets can't be private.
Unprivileged: whether the service runs with root privileges or as the owner of the Postfix system (the owner name is controlled by the mail_owner configuration variable in the main.cf file).
Chroot: whether or not the service runs chrooted to the mail queue directory (pathname is controlled by the queue_directory configuration variable in the main.cf file). Presently, all Postfix daemons can run chrooted, except for the pipe and local daemons. The files in the examples/chroot-setup subdirectory describe how to set up a Postfix chroot environment for your type of machine.
Wakeup time: automatically wake up the named service after the specified number of seconds. A ? at the end of the wakeup time field requests that wake up events be sent only to services that are actually being used. Specify 0 for no wakeup. Presently, only the pickup, queue manager and flush daemons need a wakeup timer.
Max procs: the maximum number of processes that may execute this service simultaneously. Default is to use a globally configurable limit (the default_process_limit configuration parameter in main.cf). Specify 0 for no process count limit.
Command + args: the command to be executed. The command name is relative to the Postfix program directory (pathname is controlled by the program_directory configuration variable). Adding one or more -v options turns on verbose logging for that service; adding a -D option enables symbolic debugging (see the debugger_command variable in the main.cf configuration file). See individual command man pages for specific command-line options, if any.
SPECIFY ONLY PROGRAMS THAT ARE WRITTEN TO RUN AS POSTFIX DAEMONS. ALL DAEMONS SPECIFIED HERE MUST SPEAK A POSTFIX-INTERNAL PROTOCOL.
DO NOT CHANGE THE ZERO PROCESS LIMIT FOR CLEANUP/BOUNCE/DEFER OR POSTFIX WILL BECOME STUCK UP UNDER HEAVY LOAD
DO NOT CHANGE THE ONE PROCESS LIMIT FOR PICKUP/QMGR OR POSTFIX WILL DELIVER MAIL MULTIPLE TIMES.
DO NOT SHARE THE POSTFIX QUEUE BETWEEN MULTIPLE POSTFIX INSTANCES.
# service type private unpriv chroot wakeup maxproc command + args # (yes) (yes) (yes) (never) (50) smtp inet n - n - - smtpd #628 inet n - n - - qmqpd pickup fifo n n n 60 1 pickup cleanup unix - - n - 0 cleanup qmgr fifo n - n 300 1 qmgr #qmgr fifo n - n 300 1 nqmgr rewrite unix - - n - - trivial-rewrite bounce unix - - n - 0 bounce defer unix - - n - 0 bounce flush unix - - n 1000? 0 flush smtp unix - - n - - smtp showq unix n - n - - showq error unix - - n - - error local unix - n n - - local virtual unix - n n - - virtual lmtp unix - - n - - lmtp
Interfaces to non-Postfix software. Be sure to examine the manual pages of the non-Postfix software to find out what options it wants. The Cyrus deliver program has changed incompatibly.
cyrus unix - n n - - pipe
flags=R user=cyrus argv=/cyrus/bin/deliver -e -m ${extension} ${user}
uucp unix - n n - - pipe
flags=Fqhu user=uucp argv=uux -r -n -z -a$sender - $nexthop!rmail ($recipient)
ifmail unix - n n - - pipe
flags=F user=ftn argv=/usr/lib/ifmail/ifmail -r $nexthop ($recipient)
bsmtp unix - n n - - pipe
flags=Fq. user=foo argv=/usr/local/sbin/bsmtp -f $sender $nexthop $recipient
First take at necessary configuration options for MCP:
Notice: using a syntax as in master.cf or inetd.conf is not a good idea, since it violates the requirements we listed in Section 2.2.2. The syntax must be the same as for the other configuration files for consistency.
The supervisor starts and controls several processes. As such, it has a control connection with them. In the simplest case these are just fork(), wait() system calls, in more elaborate case it may be a socket over which status and control commands are exchanged.
The supervisor may set up data (fd, shared memory, etc) that should be shared by different processes of the sendmail X system. Notice: since the MCP runs as root, it could setup sockets in protected directories to which normal users don't have access. Open file descriptors to those sockets (for communication between modules) could then be passed on to forked programs. This may help to increase the security of sendmail X due to the extra protection. However, it requires that the MCP sets up all the necessary communication files. Moreover, if a program closes the socket (as SMTPS may do for port 25) it can't reopen it anymore and hence must get the file descriptors from the MCP again (either by passing a fd or by terminating and being started). This may not be really useful, but it's just an idea to be noted.
The MCP will bind to port 25 as explained earlier (see Section 2.3) and hand the open socket over to the SMTPS (after changing the uid).
Question: Will this be a (purely) event driven program?
Question: worker model or thread per functionality? It won't be a single process which uses event based programming since this doesn't scale on multi-processor machines. It seems a worker model is more appropriate: it is more general and we might be able to reuse it for other modules, see also Section 3.20.2.
The queue manager doesn't have an external interface. However, it can be configured in different ways for various situations. Todo: and these are?
Such configuration options influence the behavior of the scheduler, the location of the queues, the size of memory caches, etc.
The queue manager will not schedule any delivery attempts any more. It will wait for outstanding connections to terminate unless an immediate shutdown is requested. The incoming queue will be flushed to the deferred queue. Delivery agents are informed by the MCP to stop. The QMGR is waiting for them to terminate and records the delivery status in the deferred EDB.
The status of the queue manager must be accessible from helper programs, e.g., see Section 2.11.1 The QMGR does not provide this as user accessible interface to allow for changing the internal protocols without having to change programs outside sendmail X.
Note: due to the complexity of the QMGR the following sections are not structured as subsection of this one because the nesting becomes too deep otherwise.
The main index to access the deferred EDB will be the time of the next try. However, it is certainly useful to send entries to a host for which a DA has an open connection. Question: what do we use as index to find entries in an EDB to reuse an open connection? An EDB stores canonified addresses or resolved addresses (DA, host, address), it does not store MX records. Those are kept in a different cache (mapping), if they are cached at all. We cannot use the host signature for lookups as sendmail 8 does for piggybacking for the same reason: the host signature consists of the MX records. 8.12 uses an enhanced version for piggybacking, i.e., not the entire host signatures need to match, but only the first. Maybe it is sufficient for selection of entries from an EDB to use the host name (beside all the other criteria as listed in Section 2.4.4.1). The actual decision to reuse a connection is made later on (by the micro scheduler, see Section 2.4.4.3). That decision is based on the host name/IP address and maybe the connection properties, e.g., STARTTLS, AUTH data.
If a DA has an open connection, then that data is added to the outgoing open connection cache (an incoming connection from a host may be taken as hint that the host can also receive mail). The hint is given to the schedulers, which may change their selection strategy accordingly. The first level scheduler can reverse map the host name/IP address to a list of destination hosts that can appear in resolved addresses. Then a scan for those hosts can be made and the entries may be moved upward in the queue.
Question: do we only lookup queue entries for the best MX record (to piggyback other recipients on an open connection)? We could lookup queue entries for lower priority MX records if we know the higher ones are unavailable. It may be a question of available resources (computational as well as network I/O) whether it is useful to perform such fairly complicated searches (and decision processes) to reuse a connection. In some cases it might be simpler (and faster) to just open another connection. However, it might be ``expensive'' to setup a connection, esp. if STARTTLS or something similar is used. A really sophisticated scheduler may take this into account for the decision whether to use an existing connection or whether to open new ones. For example, if the number of open connections is large then it is most likely better to reuse an existing connection. Those numbers (total and per domain) will be configurable (and may also depend on the OS resources).
Question: which host information does the QMGR send to the DA? Only the host from the resolved address tuple (so the DA does MX lookups), the MX list, only one host out of the MX list, or only one IP address? A ``clean'' interface would be to send only the resolved address and let the DA do the MX lookup etc. However, for piggybacking the QMGR needs to know the open connections and it must be able to compare those connections with the entries in the EDB. Hence the QMGR must do the MX expansion (using the AR or DNS helper processes).
Very simple outline of selection of next hop(s) for SMTP delivery:
The MX list and the address list are represented as linked lists, with two different kind of links: same priority, lower priority. This can be either coded as two pointers or as a ``type of link'' value. If we use two pointers then we have to decide whether we fill in both pointers (if a record of that type is available) or only one. For example, let A, B, and C be MX records for a host with value 10, 10, and 20 respectively. Does A have only a (same priority) pointer to B, or does it have pointers to B and C? Is there a case where we do not go sequentially through the list? Maintaining two pointers is more effort which may not give us any advantage at all.
The QMGR provides APIs for the different modules with which it communicates. The two most important interfaces are those to the SMTP server and the delivery agents, the former is discussed in Section 3.4.12.
Question: how does the QMGR control the DAs? That is, who starts a new DA if necessary? This should be the MCP, since it starts (almost) all sendmail X processes. However, what if a DA is already running and the QMGR just wants more? Does the MCP start more or does a DA fork()? Probably the former, which means the QMGR and the MCP must be able to communicate this type of data. Do the DAs terminate themselves after some (configurable) idle time? That should be a configuration option in the MCP control file, see Section 3.3.4.
Question: does the QMGR have each of the following functions per DA or are these generic functions which take the name/type of the DA as argument and are dispatched accordingly?
General side note about (communication) protocols: it seems simpler that the caller generates the appropriate handles instead of the callee. The caller has to pass some kind of token (handle/identifier) anyway to the callee to associate the result it is getting back with the correct data (supplied via the call). If this would be a synchronous call, then the callee could generate the handle, but since we must deal with asynchronous calls, we must either generate the handle ourselves such that the callee can use it to identify the returned data, or the calling mechanism itself must generate the data, which however makes this too complicated.
Create/request a new DA (or maybe several). The properties etc are defined in da-descripton.
Get result(s) from creating/requesting a new DA.
Stop a DA (all DAs of that type).
Get result of stopping a DA.
Open a connection for delivery and send one mail. session contains the destination host to which to connect and some requirements, e.g., STARTTLS, AUTH. If we only want to open a connection, transaction and da-trans-handle can be NULL.
Get results of opening a connection for delivery and sending one mail. The status can be fairly complicated since the operation can fail for various reasons in different stages, see 3.8.4.1.
Perform one delivery (maybe to multiple recipients), transaction contains necessary information for session.
Get results for delivery attempt. This can be a state for the entire transaction, or per recipient depending on the DA and the actual delivery.
Notice: da-session-handle might not be necessary, da-trans-handle is sufficient to identify the transaction. However, an implementation might prefer to get also the session handle.
Close a connection (session).
Get result of closing a connection (session).
Notice: the handles (identifiers) from the DA (da-trans-handle, da-session-handle) are not related to the transaction/session identifiers of SMTPS. That is, we do not ``reuse'' those identifiers except for transaction identifiers for the purpose of logging. We only need those handles to identify the sessions/transactions in SMTPC and QMGR, i.e., to associate the data structures (and maybe threads) that describe the sessions/transactions. We can generate the identifiers in a DA (SMTPC) similarly as in SMTPS; the differences are:
There are several different EDBs in the QMGR: active queue (AQ or ACTEDB), incoming queue (INCEDB; two variants: IBDB: backup on disk and IQDB: in memory only), and main (deferred) queue (DEFEDB). Data must be transferred between those DBs in various situations, e.g., for scheduling data is taken from IQDB or DEFEDB and put into ACTEDB. Doing so involves copying of data and maybe allocating memory for referenced data structures, e.g., mail addresses, and then copying the data from one place (Src) into another (Dst). This problem can be solved in two ways:
Another approach is to use the same data structures for all/most EDBs with an additional type field that defines which data elements are valid. This way copying is either not necessary or can be done almost one-to-one in most cases. The disadvantage of this approach is the potential waste of some memory and fewer chances for typechecks by the compiler (however, more generic functions might be possible). Moreover, the data requirements for incoming and outgoing envelopes are fairly different, so maybe those should be separate data structures.
Maybe only ACTEDB and DEFEDB data structures should be identical, or at least ACTEDB structs should be a superset of DEFEDB structs. Otherwise we need to update entries in DEFEDB by reading the data in (into a structure for DEFEDB), modifying the data (according to the data in ACTEDB), and writing the data out.
Section 2.4.3.3 describes the data flow of envelopes between the various EDB that QMGR maintains, while Section 2.4.3.6 describes the changes required for cut-through delivery. This section specifies the functional behavior for the latter.
If the final data dot is received by the SMTP server, it sends a CTAID record to QMGR including the information that this transaction is scheduled for cut-through delivery. Such an information is given by QMGR in reply to RCPT records: if all of them are flagged by QMGR for cut-through delivery, the transaction is scheduled for it. After receiving CTAID QMGR decides whether the scheduler will go ahead with cut-through delivery. If it doesn't, it sends back a reply code for case 1b below and proceeds as for normal delivery mode. Otherwise all recipients are transferred to AQ immediately, the recipients and the transaction are marked properly and delivery attempts are made. Moreover, a timeout is set for the transaction after which case 1b is selected.
Question: should the data be in some IBDB list too?
For case 1b the SMTP server needs to send another message to QMGR telling it the result of fsync(2). If fsync(2) fails, the message must be rejected with a temporary error, however, QMGR may already have delivered the mail to some recipients, hence causing double deliveries.
To minimize disk I/O an envelope database cache (EDBC) is used
(see Section 3.4.6.2).
As explained in Section
2.4.3.5.1
the cache may not always contain all references to DEFEDB
due to memory restrictions.
Such a restriction can be either artificially enforced
(by specifying a maximum number of entries in EDBC)
or indirectly if the program runs out of memory when trying to
add a new entry to the cache
(see also Section
3.4.17.1).
In that case, the operation mode of reading entries from the
deferred queue must be changed (from cached to disk).
In the disk mode the entire DEFEDB is read at regular intervals
to fill up EDBC with the youngest entries which in turn
are read at the appropriate time from DEFEDB into AQ.
Question: how can those ``read the queue'' operations be minimized?
It is important that EDBC is properly maintained,
it contains the ``youngest'' entries, i.e., all entries in DEFEDB
that are not referenced from EDBC have a ``next time to try'' ![]() that is larger than the last entry in EDBC.
Question: how can this be guaranteed?
Proposal:
when switching from cached to disk
set a status flag to keep track of the mode,
and store the maximum
that is larger than the last entry in EDBC.
Question: how can this be guaranteed?
Proposal:
when switching from cached to disk
set a status flag to keep track of the mode,
and store the maximum ![]() in
in ![]() .
When inserting entries into EDBC, ignore everything that has
a
.
When inserting entries into EDBC, ignore everything that has
a ![]() greater then
greater then ![]() .
If entries are actually added (
.
If entries are actually added (![]() )
and hence older entries are removed, set a new
)
and hence older entries are removed, set a new ![]() .
Perform a DEFEDB scan when EDBC is empty
or below some threshold,
e.g., only filled up to ten per cent and
.
Perform a DEFEDB scan when EDBC is empty
or below some threshold,
e.g., only filled up to ten per cent and
![]() .
If all entries from DEFEDB can be read, reset the mode to cached.
.
If all entries from DEFEDB can be read, reset the mode to cached.
In case of an unclean shutdown there might be open transactions in IBDB. Hence on startup the QMGR must read the IBDB files and reconstruct data as necessary. The API for IBDB is specified in Section 3.13.4.3. It allows an application to read all records from the IBDB. To reconstruct the data, the function sequentially reads through IBDB and stores the data in an internal data structure (in the following called RecDB: Reconstruction DB)that allows access via transaction/recipient id. The entries are ordered, i.e., the first entry for a record has the state open, the next entry has the state done (with potentially more information, e.g., delivered, transferred to DEFEDB due to a temporary/permanent failure, or cancelled). The second entry for a record might be missing which indicates an open transaction that must be taken care of. For each done transaction the corresponding open entry is removed from RecDB. After all records have been read RecDB contains all open transactions. These must be added to DEFEDB or AQ. If they are added only to the latter, then we still need to keep the IBDB files around until the transactions are done in which case a record is written to IBDB. This approach causes problems if the number of open transactions exceeds the size of AQ in which case an overflow mechanism must set in, e.g., either delaying further reading of IBDB or writing the data to DEFEDB. In the first sendmail X version the data should be transferred to DEFEDB instead for simplicity. Even with this simpler approach there are still some open problems:
About 1: If yes, a faster startup time is achieved since the QMGR does not need to wait for the reconstruction. This of course causes other problems, e.g., what to do if the reconstruction runs into problems3.4? There are further complications with the order of operations: the reconstruction must be performed before the new IBDB is opened unless either a different name is used or the sequence numbers start after the last previously used entry. In the former case some scheme must be used to come up with names that will not cause problems if the system goes down while the reconstruction is still ongoing. In the latter case the problem of a wrap-around must be dealt with, i.e., what happens if the sequence number reaches the maximum value? A simple approach would be to simply start over at 1 again, but then it must be avoided that those files are still in use (which seems to be fairly unlikely if for example a 32 bit unsigned integer is used because the number of files would be huge, definitely larger what is sane to store in a single directory3.5).
A potential solution to the problem of overlapping operation is to use different sets of files, e.g., two different directories: ibdbw for normal operation, ibdbr for recovery. In that case at startup the following algorithm is used: If both ibdbw and ibdbr exist then the recovery run from the last startup didn't finish properly. Hence the rest of QMGR is not started before completing recovery, i.e., asynchronous operation is only allowed if the previous recovery succeeded. This simple approach allows us to deal with recovery problems without introducing an unbound number of IBDB file sets (directories). If only ibdbw exists, then rename it to ibdbr and let the QMGR startup continue while recovery is running. After recovery finished, ibdbr is removed thus indicating successful recovery for subsequent startups.
This approach can be extended to deal with a cleanup process that ``compresses'' IBDB files by removing all closed transactions from them. This cleanup process uses a different directory ibdbc in which it writes open transactions similar to the recovery program. That is, it reads IBDB files from ibdbw, gets rid of closed transaction in the same way as the recovery function does and writes the open transactions into a new file. After this has been safely committed to persistent storage, the IBDB files that have been read can be removed. The recovery function needs to read in this case the files from ibdbw and ibdbc to reconstruct all open transactions. The cleanup process should minimize the amount of data to read at startup. Such a cleanup function may not be available in sendmail X.0, however, if the MTA runs for a long time it may require a lot of disk space if there is not cleanup task. Question: is cleaning up a recursive process? If so, how to accomplish that? In a simple approach two ``versions'' can be used between which the cleanup task toggles, i.e., read from version 1 and write to version 2, then switch: read from version 2 and write to version 1. Question: how easy is it to keep track of this?
An example of the missing data mentioned as problem 2 in the list of problems is the start time (of the transaction) which is not recorded. This can be either taken in first approximation from the creation time of the IBDB file, or the current time can be simply used (which might be off by a fair amount if the system is down for a longer time, which, however, should not happen).
Question: is there a way to avoid writing data when cleaning up IBDB? The cleanup task could ``simply'' remove IBDB files that contain only references to closed transactions. We may not even have to read any IBDB files at all since the data can be stored in IQDB, i.e., a reference to the IBDB logfile (sequence number). This requires a reference counter for each IBDB logfile which contains the number of open transactions (TA/RCPTs). When both reference counters reach zero the logfile can be removed. Note: this violates the modularity: now IQDB is used to store data that is related to the implementation of IBDB, i.e., both are tied together. Currently IQDB is fairly independent of the implementation of IBDB, e.g., it does not know about sequence numbers. Now there must a way to return those numbers to IBDB callers and they must be stored in IQDB. Moreover, there are functions that do not allow for a simple way to do this, e.g., those which act on request lists. In this case it would be fairly complicated to associate the IBDB data with the IQDB data. However, at the expense of memory consumption, the data could be maintained by the IBDB module itself. In this case it behaves similar as the IBDB recovery program, i.e., it stores open transactions (only a subset of data is necessary: identifier and sequence number) in an internal (hash) table, and matches closed transactions against existing entries to remove them. Periodically it can scan the table to find out which sequence numbers are still in use and remove unused files.
A different (simpler?) approach to the problem is to use time-based cleanup. Open transactions that are stored in IBDB are referenced by IQBD (at least with the current implementation) or AQ (entries which are marked to come from IQDB). Periodically these entries can be scanned to find the oldest. All older IBDB logfile can be removed. Note: there should be a correctness proof for this before it is implemented.
An interesting question is in which format recipient addresses are stored in the EDB, i.e., whether only the original recipient address is stored or whether also the resolved format (DA, host, address, etc) is stored too. If we use the resolved (expanded) format then we need to remove/invalidate those in case of reconfigurations. These reconfigurations may change DAs or routing. A possible solution is to add a time stamp to the resolved form. If that time stamp is older than the last reconfiguration then the AR must be called again. However, the routing decision may have been based on maps which have changed inbetween, hence this isn't a complete solution. It may require a TTL based on the minimum of all entries in maps used for the routing decision. Alternatively we can keep the resolved address ``as-is'' and do not care about changes. For examples, some address resolution steps happen in sendmail 8 before the address is stored in the queue, some happen afterwards. Examples for the former are alias expansion, which certainly should not be done every time. So the only address resolution that happens during delivery are DNS lookups (MX records, A/AAAA records), and those can be cached since they provide TTLs. We might make the address resolution a clean two step process:
It might be an interesting idea to provide a cache of address mappings. However, such a cache cannot be simply for domains since it might be possible to provide per-address routing. The cache may be for DNS (MX/A/AAAA) lookups nevertheless, i.e., a ``partially'' resolved address maps to a domain which in turn maps to a list of destination hosts. This is fairly much what sendmail 8 does:
These two steps are clearly related to the two steps listed above.
Incomplete (as of now) summary: Advantages of storing resolved addresses:
Disadvantages of storing resolved addresses:
If an address ``expires'' earlier than the computed ``next time to try'' then it probably is not useful to store the resolved address in DEFEDB. However, if the scheduler decides to try the address before the ``next time to try'', e.g., because a host is available again, then the resolved address might still be useful.
See also Section 3.4.15 for further discussion of this problem.
We also need to mark addresses (similar to sendmail 8 internally) to denote their origin, i.e., original recipient, expanded from alias (alias or list), etc.
As described in Section 2.4.7 the scheduler must control the load it generates.
One of the algorithms the scheduler should implement is ``slow start'', i.e., when a connection to a new host is created, only a certain number of initial connections must be made (``initial concurrency''). When a session/transaction has been succesful, the number of allowed concurrent connections can be increased (by one for each successful connection) until an upper limit (``maximum concurrency'') is reached. This varying number of concurrency is usually called ``window'' (see TCP/IP). If a connection fails, the size of the window is decreased until it reaches 0 in which the destination host is declared ``dead'' (for some amount of time).
Question: which kind of failures should actually decrease the window size besides any kind of network I/O errors? For example, a server may respond with 452 Too many connections but smX will not try to interpret the text of the reply, only the reply code.
The queue manager uses several data structures to store the status of the system and the envelopes of mails for which it has to schedule delivery. These are listed in the next sections.
Question: are the connection caches indexed on host name or IP address? Problem: there is no 1-1 relation between host names and IP addresses, but an N-M relation. This causes problems for finding recipients to send over an open connection. A recipient address is mapped to (a DA and) a destination host, which is mapped to a list of MX records (host names) which in turn are mapped to IP addresses. Since there can be multiple address records for a host name and multiple PTR records for an IP address, we have a problem. The general problem is what to use as index for the connection caches. A smaller problem results from the expiration (TTL) of DNS entries (all along the mapping: MX, A/AAAA, and PTR records). Question: do load balancers further complicate this or can we ignore them for our purposes? Possible solution: use host name as index, provide N-M mappings for host name to IP address and vice versa. These mappings are provided by DNS. A simpler (but more restrictive solution) is to use the IP address and the host name together as index (see Exim [Haz01]). Question: do we want our own (simpler) DNS interface? We need some (asynchronous) DNS ``helper'' module anyway, maybe that can add some caching and a useful API? We shouldn't replicate caches too often due to the programming and memory usage overhead. So how do we want to access the connection caches? If a host name maps to several IP addresses, must it be a single machine? Does it matter wrt SMTP? Is a host down or an IP address? It could be possible that some of the network interfaces are down, but the host still can receive e-mail via another one.
So the QMGR to DA interface should provide an option to tell the DA to use a certain IP address for a delivery attempt because the QMGR knows the DA has an open connection to it. Even though this is a slight violation of the abstraction principle, the QMGR scheduled this delivery because of the connection cache, so it seems better than letting the DA figuring out to use one of its open connection (by looking up addresses etc).
Problem: a connection (session) has certain attributes, e.g., STARTTLS, AUTH restrictions/requirements. These session-specific options can depend on the host name or the IP address (in sendmail 8: TLS_Srv:, AuthInfo:). This makes it even more complicated to reuse a connection. If a host behaves differently based on under which IP address it has been contacted, or if different requirements are specified for host name/IP addresses then connection reuse is significantly more complicated. In the worst case this could result in bounces that happen only in certain situations. It is certainly possible to document this behavior on the sendmail side, but if the other (server) side has a connection information dependent behavior then we have a problem.
A connection is made to an IP address, the server only knows the client IP address (plus port, plus maybe ident information, the latter should not be used for anything important). SMTP doesn't include a ``Hi, I would like to speak with X'' greeting, but only a ``Hi, this is Y'' (which might be considered a design flaw), so the server can't change its behavior based on whom the client wants to speak to (which would be useful for virtual hosting), but only based on the connection information (IP addresses, ports). Hence when a connection is reused (same IP address) the server can't change its behavior. Problem solved? Not really, someone could impose wierd restrictions based on sender addresses. It seems to be necessary to make this configurable (some external map/function can make the decision). This probably can be achieved by imposing a transactions per session limit, see also Section 2.4.8.
Another solution might be to base connection reuse on host name and IP address3.6. This may restrict connection reuse more than necessary, but it should avoid the potential problems. Maybe that should be a compile time option? Make sure that the code does not depend completely on the type of the index.
There have been requests to perform SMTP AUTH based on the sender address. which of course invalidates connection reuse. It's one (almost valid) example for additional requirements for a connection. It's only almost valid, since SMTP AUTH between MTAs is not for user authentication, it is used to authenticate the directly communicating parties. However, SMTP AUTH allows some kind of proxying (authenticate as X, authorize to act as Y), which seems to be barely used.
Note: connection reuse requires that the delivery agent is the same, if two recipients resolve to different delivery agents -- even for the same IP address and hostname -- then the connection will not be reused. In some cases this seems rather useless3.7hence the maximum flexibility would be reached by establishing congruence classes of mailer with respect to connection reuse. If then not just the mailer definitions are used to create those classes but also some connection attributes (see begin of this section), then we may have found the right approach to connection reuse.
See Section 2.4.6 for the different types of DSNs and the problems we may encounter. We need to store (at least?) three different counters as explained in Section 2.4.6.1. DSNs can be requested individually for each recipient. Hence the sum of these counters is less than or equal the number of original recipients. Question: could it ever increase due to alias expansion? We could store the number of requested DSNs for each type and then compare the number of generated DSNs against them. If any of the generated DSN counters reached the requested counter we can schedule the DSN for delivery and hence we can be sure (modulo the question above) that all DSNs of the same type can be merged into one. Question: do we really need those counters? Or do we just generate a DSN whenever necessary and schedule it for delivery (with some delay)? Then the DSN generation code could look whether there is already a DSN generated and add the new one to it, as far as this is possible since the scheduler has to coalesce those DSNs. Problem: there is extra text (the error description) that should be put into one mail. How to do this? See also Section 2.4.6 about the question how to generate the body of DSNs.
As explained in Section 2.4.1, the incoming queue consists of two parts: a restricted size cache in memory and a backup on disk.
The incoming queue does not (need to) have the same amount of data as the SMTP servers. It only stores data that is relevant to the QMGR. There is even less information in the data that is written to disk when an entry has been received. The data in the RSC is not just needed for delivery, but also during mail reception for policy decisions. In contrast, the backup data is only there to reconstruct the incoming cache in case of a system crash, i.e., the mail has already been received, there will not be any policy decisions about it. Hence the backup stores only the data that is required for delivery, not the data that is necessary to make decision while the mail is being received. This of course means that a reconstructed RSC does not contain the same (amount of) information as the original RSC.
The size of the cache defines the maximum number of concurrently open sessions and transactions in the SMTP servers. Question: do we store transactions and recipients also in fixed size caches? We certainly have to limit the size used for that data, which then acts as an additional restriction on the number of connections, transactions, and recipients. It's probably better to handle at least the recipients dynamically instead of pre-allocating a fixed amount of memory. The amount of memory must be limited, but it should be able to shrink if it has been expanded during a high volume phase (instead of having some maximum reserved all the time). Since most of the information in the cache is not fixed size, we need to dynamically allocate memory anyway. We maybe need some special kind of memory allocation for this which works within a given allocated area (see also Section 3.16.6).
Each entry in the cache has one of the following two formats (maybe use two different RSC):
Session
| session-id | session identifier |
| client-host | identification of connecting host |
| IP address, host name, ident | |
| features | features offered: AUTH, TLS, EXPN, ... |
| workarounds | work around bugs in client (?) |
| transaction-id | current transaction |
| reject-msg | message to use for rejections (needed?) |
| auth | AUTH information |
| starttls | TLS information |
| n-bad-cmds | number of bad SMTP commands |
| n-transactions | number of transactions |
| n-rcpts | total number of recipients |
| n-bad-rcpts | number of bad recipients |
Transaction:
| transaction-id | transaction identifier |
| start-time | date/time of transaction |
| address, arguments (decoded?) | |
| n-rcpts | number of recipients |
| rcpt-list | addresses, arguments (decoded?) |
| cdb-id | CDB identifier (obtained from cdb?) |
| msg-size | message size |
| n-bad-cmds | number of bad SMTP commands (necessary?) |
| n-rcpts | number of valid recipients |
| n-bad-rcpts | number of bad recipients |
| session-id | (pointer back to) session |
| statistics: | |
| end-time | end of transaction |
If recipients addresses are expanded while in the INCEDB, we need to store the number of original recipients too.
Backup on disk: those entries have a different format than the in-memory version. The entries must be clearly marked as to what they are: transaction sender or recipient.
Sender (transaction):
| transaction-id | transaction identifier |
| start-time | start time of transaction |
| sender-spec | address incl. ESMTP extensions |
| cdb-id | CDB identifier (obtained from cdb?) |
| n-rcpts | reference count for cdb-id |
Notice: the sender information is written to disk after all recipients have been received, i.e., when DATA is received, because it contains a counter of the recipients (reference count).
ESMTP sender extensions (substructure of the structure above)
| size | size of mail content (SIZE=) |
| bodytype | type of body |
| envid | envelope id |
| ret | DSN return information (FULL, HDRS) |
| auth | AUTH parameter |
| by | Deliverby specification |
Per recipient (transaction):
| transaction-id | transaction identifier |
| rcpt-spec | address incl. ESMTP extensions |
| and maybe a unique id (per session/transaction?) |
ESMTP Recipient extensions (substructure of the structure above):
| notify | DSN parameters (SUCCESS, FAILURE, WARNING) |
| orcpt | original recipient |
The data for sender and recipient should be put into a data structure such that all relevant data is kept together. That structure must contain the data that must be kept in (almost) all queues.
The active queue needs different types of entries, hence it might be implemented as two RSCs, i.e., one for senders and one for recipients3.8. It could also be only one RSC if the ``typed'' variant is used (see 4.3.5.1).
Notice: there are two types of transaction records:
The AQ context itself contains some summary data and the data structures necessary to access transactions and recipients:
| max-entries | maximum number of entries |
| limit | current limit on number of entries |
| entries | current number of entries |
| t-da | entries being delivered |
| nextrun | if set: don't run scheduler before this time |
| tas | access to transactions |
| rcpts | access to recipients |
There should probably be more specific counters: total number of recipients, number of recipients being delivered, number of recipients waiting for AR, number of recipients ready to be scheduled, and total number of transactions.
The incoming transaction context contains at least the following fields:
| transaction-id | SMTPS transaction identifier |
| sender-spec | address (see INCEDB) |
| cdb-id | CDB identifier |
| from-queue | from which queue does this entry come? (deferred or incoming) |
| counters | several counters to keep track of delivery status |
For ACTEDB we only need to know how many recipients are referenced by this transaction in the DB itself. That is, when we put a new recipient into ACTEDB, then we need to have the sender (transaction) context in it. If it is not yet in the queue, then we need to get it (from INCEDB or ACTEDB) and initialize its counter to one. For each added recipient the counter is incremented by one, when the status of a recipient delivery attempt is returned from a DA, the counter is decremented by one and the recipient is taken care of in the appropriate way. See also 2.4.3.4. However, because AQ should contain all necessary data to update DEFEDB it must also store the overall counters, e.g., how many recipients are in the system in total (not just in AQ).
Note: the delivery status for a transaction is not stored in DEFEDB since each delivery attempt in theory may lead to a different transaction, i.e., a DA transaction is not stored in DEFEDB.
The recipient context in AQ contains at least the following elements:
| SMTPS transaction-id | SMTPS transaction identifier |
| DA transaction-id | DA transaction identifier |
| rcpt-spec | address (see INCEDB) |
| rcpt-internal | delivery tuple (DA, host, address) |
| from-queue | from which queue does this entry come? |
| status | not yet scheduled, being delivered, (temp) failure, ... |
| SMTPS-TA | recipient from same SMTPS transaction |
| DA-TA | recipient in same DA transaction |
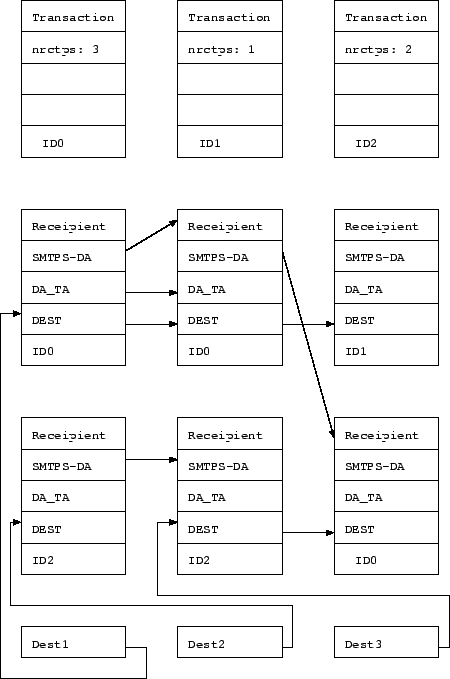
| DEST | recipient for same destination |
The last three entries are links to access related recipients. These are used to group recipients based on the usual criteria, i.e., same SMTPS transaction, same delivery transaction, same next hop. Maybe this data can also be stored in DEFEDB to pull in a set of recipients that belongs together instead of searching during each scheduling attempt for the right recipients that can be grouped into a single transaction. Questions: how to do this? Is it worth it?
The internal recipient format is the resolved address returned by the AR. Its format is explained in Section 3.6.3.1.
As explained in 3.4.4, several access methods are required for the various EDBs, those for AQ are:
The key described in item 3 refers to another data structure which summarizes the entries. This data structure is the ``head'' of the DEST list:
| DA | Delivery Agent |
| next-hop | Host (destination/next hop) to which to connect for delivery |
| todo-entries | Number of entries in todo-list |
| todo-list | Link to recipients which still need to be sent |
| busy-entries | Number of entries in busy-list |
| busy-list | Link to recipients which are being sent |
The number of waiting transactions (todo-entries) can be used to determine whether to keep a session open or close it.
Question: is it really useful to have a busy list? What's the purpose of that list, which algorithms in the scheduler need this access method? The number of entries in the busy list is somehow useful if it were the number of open transactions or sessions, however, this is the number of recipients which does not have a useful relation to transactions/sessions.
Note: when a recipient is added to AQ it may not be in these destination queues because its next hop has not yet been determined, i.e., the address resolver needs to be called first. Those entries must be accessible via other means, e.g., their unique (recipient) identifier (see item 1 above). It might also be possible (for consistency) to have another queue with a bogus destination (e.g., a reserved DA value or IP address) which contains the entries whose destination addresses have not yet been resolved. Section 3.4.4 explains some of the problems with chosing indices to access AQ (and other EDBs), there is an additional problem for AQRD: if the connection limit for an IP address is reached, the scheduler will skip recipients for that destination. However, the recipient may have other destinations with the same priority whose limit is not yet reached. Either the system relies on the randomization of those same priority destinations (real randomization in turn causes problems for session reuse), or some better access methods need to be used. It might be useful in certain cases to look through the recipient destinations nevertheless (which defeats the advantage of this organization to easily skip entries that cannot be scheduled due to connection limits).
There might be yet another data structure which provides a summary of the entries in DEFEDB of this kind. That data structure can be used to decide whether to pull in recipients from DEFEDB to deliver them over an open connection.
The QMGR/scheduler must also remove entries from AQ that are too long in the queue, either because AR didn't respond or because a delivery attempt failed and the DA didn't tell QMGR about it (see Section 2.4.4.5). Question: what is an efficient way to do this? Should those entries also be in some list, organized in the order of timeout? Then the scheduler (or some other module) just needs to check the head of the list (and only needs to wake up if that timeout is actually reached). When an item is sent to AR or a DA then it must be sorted into that list.
The entries must be clearly marked as to what they are: transaction sender or recipient.
Sender:
| transaction-id | transaction identifier |
| start-time | date/time mail was received |
| sender-spec | address (see INCEDB) |
| cdb-id | CDB identifier |
| rcpts-left | reference count for cdb-id |
| rcpts-tried | counter for ``tried'' recipients |
rcpts-left refers to the number of recipients which somehow still require a delivery, whether to the recipient address or a DSN back to the sender. rcpts-tried is used to determine when to send a DSN (if requested). It might be useful to have counters for the three different delivery results: ok, temporary/permanent failure:
| rcpts-total | total number of recipients |
| rcpts-left | number of recipients left |
| rcpts-temp-fail | number of recipients which temporary failed |
| rcpts-perm-fail | number of recipients which permanently failed |
| rcpts-succ | recipients which have been delivered |
In case of a DELAY DSN request we may need yet another counter. See also Sections 2.4.6 and 3.4.10.3.
rcpts-total is at least useful for statistics (logging); one of rcpts-succ and rcpts-total may be omitted. The invariances are:
![]()
rcpts-total also counts the bounces that have been generated. It is never decremented.
![]()
Notice: these counters must be only changed if the delivery status of a recipient changes. For example, if a recipient was previously undelivered and now a delivery caused a temporary failure, then rcpts-temp-fail is increased. However, if a recipient previously caused a temporary failure and now a delivery failed again temporarily, then rcpts-temp-fail is unchanged. This obviously requires to keep the last delivery status for each recipients (see below).
Recipient:
| transaction-id | transaction identifier |
| rcpt-spec | address (see INCEDB) |
| rcpt-internal | delivery tuple (DA, host, address, timestamp) |
| d-stat | delivery status (why is rcpt in deferred queue) |
| schedule | data relevant for delivery scheduling, e.g., |
| last-try: last time delivery has been attempted | |
| next-try: time for next delivery attempt |
d-stat must contain sufficient data for a DSN, i.e.:
| act-rcpt | actual recipient (?) |
| orig-rcpt | original recipient (stored in rcpt-spec, see above) |
| final-rcpt | final recipient (from RCPT command) |
| DSN-status | extended delivery status code |
| remote-mta | remote MTA |
| diagnostic-code | actual SMTP code from other side (complete reply) |
| last-attempt | data/time of last attempt |
| will-retry | for temporary failure: estimated final delivery time |
The internal recipient format is the resolved address returned by the AR. Its format is explained in Section 3.6.3.1. Question: do we really want to store rcpt-internal in DEFEDB? See Section 3.4.8 for a discussion. The timestamp for the delivery tuple is necessary as explained in the same section.
Question: which kind of delivery timestamp is better: last time a delivery has been attempted or time for next delivery attempt? We probably need both (last-try for DSN, next-try for scheduling).
EDBC implements a sorted list based on the ``next time to try''. with references to recipient identifiers (which are the main indices to access DEFEDB). ``Next time to try'' is not a unique identifier hence this structure must be aware of that, e.g., when adding or removing entries.
This cache is accessed via IP addresses and maybe hostnames. It is used to check whether an incoming connection (to SMTPS) is allowed (see also Section 2.4.7).
| open-conn | number of currently open connections |
| open-conn-X | number of open connections over last X seconds |
| (probably for X in 60, 120, 180, ...) | |
| trans-X | number of performed transactions over last X seconds |
| rcpts-X | number of recipients over last X seconds |
| fail-X | number of SMTP failures over last X seconds |
| last-conn | time of last connection |
| last-state | status of last connection, see 3.4.10.9 |
Notice: statistics must be kept in even intervals, otherwise there is no way to cycle them as time goes on.
Question: do we use a RSC for this? If so, how do we handle the case when the RSC is full? Just throwing out the least recently used connection information doesn't seem appropriate.
Question: what kind of status do we want to store here? Whether the connection was succesfull, or aborted by the sender? Or whether it acted strange, e.g., caused SMTP violations? Maybe performance related data? For example, number of recipients, number of transactions, throughput, and latency.
As explained in Section 2.4.4.8, there are two different connection caches for outgoing connections: one for currently open connections (OCC, 1) and one for previously made (tried) connections (DCC, 2). These two connection caches are described in the following two subsections.
Note: it might be possible to merge these two caches into one if the proper implementation, such as a restricted size cache (see Section 3.13.10), is chosen.
This is OCC (see Section 2.4.4.8: 1) for the currently open (outgoing) connections.
OCC helps the scheduler to perform its operation, it contains summary information (and hence could be gathered from the AQ/DA data by going through the appropriate entries3.9).
| open-conn | number of currently open connections |
| open-conn-X | number of open connections over last X seconds |
| (probably for X in 60, 120, 180, ...) | |
| trans-X | number of performed transactions over last X seconds |
| rcpts-X | number of recipients over last X seconds |
| fail-X | number of failures over last X seconds |
| performance | data related to performance, see 3.13.8 |
| first-conn | time of first connection |
| last-conn | time of last connection |
| last-update | time of last status update |
| last-state | status of last connection, see 3.4.10.11 |
| initial-conc | initial concurrency value |
| max-conc | maximum concurrency limit |
| cur-conc | current concurrency limit (``window'') |
This connection cache stores only information about current connections. The connection cache also stores the time of the last connection. Question: do we need to store a list of those times, e.g., the last three? We can use these times to decide when a new connection attempt should be made (if the last connection failed). For this we need at least the last connection time and the time interval to the previous attempt. If we use exponential backup we need only those two values. For more sophisticated methods (which?) we need probably more time stamps.
It is not yet clear whether the open connection cache actually needs the values listed above, especially those for ``over last X seconds''. Unless the scheduler actually needs them, they can be omitted (they might be useful for logging or statistics). Instead, the counters may be for the entire ``lifetime'' of the connection cache entry; those counters can be used to implement limits for the total number of sessions, transactions, recipients, etc.
The last three values are used to implement the slow-start algorithm, see 3.4.9.1. The time of the last status update can be used to expire the ``host is dead'' marking, i.e., cur-conc equal zero.
Question: which times do we actually need: the time of the last connection or last status update? If a connection is successful, but the session takes very long, those times may differ substantially. The time of the last status update is used to expire a ``host is dead'' marking (as explained in the previous paragraph). The time of the last connection might be used to expire an entry if something went wrong with the delivery agent, e.g., it ``died'' in some way such that QMGR does not notice it and hence cannot clean up properly. In this case the expiration timeout should depend on the message size, obviously it takes much longer to deliver a message of several MB than of a few KB. The timeout could be set as the some of a basic timeout (60s?) and the message size divided by the transfer rate, where transfer rate is an option set in a configuration file (and maybe checked against the ``performance'' values for this entry).
This is DCC (see Section 2.4.4.8: 2) for previously open connections. It contains similar data as OCC but only for connections which are not open anymore.
| open-conn-X | number of open connections over last X seconds |
| (probably for X in 60, 120, 180, ...) | |
| trans-X | number of performed transactions over last X seconds |
| rcpts-X | number of recipients over last X seconds |
| fail-X | number of failures over last X seconds |
| performance | data related to performance, see 3.13.8 |
| last-conn | time of last connection |
| last-update | time of last status update |
| last-state | status of last connection, see 3.4.10.11 |
The connection cache also stores the time of the last connection. Question: do we need to store a list of those times, e.g., the last three? We can use these times to decide when a new connection attempt should be made (if the last connection failed). For this we need at least the last connection time and the time interval to the previous attempt. If we use exponential backup we need only those two values. For more sophisticated methods (which?) we need probably more time stamps.
This connection cache can be optimized to ignore some recent connections at the expense of being limited in size. For example, see the BSD inetd(8) ([ine]) implementation which uses a fixed-size hash array to store recent connections. If there are too many connections, some entries are simply overwritten (least recent entry will be replaced).
See Section 3.8.4.1 for a delivery status that must be stored in the appropriate entries. Question: where do we store the status? We store it on a per-recipient basis in the EDB and on a per-host (or whatever the index will be) basis in the connection cache. The delivery status will be only stored in the connection cache if it pertains to the connection. For example, ``Recipient unknown'' is not stored in that cache. The delivery status should reflect this distinction easily. Question: is it useful to create groups of recipients, i.e., group those recipients within an envelope that are sent to the same host via the same DA? This might be useful to schedule delivery, but should we create extra data types/entries for this?
It must also be stored whether currently a connection attempt is made. This could be denoted as one open connection and status equal ``Opening'' (or something similar).
Question: how much should the QMGR control (know about) the status of the various DAs? Should it know exactly how many are active, how many are free? That seems to be useful for scheduling, e.g., it doesn't make sense to send a delivery task to a DA which is completely busy and unable to make the delivery attempt ``now'', i.e., before another one is finished. Hence we need another data structure that keeps track of each available DA (each ``thread'' in it, however, this should be abstracted out; all the QMGR needs to know is how many DAs are available and what they are doing, i.e., whether they are busy, idle, or free3.10). The data might be hierarchically organized, e.g., if one DA of a certain type can offer multiple incarnations, then the features of the DA should be listed in one structure and the current status of the ``threads'' in a field (or list or something otherwise appropriate). Some statistics need to be stored too which can be used to implement certain restrictions, e.g., limit the number of transactions/recipients per session, or the time a connection is open.
| status | busy/free (other?) |
| DA session-id | DA session identifier |
| DA transaction-id | DA transaction identifier |
| SMTPS transaction-id | SMTPS transaction identifier |
| server-host | identification of server: IP address, host name |
| n-trans | number of performed transactions |
| n-rcpts | number of recipients |
| n-fail | number of failures |
| performance | data related to performance, see 3.13.8 |
| opened | time of connection open |
| last-conn | time of last connection |
Question: what do we use as index to access this structure? We could use a simple integer DA-idx (0 to max threads-1), i.e., a fixed size array. Then however we should also use that value as an identifier for communication between QMGR and DA, otherwise we still have to search for session/transaction id. Nevertheless, using an integer might give us the wrong idea about the level of control of the QMGR over the DA, i.e., we shouldn't assume that DA-idx is actually useful as an index in the DA itself.
Notice: this is the only place where we store information about a DA session, the active queue contains only mail and recipient data. Hence we may have to store more information here. This data structure is also used for communication between QMGR and DAs; it associates results coming back from DAs (which use DA session/transaction ids) with the data in AQ (which use SMTPS session/transaction ids).
One simple approach is to check how much storage resources are used, e.g., how full are AQ, IQDB, etc, as well as disk space usage. However, that does not take into account the ``load'' of the system, i.e., CPU, I/O, etc.
Various DBs are stored on disk: CDB, DEFEDB, and IBDB. The latter two are completely under control of QMGR, the former is used by SMTPS (write), DA (read), and QMGR (unlink). The amount of available disk can be stored in a data structure and updated on each operation that influences it. Additionally system calls can be made periodically to reflect changes to the disk space by other processes. About CDB: SMTPS should pass the size of a CDB entry to QMGR which then can be used when a transaction is accepted and when all recipients for a transaction have been delivered and hence the CDB entry is removed.
sendmail 8.12 uses a data structure to associate queue directories with disk space (``partitions''). A similar structure can be used for smX.
struct filesys_S {
dev_t fs_dev; /* unique device id */
long fs_kbfree; /* KB free */
long fs_blksize; /* block size, in bytes */
time_T fs_lastupdate; /* last time fs_kbfree was updated */
const char *fs_path; /* some path in the FS */
};
For internal (memory resident) DBs it is straightforward to use the number of entries in the DB as a measure for its usage. This number should be expressed as percentage to be independent of the actual size chosen at runtime. Hence the actual usage of a DB can be represented as a single number whose value ranges from 0 to 100.
See Section 3.13.3 for more information about envelope databases, esp. APIs.
Notice: these functions are ``called'' from SMTPS (usually via a message), hence they do not have a corresponding function that returns the result. The functions may internally wait for the results of others, but they will return the result ``directly'' to the caller, i.e., via a notification mechanism. The other side (SMTPS) may use an asynchronous API (invoke function, ask for result) as explained in Section 3.1.1.
Maybe qmgr_trans_close() and qmgr_trans_discard() can be merged into one function which receives another parameter: qmgr_trans_close(IN trans-id, IN cdb-id, IN smtps-status, OUT status) that determines whether SMTPS has accepted so mail so far; the QMGR can still return an error.
See Section 2.4.4.2 for a description of the tasks of the first level scheduler. This part of the QMGR adds entries to the active queue, whose API is described in Section 3.13.5.
qmgr_fl_getentries(IN actq, IN incq, IN defq, IN number, IN policy, OUT status) get up to a certain number of entries for the active queue.
qmgr_fl_get_inc(IN actq, IN incq, IN number, IN policy, OUT status) get up to a certain number of entries for the active queue from the incoming queue.
qmgr_fl_get_def(IN actq, IN defq, IN number, IN policy, OUT status) get up to a certain number of entries for the active queue from the deferred queue.
qmgr_fl_get_match(IN actq, IN number, IN criteria, OUT status) get some entries for the active queue from the deferred queue that match some criteria, e.g., items on hold with a matching hold message, or items for a certain domain. We may want different functions here depending on what a user can request. But we also want a generic function that can get entries depending on some conditions that can fairly freely specified.
See Section 2.4.4.3 for a description of the tasks of the second level (micro) scheduler. This part of the QMGR controls the active queue, whose API is described in Section 3.13.5. It uses the first level scheduler to fill the active queue whenever necessary, and the DA API (3.4.5.1) to request actual deliveries.
Question: which additional functions do we need/want here?
Whenever a delivery attempt has been made, the status will be collected and an appropriate update in the main (or incoming) queue must be made.
Common to all cases is the handling of DSNs. If a particular DSN is requested and the conditions for that DSN are fulfilled, then the recipient is added to the DSN for that message (based on the transaction id of the received message). If there is no DSN entry yet, then it will be created. If all entries for the particular DSN have been tried, ``release'' (schedule) the DSN to be sent. See also Section 2.4.6. Question: do DSN cause new entries in the main queue or do we just change the type of the recipient entry?
If the entry will be tried later on, i.e., the queue return timeout isn't reached, then determine the next time for retry. Update the entry in the deferred queue (this may require moving the entry from the incoming cache to the deferred queue).
The AR API is briefly described in Section 3.6.3. An open question is when the QMGR should call the AR. There are at least the following possibilities:
The SMAR may expand aliases in which case it can return a list of (resolved) addresses. The QMGR must make sure that the new addresses are either safely stored in persistent storage or that the operation is repeatable. The simple approach is to store the new addresses in DEFEDB after they have been received from SMAR and remove the address which caused the expansion from the DB in which it is stored3.11(IBDB or DEFEDB). If the new addresses are stored only in AQ, then the handling becomes complicated due to potential delivery problems and crashes before all expanded addresses have been tried. The expansion would be done in a two step process:
Note: the design requires that all data in AQ can be removed (lost) at any time without losing mail.
If QMGR is terminated between step one and two, the alias expansion will be repeated the next time the (original) address is selected for delivery. If QMGR is terminated during step two, i.e., the delivery of expanded addresses, then this approach may result in multiple deliveries to the same recipient(s). Note: the current functions to update the recipient status after a delivery attempt do not yet deal with recipients resulting from an alias expansion.
For 1-1 aliases it seems simplest to replace the current address with the new one, which avoids most of the problems mentioned above3.12.
In a first step
1-![]() (
(![]() ) alias expansion should be done by writing all data to DEFEDB.
Later on optimizations can be implemented, e.g., if
) alias expansion should be done by writing all data to DEFEDB.
Later on optimizations can be implemented, e.g., if ![]() is small,
then the expansion is done in AQ only.
is small,
then the expansion is done in AQ only.
When a delivery attempt (see 4d in Section 2.4.3.2) has been made, the recipient must be taken care of in the appropriate way. Note that a delivery attempt may fail in different stages (see Section 2.4.3.1), and hence updating the status of a recipient can be done from different parts of QMGR:
See Section 2.4.3.4 for a description what needs to be done after a delivery attempt has been made. As mentioned there it is recommended to perform the update for a delivery attempt in one (DB) transaction to minimize the amount of I/O and to maintain consistency. To achieve this, request lists are created which contain the changes that should be made. Change requests are appended to the list when the status for recipients are updated. After all changes (for one transaction or one scheduler run) have been made, the changes are committed to persistent storage. Updates to DEFEDB are made before updates to INCEDB (as explained in Section 2.4.1), that is, first the request list for DEFEDB is committed and if that succeeded, the request list of IBDB is committed to disk.
Here's a more detailled version of the description in Section 2.4.3.4 but only for the case that no special DSN is requested, i.e., without DSN support (RFC 1894). After a delivery attempt, the recipient is removed from ACTEDB and
Updates to DEFEDB are partially ordered. If multiple threads prepare updates for DEFEDB, they may contain changes for the same transaction(s). The order of updates of the transaction(s) in AQ must be reflected in the order of updates in DEFEDB. There can either be a strict order or a partial order, i.e., two updates need to be done only in a certain order if they are for the same transaction. To simplify implementation, a strict order is preserved3.13.
Each function that needs to update DEFEDB creates a ``request list'', i.e., a list of items that need to be committed to DEFEDB. This has two advantages over updating each entry individually:
The first approach (more flexible and more complicated than approach 2) is to enforce just an ordering on writing data to DEFEDB by: asking for a ``sequence number'' and enforcing the ordering by that sequence number in the write routine.
Algorithm:
Use a mutex, a condition variable, and two counters: ![]() and
and ![]() .
.
Initialize ![]() and
and ![]() to 0.
to 0.
Invariants:
![]() .
Number of entries:
.
Number of entries:
![]() if
if
![]() otherwise
otherwise
![]() ,
i.e.,
there are no requests iff
,
i.e.,
there are no requests iff
![]() .
.
Resetting ![]() and
and ![]() to 0 is done to minimize the chance for
an overflow.
to 0 is done to minimize the chance for
an overflow.
Get an entry:
lock(mutex) if (first == 0) first = last = 1 n = 1 else n = ++last unlock(mutex) return n
To write a request list:
lock(mutex) while (number != first) cond_wait(cond, mutex) unlock(mutex) lock(write_mutex) ... write list ... unlock(write_mutex) lock(mutex) assert(number == first) assert(first <= last) if (first < last) ++first signal(cond) else first = last = 0 unlock(mutex)
Note: there is currently no absolute prevention of overflowing ![]() .
If this needs to be done, then
.
If this needs to be done, then ![]() would be checked in the function
that increases it and if it hits an upper limit, it would wait on
a condition variable.
The signalling would be done in the function that increases first:
if it reaches the upper limit, then it would signal the waiting process.
would be checked in the function
that increases it and if it hits an upper limit, it would wait on
a condition variable.
The signalling would be done in the function that increases first:
if it reaches the upper limit, then it would signal the waiting process.
A simpler way to solve the problem is to lock DEFEDB and AQ, and write changes to DEFEDB before it is unlocked. Even though that keeps DEFEDB locked while making changes to AQ (which prevents only a reader process from accessing DEFEDB even though it might be possible to allow that otherwise), this seems like the simplest approach to solve the problem.
According to Section 2.4.7 QMGR must control the local load of the system, Section 3.4.10.13 describes the possible data structures for this purpose. In this section the functionality will be specified.
An MTS has some modules that produce data (SMTP servers) and some which consume data (SMTP clients, delivery agents in general). The simplest approach to control how much storage is needed is to regulate the producers such that they do not exceed the available storage capacities. To accomplish this two thresholds are introduced for each resource:
To allow for a fine grained control the capacity ![]() (range:
(range: ![]() )
of the producers
should be a regulated on a sliding scale proportional to the
actual value
)
of the producers
should be a regulated on a sliding scale proportional to the
actual value ![]() if it is between the lower and upper threshold.
Capacity
if it is between the lower and upper threshold.
Capacity ![]() is the inverse of the resource usage
is the inverse of the resource usage ![]() ,
i.e.,
,
i.e., ![]() .
.
if ![]() then
then ![]() else if
else if ![]() then
then ![]() else
else
![]()
or
if ![]() then
then ![]() else if
else if ![]() then
then ![]() else
else
![]()
For multiple values a loop can be used which is stopped as soon as one value exceeds its upper threshold. Computing the capacity can be done as follows:
![]()
for each ![]() do
do
if ![]() then
then ![]() ; break;
; break;
else if ![]() then
then ![]()
else
![]()
![]()
done
if ![]() then
then ![]()
Computing the resource usage is done in the corresponding way:
![]()
for each ![]() do
do
if ![]() then
then ![]() ; break;
; break;
else if ![]() then
then
![]()
![]()
done
if ![]() then
then ![]()
Notes:
In general, whenever a resource is used, it must be checked whether it is exhausted. For example, whenever an item is added to a DB the result value is checked. If the result is an error which states that the DB is full, the SMTP servers (producers) must be stopped. This is the simple case where the usage of a resource reaches the upper limit (exceed the upper threshold).
After several operations have been performed of which some contain additions to DBs, a generic throttle function can be called which checks whether any of the resource usages exceeds its lower limit in which case the SMTP servers are throttle accordingly. This needs to be done only if the new resource usage is sufficiently different from the old value, otherwise it is not worth to notify the producers of a change.
If the system is in an overloaded state, i.e., the producers are throttled or even stopped, then the resource usage must be checked whenever items are removed from DBs. If the new resource usage is sufficiently less than the old value, the SMTP servers are informed about that change (unthrottled). Alternatively, the producers can be unthrottled only after all resource usages are below their lower thresholds.
Unfortunately there is no simple, portable way to determine the amount of memory that is used by a process. Moreover, even though malloc(2) is supposed to return ENOMEM if there is no more space available, this does not work on all OS because they overallocate memory, i.e., they allocate memory and detect a memory shortage only if the memory is actually used in which case some OSs even start killing processes to deal with the problem. This is completely unacceptable for robust programming: why should a programmer invest so much time in resource control if the OS just ``randomly'' kills processes? One way to deal with this might be to use setrlimit(2) to artificially limit the amount of memory that a process can use, in which case malloc(2) should fail properly with ENOMEM.
If the OS properly returns an appropriate error code if memory allocation fails, then the system can be throttled as described in 3.4.17.1. However, it is hard to recover from this resource shortage because the actual usage is unknown. One way to deal with the problem is to reduce the size of the memory caches if the system runs out of memory. That can be done in two steps:
Now the system can either stay in this state or after a while the limits can be increased again. In the latter case the resource control mechanisms may trigger again if the system runs out of memory again. It might be useful to keep track of those resource problems to adapt the resource limits to avoid large variations and hence repeated operation of the throttling/unthrottling code (i.e., implement some ``dampening'' algorithm).
There are two different requirements about interacting with the queue manager:
For both forms of interaction a control socket can be used. However, in some cases it might be useful to give different access rights to the two interactions: reading status information might be allowed for more persons than requesting actions.
For interaction with QMGR the same basic communication protocol (RCBs) will be used to simplifiy (and unify) the implementation. For simplicity it seems to be useful to allow only one control connection at a time.
The QMGR should be able to list almost all of its internal status information when requested. In some cases it might be useful to ask (and return) only a subset of the data to reduce the amount of data that is sent.
Available actions should include:
The external interface of the SMTP server (also called smtpd in this document) is of course defined by (E)SMTP as specified in RFC 2821. In addition to that basic protocol, the sendmail X SMTP server will support: RFC 1123, RFC 1869, RFC 1652, RFC 1870, RFC 1891, RFC 1893, RFC 1894, RFC 1985, RFC 2034, RFC 2487, RFC 2554, RFC 2852, RFC 2920. See Section 1.1.1 for details about these RFCs.
Todo: verify this list, add CHUNKING, maybe (future extension, check whether design allows for this) RFC 1845 (SMTP Service Extension for Checkpoint/Restart).
A SMTP session may consist of several SMTP transactions. The SMTP server uses data structures that closely follow this model, i.e., a session context and a transaction context. A session context contains (a pointer to) a transaction context, which in turn contains a pointer back to the sessions context. The latter ``inherits'' its environment from the former. The session context may be a child of a daemon context that provides general configuration information. The session context contains for example information about the sending host (the client) and possibly active security and authentication layers.
The transaction context contains a sender address (reverse-path buffer in RFC 2821 lingo), a list of recipient addresses (forward-path buffer in RFC 2821 lingo), and a mail data buffer.
At startup a SMTP server registers with the QMGR. It opens a communication channel to the QMGR and announces its presence. The initial data includes a least a unique identifier for the SMTP server which will be used later on during communication. Even though the identification of the communication channel itself may be used as unique identifier, e.g., a file descriptor inside the QMGR, it is better to be independent of such implementation detail. The unique identifier is generated by the MCP and transferred to the SMTP server. It may also act as a ``key'' for the communication between SMTPS and QMGR/MCP if the communication channel could be abused by other programs. In that case, the MCP tells the QMGR about the new SMTPS (including its key).
It seems appropriate to have two different states: the state of the session and that of the transaction, instead of combining these into one. Not all of the combinations are possible (if there is no active session, there can't be a transaction). Many of the states may have substates with simple (enumerative) or complex (e.g., STARTTLS information) descriptions, some of them must be combinable (``additive''). Question: How to describe ``additive'' states? Simplest way: bit flags, binary or. So: can we put those into bitfields?
Session states:
Transaction states:
Multiple MAIL commands are not allowed during a transaction, i.e., MAIL is only valid if state is SMTPS-TA-INIT.
RCPT is only valid if state is SMTPS-TA-MAIL or SMTPS-TA-RCPT.
Some of these states require a certain sequence, others don't. We can either put this directly into the code (each function checks itself whether its prerequisites are fulfilled etc) or into a central state-table which describes the valid state changes (and includes appropriate error messages). It seems easier to have this coded into the functions than having it in the event loop which requires some state transition table, see libmilter.
VRFY, EXPN, NOOP, and HELP can be issued at (almost) any time and do not modify the transaction context (no change of buffers).
There need to be at least two data structures in the SMTP server; one for a transaction, one for a session.
Additionally, a server context is used in which configuration data is stored. This context holds the data that is usually stored in global variables. In some cases it might be useful to change the context based on the configuration, e.g., per daemon options. Hence global variables should be avoided; the data is stored instead in a context which can be easily passed to subroutines. The session context contains a pointer to the currently used server context.
Session:
| session-id | session identifier, maybe obtained from QMGR |
| connect-info | identification of connecting host (IP address, host name, ident) |
| fd | file descriptor/handle for connection |
| helo-host | host name from HELO/EHLO |
| access times | start time, last read, last write |
| status | EHLO/HELO, AUTH, STARTTLS (see above) |
| features | features offered: AUTH, TLS, EXPN, ... |
| workarounds | work around bugs in client |
| reject-msg | message to use for rejections (nullserver) |
| auth | AUTH context |
| starttls | TLS context |
| transaction | pointer to current transaction |
Transaction:
| transaction-id | transaction identifier, maybe obtained from QMGR |
| address, arguments (decoded?) | |
| rcpt-list | addresses, arguments (decoded?) |
| cdb-id | CDB identifier (obtained from cdb?) |
| cmd-failures | number of failures for certain commands |
| session | pointer to session |
Question: How much of the transaction do we need to store in the SMTP server? The QMGR holds the important data for delivery. The SMTP server needs the data to deal with the current session/transaction.
Todo: describe a complete transaction here including the interaction with other components, esp. queue manager.
Notice: this probably occurs in an event loop. So all functions are scheduled via events (unless noted otherwise).
As described in Section 3.16.4 the I/O layer will try to present only complete records to the middle layer. However, this may be intertwined with the event loop because otherwise we have a problem with non-blocking I/O. For the purpose of this description, we omit this I/O layer part and assume we receive full records, i.e., for the ESMTP dialogue CRLF terminated lines.
Before accepting any new connection, a session context is created. This allows the server to react faster (it doesn't need to create the context on demand), and it is guaranteed that a session context is actually available. Otherwise the server may have not enough memory to allocate the session context and hence to start the session.
smtps_session_new(OUT smtps-session-ctx, OUT status): create a new session context.
smtps_session_init(IN fd, IN connect-info, INOUT smtps-session-ctx, OUT status): Initialize session context, including state of session, fill in appropriate data.
The basic information about the client is available via a system call (IP address). The (canonical) host name can be determined by another system call (gethostbyaddr(), which may be slow due to DNS lookups). Question: do we want to perform this call in the SMTP server, in the QMGR, or in the AR? There should be an option to turn off this lookup completely and hence only rely on IP addresses in checks. This can avoid those (slow) DNS lookups. SMTPS optionally (configurable) performs an auth (ident) lookup.
smtps_session_chk(INOUT smtps-session-ctx, OUT status): SMTPS contacts the queue manager and milters that are registered for this with the available data (IP address, auth result). The queue manager and active milters decide whether to accept or reject the connection. In the latter case the status of the server is changed appropriately and most commands are rejected. In the former case a session id is returned by the queue manager. Further policy decisions can be made, e.g., which features to offer to the client: allow ETRN, AUTH (different mechanisms?), STARTTLS (different certs?), EXPN, VRFY, etc, which name to display for the 220 greeting, etc. The QMGR optionally logs the connection data.
Question: how can we overlap some OS calls, i.e., auth lookup, gethostbyaddr(), etc?
Output initial greeting (usually 220, may be 554 or even 421). Set timeout. Progress state or terminate session.
smtps_starttls(INOUT session-ctx, OUT state)
smtps_auth(INOUT session-ctx, OUT state)
All the following functions check whether their corresponding commands are allowed in the current state as stored in the session/transaction context. Moreover, they check whether the arguments are syntactically correct and allowed depending on the features in the session context. The server must check for abuse, e.g., too many wrong commands, and act accordingly, i.e., slow down or in the worst case closing the connection. Functions in SMTP server (see Section 3.4.12 for counterparts in the QMGR):
smtps_helo(INOUT session-ctx, IN line, OUT state): store host name in session context, clear transaction context, reply appropriately (default 250).
smtps_ehlo(INOUT session-ctx, IN line, OUT state): store host name in session context, clear transaction context, reply with list of available features.
smtps_noop(INOUT session-ctx, IN line, OUT state): reply appropriately (default 250).
smtps_rset(INOUT session-ctx, IN line, OUT state): clear transaction context, reply appropriately (default 250).
smtps_vrfy(INOUT session-ctx, IN line, OUT state): maybe try to verify address: ask address resolver.
smtps_expn(INOUT session-ctx, IN line, OUT state): maybe try to expand address: ask address resolver.
smtps_mail(INOUT session-ctx, IN line, OUT state): start new transaction, set sender address.
smtps_rcpt(INOUT session-ctx, IN line, OUT state): add recipient to list.
smtps_data(INOUT session-ctx, IN line, OUT state): start data section (get cdb-id now or earlier?).
smtps_body(INOUT session-ctx, IN buffer, OUT state): called for each chunk of the body. It's not clear yet whether this needs to be line oriented or whether it can receive simply entire body chunks. It may have to be line oriented for the header while the rest can be just buffers, unless we want to perform operations on the body in the SMTP server too. This function is responsible for recognizing the final dot and to act accordingly.
Question: how do we deal with information sent to the QMGR and the responses? Question: how do we describe this properly without defining the actual implementation, i.e., with leaving ourselves room for possible (different) implementations?
Assuming that the SMTP servers communicate with the QMGR, we need some asynchronous interface. The event loop in the SMTP servers must then also react on data sent back from the QMGR to the SMTP servers. As described in Section 3.5.2.5, events for the session must be disabled or ignored while the SMTP server is ``waiting'' for a response from the QMGR.
If the QMGR is unavailable the session must be aborted (421).
There is one easy way to deal with PIPELINING in the SMTP server and one more complicated way. The easy way is to more or less ignore it, i.e., perform the SMTP dialogue sequentially and let the I/O buffering take care of PIPELINING. This works fine and is the current approach in sendmail V8. The more complicated way is to actually trying to process several SMTP commands concurrently. This can be used to ``hide'' latencies, e.g., if the address resolver or the anti-spam checks take a lot of time - maybe due to DNS lookups - then performing several of those tasks concurrently will speed up the overall SMTP dialogue. This requires of course that some of those lookups can be performed concurrently as it is the case if an asynchronous DNS resolver is used.
Question: who generates the ids (session-id, transaction-id)? The QMGR could do this because it has the global state and could use a running counter based on which the ids are generated. This counter would be initialized at startup based on the EDB, which would have the last used value. However, it might reduce the amount of communication between SMTPS and QMGR if the former could generate the ids themselves. For example, just asking the QMGR for a new id when a session is initialized is a problem: which id should a SMTPS use to identify this request? The ids must be unique for the ``life time'' of an e-mail, they should be unique for much longer. Using a timestamp (as sendmail 8.12 does more or less) causes problems if the time is set backwards. Hence we need a monotonically increasing value. The ids should have a fixed length which makes several things simpler (even if it is just the output formatting of mailq). Since there can be several SMTPS processes, a single value in a shared location would require locking (the QMGR could provide this as discussed above), hence it would be more useful to separate the possible values, e.g., by adding a ``SMTPS id'' (which shouldn't be the pid) to the counter. This SMTPS id can be assigned at startup by the MCP. It seems tempting to make the transaction id name space disjunct from the session id name space and to provide a simple relation between those. For example, a session id could be: ``S SMTPS-Id counter'' and a transaction id could be: ``T SMTPS-Id counter ta-counter''. However, this makes it harder to generate fixed-length ids, unless we restrict the number of transactions in a session and the number of SMTPS processes. If we do that, then we must not set those limits to small (maybe 9999 would be ok), which on the other hand wastes digits for the normal cases (less than 10 for both values). Using 16 bit for the SMTPS id and 64 bit for the counter results in a string of 20 characters if we use base 16 encoding (hex). We could go to 16 (14) characters if we use base 32 (64) encoding. However, if we use base 64 encoding, the resulting id can't be used as filename on NT since it doesn't use case sensitive filenames (Check this).
If an SMTP server is implemented as an event-driven state machine, then a small precaution must be taken for pipelining. After an SMTP command has been read and a thread takes care of processing it, another SMTP command may be available on the input stream, however, it should not be processed before the processing of the current command has been finished. This can either be achieved by disabling the I/O events for that command stream during processing, or the session must be locked and any data available must be buffered while processing is active. It is not clear yet which of those two approaches is better; changing the set of I/O events may be an expensive operation; additional buffering of input data seems to be superfluous since the OS or the I/O layer takes care of that and more buffering will complicate the I/O handling (and violates layering). Maybe the loops which checks for I/O events should check only those sessions which are not active, i.e., which are currently not being processed. However, then the mechanism that is used to check for I/O events must present that I/O event each time (select() and poll() do this, how about others?).
Note: there are different checks all of which are currently called ``anti-spam checks''. Basically they can be divided into two categories:
Here RELAY is stronger than OK because it grants additional rights. However, it is not clear whether RELAY should override also tests in other (later) stages or just a possible anti-relay test (which might be done for RCPT). However, there might be cases where this simple model is not sufficient. Example: B is a backup server for A, but B does not have a complete list of valid addresses for A. Hence it allows relaying for a (possible) subset of addresses and temporarily rejects other (unknown) addresses, e.g.,
To:a1@A RELAY To:a2@A RELAY To:@A error:451 4.7.1 Try A directly
If session relaying actually overrides all subsequent tests, then this example works as expected, because hosts which are authorized to relay can send mail to A. However, if an admininstrator wants to maintain blacklists which are not supposed to be used then relaying tests and other policy tests need to be separate. An alternative solution would be using the QUICK: modifier (see below about QUICK) to indicate that also positive results (OK, RELAY) should have an ``immediate'' effect, i.e., they override later rules. This seems to be consistent with the way it is used in firewall applications ([pf]).
The order (and effect) of checks must be specifyable by the user; in sm8 this is controlled by the delay_checks feature. This allows only for either the ``normal'' order (connect, MAIL, RCPT) or the reverse order (RCPT, MAIL, connect). With the default implementation this means that MAIL and connect checks are done for each RCPT which can be very inefficient.
The implementation of the anti-spam checks is non-trivial since multiple tests can be performed and hence the individual return values must be combined into one. As explained in Section 3.14.1, map lookups return two values: the lookup result and the RHS if the key was found. For example, for anti-relay checks the interesting results are (written as pair: (lookup-result, RHS), where RHS is only valid if lookup-result is FOUND):
state = NO-DECISION-YET;
while (state != RELAY && more(tests)) {
(r, rhs) = test();
switch (r, rhs) {
case (TEMPFAIL, -): state = r; break
case (FOUND, RELAY): return r;
default: break;
}
}
if (state == NO-DECISION-YET) return REJECT;
else return state;
These anti-relay checks should be done in several phases of the ESMTP dialogue.
To do this, the flow control depicted above is enhanced such that the state is initialized properly by the state of the surrounding ESMTP phase, i.e., for session it is initialized to NO-DECISION-YET, for RCPT it is set to the relay-state of the session.
It becomes more complicated for other anti-spam tests. For example: one test may return TEMPFAIL, another may return OK, a third one REJECT, a fourth one REJECT but with a 4xy error. Question: how to prioritize? Question: should it be just a fixed algorithm in the binary or something user-definable? Maybe compare nsswitch.conf(2)([nss]) which provides a ``what to do in case of...'' decision between different sources (checks in the anti-spam case)? That is:
| Result | Meaning |
| FOUND | Requested database entry was found |
| NOTFOUND | Source responded "no such entry" |
| PERMFAIL | Source is not responding or corrupted (permanent error) |
| TEMPFAIL | Source is busy, might respond to retries (temporary error) |
| Action | Meaning |
| CONTINUE | Try the next source in the list |
| RETURN | Return now |
<entry> ::= <database> ":" [<source> [<criteria>]]* <criteria> ::= "[" <criterion>+ "]" <criterion> ::= <status> "=" <action> <status> ::= "FOUND" | "NOTFOUND" | "PERMFAIL" | "TEMPFAIL" <action> ::= "RETURN" | "CONTINUE" <source> ::= "file" | "DNS" | ...
So we need a state that is carried through and can be modified, and an action (break/return or continue).
<entry> ::= <what> ":" [<test> [<criteria>]]* <return> <test> ::= some-test-to-perform <criteria> ::= "[" <criterion>+ "]" <criterion> ::= <status> "?" [<assignment>] <action> ";" <status> ::= "FOUND" | "NOTFOUND" | "PERMFAIL" | "TEMPFAIL" <action> ::= <return> | "continue" <return> ::= "RETURN" [<value>] <assignment> ::= "state" "=" <value> "," <value> ::= <status> | "status"
Alternatively we can use a marker that says: ``use this result'' (e.g., pf([pf]): quick); by default the last result would be used. However, this doesn't seem to solve the TEMPFAIL problem: the algorithm needs to remember that there was a TEMPFAIL and return that in certain cases.
Question: can we define an algebra for this? Define the elements and the operations such that a state and a lookup result can be combined into a new state? Would that make sense at all? Would that be flexible enough?
Question: what are the requirements for anti-spam? Are the features provided by sm8 sufficient? Requirements:
Question: Where do we put the anti-spam checks? Some of them need similar routines as provided by the address resolver, e.g., for anti-relay we need the recipient address in a canonical form, i.e., which is the real address to which the mail should be sent? Maybe we need an interface that allows different modes, i.e., one for verification etc only, one for expansion.
For each stage in the SMTP dialogue there are builtin checks (which usually can be turned on/off via an option, e.g., accept-unresolvable-domain), and there are checks against the access map. The order of checks specifies whether a check can override other (``later'') checks unless special measures are taken (see below). Note: some of the builtin checks are configured by the user, hence it does not make sense to provide another option to override these because that can be done by setting the option accordingly, e.g., for connection rate it simply requires increasing the limit.
user defined: check host name and address against maps (access map, DNS based blacklists).
builtin: syntax checks3.15.
user defined: check address against maps (access map, DNS based blacklists).
builtin: unresolvable domain, others?
builtin: syntax checks, local user: does the address exist?
user defined: check address against maps,
builtin (configurable via map): check anti-relay.
As usual these checks may all be done during the RCPT stage or when they occur during the SMTP dialogue.
Before the control flow of sm8 is described, the values (data, RHS) of a map lookup need to be explained:
Control flow in sm8:
These two methods could be combined by keeping track of a state. If delay-checks is used, then MAIL and connect checks are performed for each recipient (unless overridden via an accept return code). Moreover, either the return codes could be more fine grained, e.g., for connect checks a return value could say: reject now, don't bother to do any further checks later on (compare firewall configurations ([pf]): quick). This can be achieved by either using different tags for the LHS or different tags for the RHS.
Question: what would the state look like? Is it possible to define an order on the value of the RHS (in that case the state would be the ``maximum'' of the values)?
Note: a simple state might not be good enough, e.g., if MAIL should be rejected only if RCPT matches an entry in a map, then a state for MAIL does not help. However, such a test would have to be performed in RCPT itself (and use MAIL too for its check).
Other hooks should be the same as in sendmail 8, i.e., for the various SMTP commands (DATA, ETRN, VRFY, EXPN) and some checks for TLS or AUTH.
sendmail 8 actually delays checks until the recipient stage. This has the disadvantage that all checks are run for every recipient unless the recipient is a ``spam friend''. However, this also has one advantage: if all recipients for a transaction are ``spam friends'' then none of the other checks need to be performed. This can be an advantage if time consuming checks (e.g., DNS blacklists) are specified. It would be possible to implement this behavior in sendmail X without its disadvantage: the tests need only be performed once and the results will be cached just like they are now. However, this has one disadvantage: the QUICK: modifier does not work if this implementation is chosen. It might be possibly to make delay-checks an option with more states than on and off, e.g., off, delay-rejections: perform tests at corresponding SMTP stage but delay possible rejections, delay-checks: perform tests only at RCPT stage. This might be a future enhancement but it is not worth the effort for sendmail X.0.
As the experiences with sendmail 8 anti-spam checks have shown, it will be most likely not sufficient to provide some simple, restricted grammar. Many people want expansions that are only available in sendmail 8 due to the ruleset rewrite engine (even though that has several problems by itself since it was intended for address rewriting, not as a general programming language). Question: how can sendmail X provide a flexible description language for anti-spam checks (and other extensions, e.g., the address resolver)? Of course the simplest way for the implementors is to let users hack the C source code. If there is a clean API and a module concept (see also Section 3.17) then this might be not as bad as it sounds. However, letting user supplied C code interact with the sendmail source code may screw up the reliability of sendmail. A separation like libmilter is cleaner but slower.
For the first release (sendmail X.0) some basic anti-spam functionality must be provided that is sufficient for most cases. For each step SMAR returns up to three values:
| RELAY | 100 | Allow relaying |
| OK | 250 | Accept command, no further tests in this stage |
| CONTINUE | 300 | Run further tests |
| SSD | 421 | Service shutting down |
| TEMP | 450 | Temporary error |
| REJECT | 550 | Permanent error |
This code is modified by adding a constant to it if the RHS string contained QUICK3.18.
Enhancements for later releases may be:
| DISCARD | 600 | Accept mail but discard it |
| QUARANTINE | 700 | Quarantine mail |
Below is a proposal for the basic anti-spam algorithm. There are a few configuration options for this: feature delay-checks (same behavior as in sendmail 8, i.e., returning rejections is delayed to the RCPT stage).
Note: SMAR and SMTPS have to interact here properly to avoid too much communication between them (and hence latency). The problem is that SMTPS may make some local decisions whether to allow relaying (based on local maps of some kind, e.g., regular expressions) and those checks are also part of the algorithm outlined above.
The API provides functions for each SMTP command/phase similar to sendmail 8. For maximum flexibility, we specify it as asynchronous API as outlined in Section 3.1.1. In this case, two different function calls for the same session/transaction can not overlap (theoretically we could do that due to pipelining, but it probably doesn't give us anything). Therefore the session context (which may contain (a pointer to) the transaction context) should be enough to store the state between calls, i.e., it acts as a handle for the two corresponding functions.
check_connect(INOUT session-ctx, IN line, OUT state), check_connect_status(IN session-ctx, OUT state),
check_helo(INOUT session-ctx, IN line, OUT state), check_helo_status(IN session-ctx, IN line, OUT state),
check_ehlo(INOUT session-ctx, IN line, OUT state), check_ehlo_status(IN session-ctx, OUT state),
check_noop(INOUT session-ctx, IN line, OUT state), check_noop_status(IN session-ctx, OUT state),
check_rset(INOUT session-ctx, IN line, OUT state), check_rset_status(IN session-ctx, OUT state),
check_vrfy(INOUT session-ctx, IN line, OUT state), check_vrfy_status(IN session-ctx, OUT state),
check_expn(INOUT session-ctx, IN line, OUT state), check_expn_status(IN session-ctx, OUT state),
check_mail(INOUT session-ctx, IN line, OUT state), check_mail_status(IN session-ctx, OUT state),
check_rcpt(INOUT session-ctx, IN line, OUT state), check_rcpt_status(IN session-ctx, OUT state),
check_data(INOUT session-ctx, IN line, OUT state), check_data_status(IN session-ctx, OUT state),
check_header(INOUT session-ctx, IN buffer, OUT state), check_header_status(IN session-ctx, OUT state), called for each header line?
check_body(INOUT session-ctx, IN buffer, OUT state), check_body_status(IN session-ctx, OUT state), called for each body chunk?
It might also be possible to just pass the SMTP command/phase as parameter and hence minimize the amount of functions. However, then the callee most likely has to dispatch functions appropriately. sendmail X will most likely only provide functions for connect, mail, and rcpt, hence it might really be simpler to have just a single function. There must be some mechanism anyway to act upon configuration data (see Section 3.5.2.7).
ToDo: specify the behavior of SMTPS when function calls fail and the valid return codes and their effects. This should be consistent with the behavior specified in 3.5.2.7 and 3.5.2.8. See Section 3.5.4 for an attempt to specify this behavior.
Notice: if the anti-spam functions end up in a different module from the SMTP server, we certainly have to minimize the amount of data to transfer; it would be bad to transfer the entire session/transaction context all the time. Crazy idea: have a stub routine that only sends the changed data to the module. This might be ugly, but could be generalized. However, it would require that the stub routine recognizes changed data, i.e., it must store the old data and provide a fast method to access and compare it. Then we need an interface that allows to transfer only changed data, which could be done by using ``named'' fields. However, then also the other side needs to store the data and re-assemble it. Moreover, both caches need to be cleaned up, either explicitly (preferred, but would require extra API calls which may expose the implementation; at least we would need a call like close or discard) or by expiration (if an entry is expired too early, i.e., while in use, it would ``simply'' be added again). The overhead of keeping track and assemble/re-assemble data might outweigh the advantage of minimized data transfers.
The SMTP server must offer a way to check for valid (local) users. This is usually done in two steps:
These steps could be combined into one, i.e., look up the complete address in one map. However, this may require many entries if a lot of ``virtual'' domains are used and valid users are the same in those. Moreover, a map of valid localparts might be the password file which does not contain domain parts, hence the check must be done in two steps.
The mail sender address must not just be syntactically valid but also replyable. The simplest way to determine this is to treat it as a recipient address and ask the address resolver to route (resolve) it. However, there are a few problems: the address resolver should not perform alias expansion because it would be a waste of time to check a long list of addresses (recipients). Question: if an address is found in the alias map, is that a sufficient indication that it is acceptable (i.e., routable)? Answer: most likely yes, it is at least very unusual to have an address in the alias map which is not valid (routable).
sendmail 8 performs a simple check for the sender address: it tries to determine whether the domain part of the address is resolvable in DNS. Even though this is a basic check, it is not sufficient as spammers simply create bogus DNS entries, e.g., pointing to 127.0.0.1. Hence it seems to be useful to perform an almost full address expansion as described above and then check the IP addresses against a list of forbidden values which are specified in some map. This approach has also a small problem: if the address is routed via mailertable then it could be directed to one of those forbidden values. There are two possible solutions to this problem:
Solution 2 seems to be useful because mailertable entries are most likely made by an administrator with a clue and hence are implicitly ok. However, implicit operations can cause problems3.19, hence approach 1 might be better from a design standpoint3.20, but less user friendly.
Most map lookups for the SMTP servers are implemented by SMAR to avoid blocking calls in the state-threads application. SMTPS sends minimal information to SMAR, i.e., basically a key, a map to use for the lookup, and some flags, e.g., lookup the full address, the domain part, the address without details (``+detail''). SMAR performs the lookup(s) and send back the result(s). The result includes an error code and the RHS of the map (maybe already rewritten if requested?).
The normal operation of a policy milter is fairly easy to implement in SMTPS, it basically acts the same as querying QMGR or SMAR (access map) whether an SMTP command is allowed. A policy milter has also access to the mail body, which is not inspected by other modules, however, such functionality can be added if requested, e.g., some simple regular expression matching on headers and body lines. The behavior in case of errors can be specified for a milter while it is mostly fixed for the other modules, i.e., if QMGR fails to respond then the session is terminated (421). In general, a policy milter should be invoked via the API described in Section 3.5.2.9. However, the API is currently not completely specified, especially with respect to the behavior of SMTPS when various errors occur and when SMTP error codes are returned from the API.
For a milter several modes are allowed:
Based on the first three error modes, the following connection states are possible:
Overall this means there are three basically different states:
These states should be inherited by each SMTP session such that they can be changed locally. An error in one session does not necessarily mean that the entire connection is broken. Moreover, reconnect attempts should only be made for new sessions, making them during a session is not really useful because a milter usually needs all session related data, e.g., the connection information.
A milter registers with the server in which of the SMTP steps it is interested. Hence in each step the server checks those flags before it decides whether to send the information to the milter.
An SMTP server should react in basically the same way to results from a milter as it does for results from other anti-spam checks, e.g., the access map, as specified in 3.5.2.8. However, that specification is currently not complete because it does ignore lookup errors (see item 1 in Section 3.5.2.8). Section 3.5.4 tries to take errors into account and completely specify the behavior.
Question: should OK from access map disable policy milter checks (see also Section 2.10.2)? That would be ``confusing'' for a milter that wants that data, even though it would match the REJECT behavior because milter is not invoked in that case. However, this is not really a symmetric situation: REJECT means that the command is not accepted and hence in almost all cases it does not matter what a milter would do about it. for OK the milter might want to do something. However, that would be a contradiction (a misconfiguration), i.e., one part of the configuration explicitly accepts the command another rejects it. The right return value in this case is CONTINUE instead of OK. In order for the milter to keep track of the SMTP dialog (and hence the current state) it might be possible to send the information to the milter including the fact that the command has been accepted and hence cannot be rejected by the milter (``for your information only'').
Note: the interaction between anti-spam checks and milter is even more complicated if feature delay-checks is turned on. In sendmail 8 this was a simple hack that only influenced the rulesets (by renaming the connect and mail check and calling them from the rcpt ruleset). In sendmail X this is solved in a different way: the checks are run at the appropriate stage in the SMTP dialogue, but the results may be delayed. Hence a connection might be rejected unless a recipient test overrides it (``spam friend''). Question: How should this interact with milter tests? Should they just run ``normally'' as the other tests and their results are delayed?
This section tries to enhance the response model from 3.5.2.8 with the handling of lookup errors. If done right, it should describe the behavior for the functions specified in Section 3.5.2.9. There are various ways to deal with errors (as mentioned elsewhere (3.5.3):
It seems that only the first two modes are really useful: ignore errors or terminate the session on error. Issuing a temporary error for every command seems like a waste of time and resources; it could only be useful if the functions can ``recover'', i.e., if an error is really temporary and might not occur if the call is repeated, even without any actions by the caller. For a milter a communication error between SMTP server and libmilter will usually require a reconnect (and maybe a restart of the milter), hence closing a SMTP session is the simplest way to deal with the problem.
This can be made more complicated (``fine grained'') by specifying one of these options for each function (step in the SMTP dialogue) individually instead of globally.
For now we consider only two error modes:
Here is a simple approach to the problem:
An anti-spam function has a return value (called ``lookup result'' elsewhere): SUCCESS, NOTFOUND, TEMPFAIL, PERMFAIL. If the result is TEMPFAIL or PERMFAIL (i.e., an error) then the system should have a default reply code (which could be different for each test). Question: can the function itself change those errors into a corresponding reply code? That is, if the return value is an error then return NOTFOUND if the error mode is EM-IGNORE and SUCCESS plus SSD (see 3.5.2.8) if the error mode is EM-SSD. This could be done by a generic wrapper, which might even implement different error modes per state as indicated above.
If this idea is feasible, then the algorithm described in Section 3.5.2.8 can be used without changes. Note: there is most likely some problem with this approach, but currently I cannot find (remember) it.
The SMTP server is started and controlled by the MCP. Each server communicates with the queue manager and the address resolver (question: directly?).
The SMTP servers must be able to reject connections if requested by QMGR to enable load control. This should be possible in various steps, i.e., by gradually reducing the number of allowed connections. In the worst case, the SMTP server must reject all incoming connections. This may happen if the system is overloaded, or simply if there is no free disk space to accept mail.
The original design required that the SMTP server removes a content entry from the CDB on request by the queue manager. This was done to avoid lockings overhead since the SMTP server is the only one which has write access to the CDB. However, in the current design the QMGR interacts directly with CDB (which should be implemented as library) to remove entries from it. This is done for several reasons:
The address resolver doesn't have an external interface. However, it can be configured in different ways for various situations. Todo: and these are?
Question: how to specify address resolving routines? Provide some basic functionality, allow hooks and replacements? How to describe? There are four different types of addresses: envelope/header combined with sender/recipient. It must be possible to treat those differently. For example, a pure routing MTA doesn't touch header addresses at all.
In Section 2.6.6.1 a configuration example was given which is slightly modified here:
local-addresses {
domains = { list of domains };
map { type=hash, name=aliases, flags={rfc2821, local-parts, detail}}
map { type=passwd, name=/etc/passwd, flags={local-parts}}
}
See Section 3.2.3 how the list of valid domains can be specified, and Section 4.3.3 about a possible way to check whether a domain is in a list.
The current implementation (2004-07-27) uses the following hacks:
[127.0.0.2]
which indicates that LMTP over a local socket should be used.
local:.
Item 1 could be modified a bit to use a different RHS, e.g., local: or lmtp:, to avoid using an IP address. The implementation must be modified accordingly (theoretically it might be possible to use a broadcast address but this is just another hack which may cause problems later). Item 2 should be extended by the more generic description given above in the configuration example.
Possible flags for map types are:
The address resolver must be able to access the usual system routines (esp. DNS) and different map types (Berkeley DB, NDBM, LDAP, ...). In addition to this, sendmail X.x should contain a generic map interface. This can either be done using a simple protocol via a socket or shared libraries (modules).
Question: should the address resolver receive a pre-parsed address (internal, tokenized format) or the string-representation (external format) of the address? This depends on where the address parser is called. It is non-trivial to pass the internal (tokenized) form via IPC because it is a tree with pointers in memory. So if we want to use that format, we need to put it into a contiguous memory region with the appropriate information (we could use pointers starting from the begin of the memory section, but is the packing/unpacking worth it?). Question: do we want the SMTP server to do some basic address (syntax) checking? That seems to be ok, but adds code to it. This may also depend on the decision who will do anti-spam checks, because the address must be parsed before that.
Basic functionality: return DA information for an address.
ar_init(IN options, OUT status): Initialize address resolver.
ar_da(IN address, IN ar_tid, OUT da_info, OUT status): start an AR task; optionally get the result immediately.
ar_da_get(IN ar_tid, OUT da_info, OUT status): get results for an AR task.
ar_da_cancel(IN ar_tid, OUT status): cancel an AR task.
Question: do we want to add a handle that is returned from the initialization function and that is passed to the various AR routines? We may want to have different ARs running, or we want to pass different options to the routines. If we use a handle, then we need also a terminate function that ends the usage of that handle.
Note: as explained in Section 3.4.5, the AR is not doing MX lookups. Those are either done in the QMGR or the DAs.
Resolved address format is a tuple consisting of
Question: should there be more elements like: localpart, extension, hostpart? It would be nice to make this flexible (based on DA?).
Notice: the result of an address resolver call can be a list of such tuples. This is more than MX records can do. By allowing a list of tuples we have maximum flexibility. For example, the address resolver could return lmtp,host0,user@domain; esmtp,host1:host2,user@domain. Question: what kind of complexity does this introduce? By allowing different DA the scheduling may become more complicated. Most MTAs allow at most several hosts, but only one address and DA. This flexibility may have serious impact on the QMGR, esp. the scheduling algorithms. Before we actually allow this, we have to evaluate the consequences (and the advantages).
Of course an address can also resolve to multiple addresses (alias expansion).
Handling errors is an especially interesting problem in the address resolver. Even though it looks simple at first, the problem is complicated by the fact that multiple requests might have to be made. For example, getting the IP addresses of hosts to contact for an e-mail address involves (in general) MX and A record lookups, i.e., two phases where the second phase can consist of multiple requests. Handling an error in the first phase is simple: that error is passed back to the caller. Handling an error in the first phase is complicated: it depends on the kind of error and for which of the A records an error occurs. The main idea for the address resolution is to find a host to which the mail can be delivered. According to the requirements, this is one of the systems that is listed as ``best MX host''. Hence if a lookup of any A record for any of the best MX hosts succeeds it is sufficient to return that result; maybe with a flag indicated that there might be more data but the lookup for that failed in some way. That is, a partial result is better than insisting that all lookups return successfully.
It might be useful to cache results of map lookups in the AR to avoid too many lookups, esp. for maps where lookups are expensive. This requires that similar to DNS a TTL (Time To Live) is specified to avoid caching data for too long. A TTL of 0 will disable caching. In general it would be better if the external maps provide their own caching since then the code in the AR will be simpler. Moreover, if several modules in sendmail X will use maps, then caching in each of the modules will just replicate data with the usual problems: more memory in use, possibility of inconsistencies, etc.
Note: this may be a future enhancement that is not part of sendmail X.0.
The AR is likely to call functions that may take a long time before they return a result. Those functions will include network activity or other tasks that have a high latency, e.g., disk I/O: searching for an entry in a large map. If we actually know all the places that can block, we could employ a similar threading model as intended for the QMGR, and hence even make the AR a part of the QMGR. However, it is unlikely that we are able to determine all possible blocking function calls in advance, especially if third-party software (or modules) are involved. Hence it is easier for programming to use a threading model in which the OS helps us to get around the latency, i.e., the OS schedules another thread if the current one is blocked. This will require more threads than are usually advisable for a high-performance program (e.g., two times the number of processors), since more threads can be blocked. However, it is probably still a bad idea to use one thread per task, since that will more or less relate to one thread per connection which definitely is bad for performance. The event thread library described in Section 3.20.5.1.1 can be configured to have reasonable number of worker threads and hence should be flexible enough to use for the implementation of the AR.
If all blocking calls actually are introduced by network activity, then state threads (see Section 3.20.3.1) would be an efficient way to implement the AR. However, that requires that all libraries which are used by the AR perform I/O only via the state threads interface which is not achievable because that would require to recompile many third-party libraries.
The external interface of the mail submission program must be compatible (as much as possible) with sendmail 8 when used for this purpose. There will be less functionality overall, but the MSP must be sufficient to submit e-mails.
Todo: to which other program does the MSP speak? See the architecture chapter.
Mail delivery agents must obey the system conventions about mailboxes. sendmail X.0 will support LDAs that speak LMTP and run as a daemon or can be started by MCP (on demand) such as procmail [pro].
Mail delivery agents have different properties (compare mailer definitions in sendmail 8). These must be specified such that the QMGR can make proper use of the DA.
These properties are listed below (some of them are configuration options for the MCP, i.e., how to start DA). Notice: this list is currently almost verbatim taken from the sendmail 8 specification.
MCP configuration:
sendmail 8 options to fix mails by adding headers like Date, Full-Name, From, Message-Id, or Return-Path will not be in sendmail X(.0) as options for delivery, but should be in the MSA/MSP such that only valid mails are stored in the system. It's not the task of an MTA to repair broken mails.
Other sendmail 8 options that probably will not be in sendmail X.0:
More sendmail 8 options that will not be in sendmail X.0:
See Section 2.8.2 about delivery classed and delivery instances for some basic terminology (which is not yet fixed and hence not used consistently here). There are several ways multiple delivery agents (instances) can be specified:
Note: proposal 3 is probably required to make efficient use of multi-processor systems, i.e., if a DA is implemented using statethreads [SGI01] (see also Section 3.20.3.1) then the DA can only make use of a single processor, moreover, it can block on disk I/O. Additionally, if a DA can only perform a single delivery per incocation (process), then multiple processes can be used to improve throughput by providing concurrency.
Proposal 1 is required if the different features are too complicated to implement in a single process. For example, it does not seem to be useful to implement a DA that speaks SMTP and performs local delivery as a single process because the latter usually requires changing uids. However, it makes sense to implement a DA that can speak ESMTP, SMTP, and LMTP in a single process, maybe even using different ports as well as some other minor differences. Multiple processes are also useful if the DA process has certain restriction on the number of DA instances (threads) it can provide. For example, one DA may provide only 10 instances while another one may provide 100. However, such a restriction may also be achieved by other means, e.g., in the scheduler.
In some cases it might be useful to have a fairly generic DA which can be instantiated by external data, e.g., via mailertable entries that select a port number. Obviously one instantiation parameter is the destination IP address (it would not make sense to specify a class for each of them), but which other parameters should be flexible (specified externally to the configuration itself)? Possible parameters are for example port number and protocol (ESMTP, SMTP, LMTP). However, this data must be provided somehow to instantiate the values. Offering too much flexibility here means that these parameters must be configured elsewhere -- outside the main configuration file -- which introduces most likely an additional configuration syntax (e.g., in mailertable: mailer:host:port) which needs to be understood by the user and parsed by some program, such adding complexity in the configuration and the program. This is another place where it is necessary to carefully balance consistency (simplicity) and flexibility. In a first version, a less flexible and more consistent configuration is desired (which also should help to reduce implementation time).
The previous section showed several proposals how to specify multiple DAs. It is most likely that all of them will be implemented, because each of them is useful under different circumstances. This causes a problem: how to select (name) a DA? If multiple processes can implement the same DA behavior, then they either need the same name or some other way must be found to describe them such that they can be referenced (selected).
There will be most likely only two ways to select a DA: one default DA (e.g., esmtp) and the rest can be selected via mailertable.
A DA needs several names:
The scheduler receives a delivery class identifier from smar. Based on that it has to find a delivery agent instance that provides the delivery class. There can be multiple DAs, and hence some selection algorithm must be implemented; see also below (item 4) about round robin selection etc.
Todo: need some terminology here to properly specify what is meant and unambiguously reference the various items.
Some random notes that need to be cleaned up:
args = "program -f sm.conf -i %d" snprintf(realargs, sizeof(realargs), args, id)Instead of using such a format it might be simpler to just have an option pass_id = -i; and then pass -i id as first argument (just insert it). MCP can give a unique id to each process that specifies this option.
Note: the SMTPC session/transaction id format expects an 8 bit id only. Possible solution: qmgr keeps an ``internal'' id for each smtpc which is used to generate the transaction/session ids but not anywhere else.
min/max processes: who requests more processes? How do they stop? Idle timeout? Number of uses? On request?
Compare this with sendmail 8: there are different types of mailers specified by the Path field, e.g., those which use TCP/IP for communication with a program (IPC), delivery to files (FILE), and external programs for which the communication occurs via stdin and stdout. All IPC mailers can be treated as one delivery family.
Interface between QMGR and DA (see Section 3.4.5.1).
Question: what about outgoing address rewriting, header changes, output milters?
Section 3.9.2.1 specifies the ``special'' case how the SMTP client returns status information for a delivery attemtp to the QMGR. That section is SMTP client specific, it must be extended (generalized) for other DA types. Important is whether the transaction was successful, failed temporarily or permanently, and whether per-recipient results are available. In case of failures: is this failure ``sticky'' or can another delivery attempt (with different sender/recipients) made immediately?
Question: which information does the QMGR really need and what is just informational (for display in the mail queue)? Compare mci in sendmail 8. The QMGR needs to know whether the error is permanent or temporary and whether it is ``sticky'', i.e., it will influence other connections to that host too. Question: anything else?
Note: if a DA cannot access the mail content (CDB) -- which must be logged as an error -- then the transaction is considered successful if the error code is ENOENT which may happen if someone removed the CDB entry. Other access errors are returned to the QMGR.
The external interface of the SMTP client is of course defined by (E)SMTP as specified in RFC 2821. In addition to that basic protocol, the sendmail X SMTP client implementation will support: RFC 974, RFC 1123, RFC 2045, RFC 1869, RFC 1652, RFC 1870, RFC 1891, RFC 1893, RFC 1894, RFC 2487, RFC 2554, RFC 2852, RFC 2920.
Todo: verify this list, add CHUNKING, maybe (future extension) RFC 1845 (SMTP Service Extension for Checkpoint/Restart).
We have similar choices here for the process model as for the SMTP server. However, we have to figure out which of those models is the best for the client, it might not be the same as for the server.
The internal interface must be the same as for the other delivery agents, except maybe for minor variations.
The result from the SMTP client for a delivery attempt can be subdivided into two categories: per session and per transaction.
For the session the result contains the session-id and a status, which is one of the following:
For a transaction the result contains the transaction-id and a status, where status might be fairly complicated. The transaction may fail at any of the SMTP commands (MAIL, RCPT, DATA, final dot) because the server returns an SMTP error code, there can be an I/O error, or there can be an internal DA error.
Keeping track of the delivery status is done per recipient (not per transaction), hence an SMTP client must return status information that can be applied to each recipient of a transaction. This is done by returning a transaction status and a (possibly empty) list of individual recipient statuses, i.e., the status of each recipient which has not been accepted. The transaction status applies to all recipients for which no individual status is sent. Each recipient status is initialized to an temporary error. Only after the RCPT command has been sent to the server and a reply has been received the status is updated accordingly. A transaction is obviously only successful if the final dot was accepted by the server, in which case OK is the transaction status to send to QMGR. If a temporary error is received for any of the SMTP commands MAIL, DATA, final dot, or if there is an I/O error or an internal DA error, then the transaction status is a temporary error. If a permanent error is received for any of the SMTP commands MAIL, DATA, final dot, then the transaction status is a permanent error.
The external interface for libmilter is described in the documentation that comes with the sendmail 8 source code distribution.
For the purpose of the first sendmail X release, the functionality will be restricted such that all functions that modify a mail are disabled; they should return a new error code, ENOIMPL.
The SMTP server needs some configuration support for a milter. For simplicity, there will be only a single milter. If multiple milters are supposed to be used, then some kind of ``multiplexor'' must be implemented on the libmilter side.
The internal interface for milter will not use the sendmail 8 - libmilter protocol. That protocol is not able to deal with multiple SMTP sessions over a single connection. For the same reason, it is not possible to use ESMTP as protocol even though that would be a good choice because it is a standard and it offers extensibility. Using ESMTP requires one file descriptor for each (incoming) ESMTP connection to be able to distinguish between different ESMTP sessions. This causes problems on some platforms because stdio is limited to 256 file descriptors. Another restriction is imposed by select(2) which usually can handle up to 1024 file descriptors. While this restriction be circumvented by using poll(2), it is obviously better to check only a single file descriptor for activity instead of hundreds or thousands.
For simplicity, the same basic protocol that is used between the SMTP servers and SMAR or QMGR will be used, which is based on RCB (see Section 3.16.11.1.1). The protocol is internal, and hence described in the implementation Section 4.9.
A program (mailq) should show the content of the mail queues. Currently there are three mail queues (2.4.1): incoming mail queue, deferred mail queue, and active queue. It should be possible to show the content of the first two, those are on persistent storage; the last queue is just a subset of the other two.
Question: how accurate must the output be? To achieve a completely accurate output all write (and delete) operations must be stopped in principle, i.e., write access to a queue must be locked. There might be some ways around this, e.g., while the program is reading the queue content and another thread (process) wants to update it those changes must be communicated to the reader, however, this is certainly not worth the programming effort. Locking a queue just to display its content does not seem to be reasonable: if a queue is large then accessing it could take a considerable amount of time during which other activities are blocked. In such a situation locking a queue just makes progress even slower, and hence adds to the problem (e.g., a manager asking an employee every few moments whether some work is done).
It might be useful to ask the queue manager to schedule certain entries for immediate (``as soon as possible'') delivery. This will also be necessary for the implementation of ETRN.
Some statistics need to be available. At least similar to mailstats in sendmail 8. Maybe the rest is gathered from the logfile.
This section describes one possible choice for user and group ids in the sendmail X system and the owners and permissions of files, directories, sockets etc.
The MCP is started by root. The configuration file can either be owned by root or a trusted user. Most other sendmail X programs are started by the MCP.
The following notation is used:
There are the following files which must be accessed by the various programs:
Hence the directory must be writable by SMTPS and QMGR, accessible by SMTPC. The files must be writable by SMTPS and readable by SMTPC.
Hence the directory is owned by SMTPS (O-S), has group QMGR (G-Q) and the following permissions 0771 (or 0731):
d rwx rwx --x
The files in the directory are owned by SMTPS (O-S) and have group SMTPC (G-C) with permissions 0640:
rw- r-- ---
Todo: figure out how this works for non-Unix systems.
Moreover, there is one communication socket each between QMGR and other sendmail X programs, hence these sockets must be readable/writable by QMGR and that program. Considering that socket permissions are not sufficient to protect a socket in some OS, the socket must be in a directory with the proper permissions.
The sockets and directories are owned by QMGR and group-accessible to the corresponding program. Problem: either QMGR must belong to all those groups (to do a chown(2) to the correct group), or the directories must exist with the correct permissions and the group id must be inherited from the directory if a new socket is created in that group. The former can be considered a security problem since it violates the principle of least privileges. The latter may not work on all OS versions.
This section deals in general with databases and caches as they are used in sendmail X.
General notice: us usual it is important to tune the amount of information stored/maintained such that the advantages gained from the information (faster access to required data) outweighs the disadvantages (more storage and effort to properly maintain the data). For example, data should not be replicated in different places just to allow simpler access. Such replication requires more storage (which in case of memory is precious) and the overhead for maintaining that data and keeping it consistent can easily outweigh the advantage of faster access.
Section 3.4.4 explains that some DBs need multiple access keys. This can be achieved by having one primary key and several secondary keys. Question: do we want to allow a varying number of keys, or do we want to write modules with one, two, three, and four keys? The latter is easier to achieve, but not as flexible. However, if the full flexibility is not needed (it most likely isn't), then it might not be worth to try to specify and implement it.
In some cases an access key (which does not need to be the primary key, see 3.13.1) may not uniquely specify an element. For example, if a host name is used as key, then there might be multiple entries with the same key. In that case, we need to provide functions to return either a list of entries or to walk through the list. The latter is probably more appropriate, since usually the individual entries are interesting, not the list as a whole. For such ``walk through'' function we need a context pointer that is passed to the get-next-entry function to remember the last position.
Note: if non-unique access keys are used, then it might be still better to have a primary key which is unique. This should simplify some parts of the API and the implementation. For example, to remove an element from the DB it is required to uniquely identify it (unless the application wants to remove any element matching the non-unique key which might be only useful in a few cases). If we don't have a unique key, then the application needs to search the correct data first and pass a context to the remove function which is in turn used as unique identifier (e.g., simply the pointer to the entry, but the structure should be kept opaque for abstraction).
In some cases the application data itself can provide a list of elements with the same key such that the access method can simply point to one element (usually the head of the list). It is then up to the application to access the desired elements. However, it might be useful to provide a generic method for this, at least in the form of macros to maintain such a list. For example, if the element to which the access structure points is removed, the (pointer in the) access structure itself must be updated. Such a removal function should be provided to the application programmer to minimize coding effort (and errors).
First we need to figure out what kind of access methods we need. This applies to the incoming queue, the active queue, and all other queues. Then we can specify an API that gives us those access methods. Of course we have to make sure that we do not restrict ourselves if we later come up with another access method that is useful but can't be implemented given the current specification. We also have to make sure that the API can be implemented efficiently. Just because we would like some access methods doesn't mean that we should really implement them in case they lead to slow implementations.
Question: do we need a recipient id? This might be necessary if the same recipient is given twice. Even though we could try to remove duplicates, there might be different arguments for the recipient command. It might not be useful, but we have to be able to deal with it. Answer: we need a recipient id as key to access the data in the various EDBs.
There must be some way to search for entries in an EDB according to certain criterias, e.g., recipient host (delivery agent, destination host), delivery time, in general: scheduling information.
Collection of thoughts (just so they don't get lost, they need reconsideration and might be thrown away):
The incoming envelope database (INCEDB) is the place where the queue manager stores its incoming queue. It is stored in memory (restricted size cache) and backed up on disk. Question: do we need two APIs or can we get along with one? There are some functions that only apply to the backup, but that can be taken care of by a unified API. However, this unified API is just a layer on top of two APIs, i.e., its implementation will make use of the APIs specific to the RSC and the disk backup. For the queue manager, the latter two APIs should be invisible. For the implementation, it might be useful to describe them here.
Question: When do we need access to the backup? Answer:
Decision: Use the disk-backup of the INCEDB purely for desaster recovery. So envelopes stay in the RSC if they can't be transferred to the ACTEDB as long as the RSC doesn't overflow. If it does we use the deferred EDB or we slow down mail reception.
Question: do we just store the data (addresses) in unchanged form in the INCEDB or do we store them in internal (expanded) form? In general we want the expanded form, but due to temporary problems during the RCPT stage external formats may be stored too. In that case the address must be expanded when read from the INCEDB before it is placed into the active queue. See also Section 3.13.6.
API proposal (this is certainly not finalized):
If the RSC stores data of different types, it must be possible to distinguish between them. This is necessary for functions that ``walk'' through the RSC and perform operations on the data or just for generic functions. A different approach would be to use multiple RSCs each of which stores only data of a unique kind. However, that wastes memory (internal fragmentation), since it cannot be known in advance in which relations the data needs to be stored, e.g., there might be only a few sessions with lots of transactions, or there might be many sessions with one transaction each.
The INCEDB stores envelope information only temporarily. The envelopes will usually be moved into the active queue. A reasonable implementation of the disk backup currently seems to be a logfile. This file shouldn't grow endlessly, so it must be rotated from time to time (based on size, time, etc). This is done by some cleanup task, which should be a low-priority thread. It reads the backup file and extracts that envelope data that hasn't been taken care of yet. These entries are consolidated into a new file and the files read will be removed or marked for reuse. The more often it runs the less memory it may need because then it doesn't need to read so many entries (hopefully). Question: should this be made explicit in the API or should this be a side effect of the commit operation, e.g., if logfile big enough, rotate it? It seems cleaner to have this done implicitly. But that might be complicated and it might slow down the QMGR in an unexpected moment. Making the operation explicit exposes the internal implementation and binds part of the queue manager to one particular implementation. This violates modularity and layering principles. However, we could get around this by making those functions (rotate disk backup) empty functions in other implementations. Decision: don't make the implementation visible at the API level. It's just cleaner. It can be some low-priority thread that is triggered by the commit operation.
Question: do we need to store session oriented data, e.g., AUTH and STARTTLS, in the INCEDB?
Question: how do we handle commits? Should that be an asynchronous function? That is, initiate-commit, and then get a notification later on? The notification might be via an event since the queue manager is mainly an event-driven program. This might make it simpler to perform synchronous (interactive) delivery, i.e., start delivery while the connection from the sender is still open and only confirm the final dot after delivery succeeded, which allows to not actually commit the content to stable storage. However, does this really help anything? There has to be a thread that performs the appropriate actions, so that thread would be busy anyway. However, most of the work is done by a delivery agent, so we don't need to block a thread for this. So we need another function: incedb_commit_done(IN incedb-handle, IN trans-id, IN commit_status, OUT status): trigger notification that envelope has been committed.
Question: should we use asynchronous operations (compare aio)? edb_commit(handle, trans-id, max-time): do this within max-time. edb_commit_status(handle, trans-id): check the status. How do we want to handle group-commits? We can't do commits for each entry by itself (see architecture section), so we either need to block on commit (threading: the context is blocked and when enough entries are there for committing or too much time passed, then the commits are actually performed and the contexts are ready for execution again), or we can use asynchronous operation. However, we don't want to poll, but we want to be notified. Does the API depend on the way we implement the queue manager? Since the QMGR is the only one with (write) access to the EDB, it seems so. But we need a similar interface for the CDB (see Section 3.13.7.1). So we should come up with an API that is more or less independent of the callers processing model. On the other hand, it doesn't make sense to provide different functions to achieve the same, if we don't need it (compare blocking vs. non-blocking I/O). It only makes it harder for us to implement the API. Todo: figure out whether EDB and CDB can use similar APIs for commits and how much that depends on the callers processing model (thread per connection, worker threads, processes).
The disk backup for the INCEDB should have its own API for the usual reasons (abstraction layer). API proposal (this is not finalized):
The last four functions deal with request lists. These lists contain status updates for transactions or recipients. Requests lists are used to support transaction based processing: all change requests are collected in a list and after all of the necessary operations have been performed, the requests are committed to disk. This is for example helpful in a loop that updates status information: instead of updating the status for each element one by one, the changes are collected in a list. If during the processing of the loop an error occurs which requires that all changes are undone, then the request list can simple be discarded (ibdb_req_cancel()). If the loop finished without errors, then the requests are committed to disk (ibdb_wr_status()). This also has the advantage of being able to implement group commits, which may result in better performance.
Question: do we need ibdb_trans_discard()? If the transaction data is only stored after the final dot, then we wouldn't need it. However, that might cause unnecessary delays, and in most cases mails are transmitted and accepted without rejected after the final dot (or transmission aborts due to timeouts etc). We could also merge ibdb_trans_rm() and ibdb_trans_discard() by adding a status parameter to a common function, e.g., ibdb_trans_end().
The active envelope database (ACTEDB) is the place where the queue manager stores its active queue, it is implemented as a restricted size cache. The active queue itself is not directly backed up by disk, but other queues on disk act as (indirect) backup.
Todo: clarify this API.
| Routine | Arguments | Returns |
| actedb_open | name, size | status, actedb-handle |
| actedb_close | actedb-handle | status |
| actedb_env_add | actedb-handle, sender-env-info | status |
| actedb_env_rm | actedb-handle, trans-id | status |
| actedb_rcpt_add | actedb-handle, trans-id, rcpt-env-info | status |
| actedb_rcpt_status | actedb-handle, trans-id, rcpt, d-stat | status |
| actedb_rcpt_rm | actedb-handle, trans-id, rcpt-env-info | status |
| actedb_commit | actedb-handle, trans-id | status |
| actedb_discard | actedb-handle, trans-id | status |
We need some support functions for the API specified in Section 3.4.5.1 to manipulate the Delivery Agent DB whose purpose and content has been explained in Section 3.4.10.12.
Open a DA DB.
Close a DA DB.
Open a session and transaction. session contains the destination host to which to connect. The created dadb-entry contains newly created session and transaction handles.
Open a transaction. The updated dadb-entry contains a newly created transaction handle.
Close a transaction.
Close a session.
The deferred envelope database (DEFEDB) is obviously the place where the queue manager stores the deferred queue.
Question: do we need session oriented data in the deferred EDB? Answer: shouldn't be necessary, all data required for delivery is in the envelopes (sender and recipients and ESMTP extensions). Note: this assumes that nobody is so wierd and uses session oriented data for routing. There might be people who want to do that; can those be satisfied by allowing additions to the data similar to ``persistent macros'' in sendmail 8?
We need several access methods for the EDB (from the QMGR for scheduling). Question: can we build indices for access ``on-the-fly'', i.e., can we specify a configuration option: `use field X as index' without having code for each field? Answer: we probably need at least code per data type (int, string, ...). Question: is this sufficient? How about (DA, host) as index or something similarly complicated?
Todo: clarify this API.
| Routine | Arguments | Returns |
| defedb_open | name, mode | status, defedb-handle |
| defedb_mail_add | defedb-handle, sender-env-info | status |
| defedb_env_rm | defedb-handle, trans-id | status |
| defedb_rcpt_add | defedb-handle, trans-id, rcpt-env-info | status |
| defedb_rcpt_status | defedb-handle, trans-id, rcpt, d-stat | status |
| defedb_rcpt_rm | defedb-handle, trans-id, rcpt-env-info | status |
| defedb_commit | defedb-handle, trans-id | status |
| defedb_readprep | defedb-handle | status, cursor |
| defedb_getnext | cursor | status, record |
| defedb_close | defedb-handle | status |
The last three functions deal with status change requests, similar to those for IBDB (see Section 3.13.4.3).
Possible implementations:
About option 3:
The basic idea about a cyclical file system is to create a fixed
set of files and reuse them.
In this particular case we need files that represent the times
at which queue entries should be tried again
(theoretical maximum: Timeout.queuereturn, practical maximum: max-delay).
Subdivide the maximum time into units, e.g., 1 minute,
and use the files for the queue in round robin fashion.
Each file represents the entries that are supposed to be tried
at
![]() .
So a new entry (which represents a deferred mail/recipient)
is placed into the file which represents its next-retry-time.
If an entry is delayed again, it is appended to the appropriate file.
Since the QMGR is supposed to take care of all entries that are
to be tried
.
So a new entry (which represents a deferred mail/recipient)
is placed into the file which represents its next-retry-time.
If an entry is delayed again, it is appended to the appropriate file.
Since the QMGR is supposed to take care of all entries that are
to be tried ![]() , the file will be afterwards ``empty'',
i.e., no entry in the file is needed anymore.
, the file will be afterwards ``empty'',
i.e., no entry in the file is needed anymore.
Possible problems:
Whenever an entry is added to the deferred queue a reason is specified (d-stat). The entry also contains scheduling information, see 3.4.10.6. This data can be used by the implementation to treat the entry accordingly.
Note: Courier-MTA uses something remotely similar: it stores the queue files according to the next retry time, see courier/doc/queue.html.
The mail queue consists of two directories: LSDIR/msgs and LSDIR/msgq. The control file is stored in LSDIR/msgs/nnnn/Ciiiii, and the data file is LSDIR/msgs/nnnn/Diiiiii. ``iiiiii'' is the inode number of the control file. Since inode numbers are always unique, the inode is a convenient way to obtain unique identifiers for each message in the mail queue. ``nnnn'' is the inode number hashed, the size of the hash is set by the configure script (100 is the default, so this is usually just the last two digits of the inode number).
One item of information that's stored in the control is the time of the next scheduled delivery attempt of this message, expressed as seconds since the epoch. There is also a hard link to the control file: LSDIR/msgq/xxxx/Ciiiiii.tttttt. ``tttttt'' is the next scheduled delivery time of this message. ``xxxx'' is the time divided by 10,000. 10,000 seconds is approximately two and a half hours. Each subdirectory is created on demand. Once all delivery attempts, scheduled for the time range that's represented by each subdirectory, have been made, the empty subdirectory is deleted. If a message needs to be re-queued for another delivery attempt, later, the next scheduled delivery time is written into the control file, and its hard link in LSDIR/msgq is renamed.
This scheme comes into play when there is a large amount of mail backed up. When reading the mail queue, Courier doesn't need to read the contents of any directory that represents a time interval in the future. Also, Courier does not have to read the contents of all subdirectories that represent the current and previous time intervals, when it's falling behind and can't keep up with incoming mail. Courier does not cache the entire mail queue in memory. Courier needs to only cache the contents of the oldest one or two subdirectories, in order to begin working on the oldest messages in the mail queue.
About option 2: this may be simple because it requires only little implementation effort since the DB is already available. However, it isn't clear whether the DB is fast and stable enough. Considering the problems that other Sendmail projects encounter with Berkeley DB we have to be careful. Those problems are mainly related to locks help by several processes. In case a problem occurs and a process that holds a DB lock aborts without releasing the lock, all processes must be stopped and a recovery run must be started. In sendmail X we do not have multiple processes accessing the same EDB, only the QMGR has access to those. Hence the problem is minimized, we still need to make sure that in case of an abort the DB locks are properly released. However, we may even be able to use BDB without using its locks. If we lock the access to the DB inside the QMGR itself, then we avoid the DB corruption problem. Using locks inside the QMGR to sequentialize access to an EDB does not seem like a big problem. This would lead to some coarse-grain locking (obtain a mutex before accessing the DB), but that might be ok. It might even be possible to use BDB as cyclical filesystem, but that is something we have to investigate. The cyclical filesystem idea restricts the access methods to the recipient records to a purely sequential way, other access methods would be fairly expensive (require exhaustive search or at least other indices that may require many updates).
BDB provides a fairly easy way to use multiple indices to access the DB: the DB->associate method can link a secondary index to a primary and there can be multiple secondary indices (see [Sleb]: Berkeley DB: Secondary indices).
Instead of keeping secondary indices on disk (and hence increasing disk I/O which usually is a scarce resource), we may want to keep them in main memory and just restrict their size. Since they are just indices, i.e., they just contain a pointer (e.g., the main key for the DB), the size of each entry can be fairly small. For example, if the recipient identifier is used as main key then that's about 25 bytes (see Section 4.1.1). If then a secondary index is based on the `next time to try' the overall size of the index is less than 32 bytes by entry (assuming a 4 byte time value). Hence even storing 100000 entries will only require about 3 MB of memory (only data; using an AVL tree will add about 20 bytes per entry on a 32 bit machine, hence resulting in a total of about 5 MB). If a system really has that many entries in the queue then the size of the secondary index seems fairly small compared to the amount of data it stores on disk (and the common memory sizes). Moreover, it should be possible to use restricted size caches for some indices and fill them up based on scanning the main queue. Coming back to our example of using `next time to try' as secondary index, the data can be sorted (e.g., using AVL trees) and limiting the number of entries to some configurable value. Then we can simply remove entries that are too far away (their `next time to try' is too far in the future for immediate consideration) when the cache is full and new entries must be added.
Note that not each transaction must be committed to disk immediately. It is not acceptable to lose mail, but it is acceptable (even though highly undesireable) to have mail delivered multiple times. Hence the information that a message has been accepted and not yet successfully delivered must always safely be stored on persistent storage. However, the fact that a mail has been delivered is not of that high importance, i.e., multiple of these informations can be committed in a group to minimize transaction costs. See also the sendmail 8 option CheckpointInterval and Section 3.13.11.
Note: transaction ids in old Berkeley DB versions (before 4.0.14 according to [Slea]) are 32 bit integers (of which only 31 bit are available) and hence may be exhausted rather soon. They are reset by running recovery, which hence might be necessary to do on a regular basis (at least on high volume systems).
The content database stores the mail contents, not just the mail bodies (see 2.17).
Possible implementations:
Question: will the CDB be implemented as library or as a process by itself? In the former case there might be a problem to coordinate access to the CDB. If the CDB is accessed from different processes, then some form of locking may be required. This should be handled internally by the CDB implementation.
We need an API (access abstraction) that allows for different implementations. The abstraction must be good enough to allow for simple implementations (e.g., one file per mail content) as well as maybe complicated and certainly fast ones. It must be possible to use just memory storage if delivery modes allow for this (compare interactive delivery in sendmail 8), and it must be possible to use some remote storage on a distributed system. The API must neither exclude any imaginable implementation (as long as it makes some sense), nor must it keep us from doing extremely efficient implementations. It must accommodate (unexpected) changes in the underlying implementations during the lifetime of sendmail X.
Question: what exactly do we need here?
First we need to get a handle for a CDB. We may have to create a CDB before that but it seems better to do this outside the system with other programs, e.g., just like you have to set up queue(s) right now. It might be more flexible to create CDBs on demand (e.g., new directories to avoid ``overflowing'' the ones that exist), however, that doesn't seem to belong in the SMTP server daemon. If the CDB implementation needs it, it should do it itself whenever its operation requires it.
Question: what about different file systems for CDB? Maybe the user has a normal disk, a RAID, a memory file system, etc. So we need also some ideas how to use different file systems, which should be controllable by the user. Do we really want to make it that complicated? Can we hide this in the API and use ``hints'' in the open call? That should be good enough (for now); but it is sufficiently general?
We need to create a storage for the mail content per envelope. We should give it the transaction id and if existent the SIZE parameter. The library returns an id (content-id) and a status.
To make the interface flexible, there are two identifiers: transaction id as created by SMTPS and stored in the envelope data. If it proves to be useful or necessary, the CDB implementation can return its own identifier which will be used for further function calls (and will be stored in the envelope data too). It's not yet clear which data types to use, currently character strings are fairly likely. If the CDB doesn't want/need to generate its own ids, it can simply return the transaction id. If the CDB is realized as a library, the content-id may be an opaque pointer (or a small integer like a fd).
Question: should read/write maintain the data pointer (offset) themselves (hidden behind content-id) or should this be passed back to the caller? If it is hidden, the calls might be optimized (assuming there is only one writer/reader at a time, which may not be true if we use interleaved delivery). The implementation must allow one writer and several readers concurrently.
Question: should all functions have cdb-handle as input? That allows to have multiple CDBs open at a time. It seems to be useful, because that makes the API more generic. However, the cdb-handle could be ``hidden'' in the content-id. For now, keep cdb-handle as parameter. If we don't use cdb-handle explicitly all the time, the interface is almost the same as for (file) I/O. Hence the question: do we want to use the same API? The I/O API call sm_io_setinfo() can be ``abused'' to implement calls like cdb_commit(), cdb_abort(), and cdb_unlink().
We have the same problem here as with the envelope DB: how to perform group commits? However, we probably can't use the solution (whatever it may be) from the QMGR in the SMTPS. The mechanism may depend on the process model of the respective module; it might be different in a program that uses worker threads from one that uses (preforked) processes or per connection threads. If we use per connection threads then we can simply use a blocking call: we can't do anything else (can we?) inbetween, we have to wait for the commit to give back the 250 (or an error). Moreover, most of the proposals how to implement the CDB do not even allow for group commits (unless the underlying filesystem provides this facility somehow). For example, if one file per mail content is used, then it is impossible in FFS to perform a group commit; each file has to be fsync(2)ed on its own.
Proposal 2 (see Section 3.13.7) basically tries to get around the problem of fast writes and group commits (synchronous meta-data operations). By using a log-structured filesystem (implemented by sendmail X or maybe just used on some OS that actually provide such a filesystem), writing contents to disk should be significantly faster (an order of magnitude) than using a conventional filesystem and one file per mail [SSB+95].
In the following, we take a look at some variations of this topic.
For some references on log-structured filesystems and their performance relative to conventional filesystems see [RO92], [SBMS93], and [SSB+95]. Especially [SSB+95] indicates that proposal 2 (see Section 3.13.7) may not work as good as hoped. The main reason for this is garbage collection, which can decrease performance by up to 40%, which in turn causes LFS and FFS to have similar performance.
Question: can we use a cyclical filesystem also for the CDB? In addition to the problems mentioned in Section 3.13.6.1 for case 3 we also have a different garbage collection problem. If we store the mail content in files related to their arrival time, and do not reuse them until the maximum queue time is reached, then we have a huge fragmentation, but we would get garbage collection for free since we will simply reuse the storage after the timeout. How much was would this be? Let's assume we achieve a throughput of 10MB/s, that's 36GB/h, which is 864GB/day. Even though 100GB IDE disks can be bought for $2003.21, that's a lot of waste. Moreso due to the number of disks and hence controllers required. Therefore this proposal seems too wierd, it requires too much hardware, most of which is barely used. Since most mail is delivered almost immediately, probably more than 90% of that space would be wasted, i.e., used only once during the reception and (almost immediate) delivery of a mail.
It seems that garbage collections is the main problem for using log-structured filesystems as CDB for sendmail. However, maybe a property of the mail queue can help us to alleviate that problem. Garbage collection in conventional log-structured filesystems must be able to reclaim space in partially used segments (see [SSB+95] for the terminology). This requires compacting that space, e.g., by retrieving the ``live'' data and storing it in another segment and then releasing the old segment. Doing that requires of cause disk access and hence reduces the available I/O bandwidth. Therefore it should be avoided. Instead of reclaiming partially free segments only entirely free segments will be reclaimed, which doesn't require any disk access (except for storing the information on disk, i.e., the bitmap for free/used segments). This should be feasible without causing too much fragmentation since the files in the mail queue have a limited lifetime. Hence the general problem that a filesystem has to deal with doesn't (fully) apply here. It should be possible to reclaim most segments after a fairly short time. This approach might be something we can persue in a later version of sendmail X, for 9.0 it is definitely too much work. Even if we can get access to the source code of a log-structured filesystem (as offered by Margo Seltzer in [SSB+95], pg. 16), that code is in the kernel and hence would require a significant effort to rewrite. Moreover, it is not clear how much such a code would interfere with the (U)VM of the OS.
Proposal 5 looks like a strange idea. However, it may have some merits, i.e., it gives us group commits. If we use the transaction id concatenated with a block number as key, then the value would be the corresponding block. Group commits are possible due to the transaction logging facility of BDB. Whether this will give good performance (esp. for reading) remains to be seen (tested).
General notice: currently it is claimed that meta-data operations in Unix file systems are slow and this (together with general I/O limits of hard disks) limits the throughput of an MTA. However, there are file systems that try to minimize the problem, e.g., softupdate (for *BSD), ext3, ReiserFS (Linux), and journalling file systems (many Unix versions). We may be able to take advantage of those file system enhancements to minimize the amount of work we have to do to implement a high performance MTA. Moreover, in high-performance systems disks with large NVRAM caches will be used, thus making disk access really fast.
Idea for simple CDB: keep queue files around and reuse them. That should minimize file creation/deletion overhead. However, does it really minimize meta-data operations? As it is shown in Section 5.2.1.2.1, some filesystems seem to become actually slower when reusing existing files.
The queue manager keeps track of all connections:
The first two should be kept in memory, the last two can be stored on disk.
The open connections must be completely available in memory. The older connections can be limited to some maximum size, using something like LRU to throw expired connection out of the cache.
The connection caches should contain all information that might be relevant for the queue manager:
For more details see 3.4.10.8 and 3.4.10.10.
Do we want to look into other databases than Berkeley DB? How about:
Some data should be stored in memory but the amount of memory used should be limited. For example, the connection caches must be limited in size.
An RSC stores only pointers to data. We may need to create a copy of the data for the RSC for each new entry, in which case a entry_create() function should be passed to rsc_create().
Returns a status and (if successful) a handle (otherwise NULL).
Question: how do we implement such caches? If the cache size is small, then we can create a fixed size array. We can then simply use a linear search for entries. Up to which size is this efficient enough?
If linear search becomes too slow, we need a better organization. We need two access methods: First by key, second by time. So we need to maintain two lookup structures for the array. The first one for the key can be a b-tree, the second one for the time can be a linked list or a b-tree.
We can use a ring buffer (fixed size linked list; fixed size array) for the time access. If the list is supposed to expire purely based on the time when an entry has been entered, then that organization is the simplest and fastet: when the buffer is full, just remove the tail (which is the oldest entry). If the expiration is based on LRU then a new entry can be made each time. The old one can be either removed (esp. if it is linked list), or marked as invalid (free). In the latter case the effective size would shrink which might not be intended but may be reasonable to get efficient operations.
One possible implementation can be taken from postfix: ctable.
For some structures it might be useful to vary the size of a cache depending on the load. Question: which ones are these? Is this really necessary? A possible implementation might be to link RSCs together, but that might be complicated if b-trees are used for lookups. Moreover, shrinking a cache is non-trivial, the question is whether it's worth to save some memory versus the computational overhead for shrinking.
For some operations atomic update are necessary or at least very useful. Such operations include updates of the delivery status of an email. In previous sendmail versions, rename(2) is used for atomic changes, i.e., to write a new qf file a tf fike is written and then rename(tf, qf) is used. BSD FFS provides this guarantee for rename(const char *from, const char *to):
rename() guarantees that if to already exists, an instance of to will always exist, even if the system should crash in the middle of the operation.
However, sendmail 8 doesn't update the delivery status of an envelope all the time by default:
CheckpointInterval=: Checkpoints the queue every
sendmail X can behave similar, which means that atomic updates are not really necessary. However, it must made sure that there is no inconsistent information on disk, or that at least sendmail can determine the correct state out of the stored data.
Question: are disk writes atomic? As long as they are within a block, are they guaranteed to leave the file in a consistent state? Can we figure out whether the write is within a block? If it spans multiple blocks, it may cause problems. Otherwise a write could be used for an atomic update, e.g., a reference counter or status update, without having to copy a file or create a new entry. If we can do ``atomic one byte/block writes'', we can update the information with an fseek(); write(new_status,1). Remark: qmail-1.03/THOUGHTS [Ber98] contains this paragraph:
Queue reliability demands that single-byte writes be atomic. This is true for a fixed-block filesystem such as UFS, and for a logging filesystem such as LFS.
If we store several queue file entries in a single file instead of each entry in an individual file (or some database), then the following layout instructions should be observed. Note: the same structure will be used for communication between sendmail X modules, see also Section 1.3.1 about this decision.
It might be useful to implement the queue files using a record structure with fixed length entries. This allows easy access to individual entries instead of sequentially reading through a file. To deal with variable length entries, continuation records can be used. Even if we don't use fixed size records, the entries should be structured as described below (tagged data including length specification). This allows for fast scanning and recognition without relying on parsing (looking for an end-of-record marker, e.g., CR).
The first record must have a version information and should contain a description of the content. It must have the length of the records in this file. Possible layout: record length (32 bit), version (32 bit), content description, maybe similar to a printf format string; see also Section 3.16.11.1.
Each record contains first the total length of the entry (in byte, must be multiple of the record length), then a type (32 bit), and then one or more subentries. The type should contain a continuation flag to denote whether this is the first or an continuation record. The last record has a length (less or) equal to the record length. It also has a termination subentry to recognize that the record is completely written to disk when it is read. Each of the subentries consists of its length (32 bit, must be multiple of 4 to be aligned), type (32 bit), and content. The length specifies only the length of the data, it doesn't include the type (or the length itself). We could save bytes if we do this the other way round: type first, then optionally length, whereby length can be omitted if the type says its a fixed size entry (32 bit as default). However, this probably makes en/decoding more complicated and is not worth the effort. Question: should each subentry be terminated by a zero character? If an entry doesn't fit into the record, a continuation record is used and the current record is padded, which is denoted by a special type. The termination subentry is identified by its type. Additionally, it might be useful to write the entire length of the record as value to minimize the problem of mistakenly identifying garbage on the disk as valid record. We won't use a checksum because the requires us to actually read through all the data before we can write it. Notice: variable length data should be aligned on 4 byte boundaries to allow things like accessing a (byte) buffer as an integer value. On 64bit systems it might be necessary to use 8 byte alignment.
Some open questions:
Note: see also xdr(3).
Note: this might be not needed if we go with Berkeley DB for the envelope DB. However, the ``queue'' access type for Berkeley DB works only with fixed sized records, so there may be a use for the following considerations.
Let's do some size estimates for INCEDB, i.e., the disk back (see Section 3.13.4.3 and 3.4.10.4). The smallest size should be 4 bytes (32 bit word); for each entry a description (type) and length field is used additionally (see above).
| entry | length (bytes) |
| transaction-id | 20, up to 32 or even 64 |
| start-time | 8 |
| cdb-id | up to 64 |
| n-rcpts | 8 |
| sender-spec | up to 256 (RFC 2821) plus ESMTP extensions |
| size | 8 |
| bodytype | 4 |
| envid | up to 100 (RFC 1891) |
| ret | 4 |
| auth | no length restriction? (RFC 2554, refers to 1891) |
| by | 10 for time, 1 (4?) for mode/trace |
| entry | length (bytes) |
| transaction-id | 20, up to 32 or even 64 |
| rcpt-spec | up to 256 (RFC 2821) plus ESMTP extensions |
| maybe a unique id (per session/transaction?) | |
| notify | 4 |
| orcpt | up to 500 (RFC 1891) |
If we use a default size of 512 bytes, then we would get 100 KB/s if the MTA can deal with 1000 msgs/s (for one recipient per message, if it would be two - which is more than the average - it still would be only 150 KB/s). This is fairly small and should be easily achievable. Moreover, it doesn't amount to much data, e.g., for one day (without cleanup) it would be 12 GB (for very large traffic, i.e., 86 million messages).
Some questions and ideas; this part needs to be cleaned up.
Generic idea (see the appropriate sections earlier on which may have more detailled information): EDB: maybe use some of those as files (just append) and switch to a new one at regular intervals (time/size limits). The old one will be cleaned up then: all entries for recipients that have been delivered will be removed (logged), new file will be created. This has to be flexible to deal with ``overflow'', i.e., many of these files might be used, not a fixed set.
In some cases it might be useful to store domain names in reverse order in a DB (type btree). Then a prefix based lookup can (sequentially) return all subdomains too. Whether host.domain.tld should be stored as dlt.niamod.tsoh or tld.domain.host remains to be seen (as well as whether this idea makes much sense at all).
As explained in Section 2.12 maps are used to lookup keys and possibly replace the keys with the matching RHS. The required functionality exceeds that of default lookups (exact match) which can be provided by performing multiple lookups in which parts of the key are omitted or replaced by wildcard patterns (see 3.14.2). Accordingly replacement must provide a way to put the parts of a key that have been omitted or replaced into the RHS; this is explained in Section 3.14.3.
A map lookup has two results3.22:
Section 2.12 explains the problem of checking subdomains (pseudo wildcard matches). The solution chosen3.23is a leading dot to specify ``only subdomains'' (case 2.12 in Section 2.12).
Below are the cases to consider. Note: in the description of the algorithms some parts are is omitted:
Notes:
In sendmail 8 there are various places where (parts of) e-mail addresses are looked up: aliases, virtusertable, access map. Unfortunately, all of these use different patterns which are inconsistent and hence should be avoided:
Question: should this be made consistent? If yes, which format should be chosen? By majority, it would be: user@host, user, @host. A compromise could be to always use the '@' sign to distinguish an e-mail address (or a part of it) from a hostname or something else: user@host, user@, @host.
The RHS of a map entry can contain references to parts of the LHS which have been omitted or replaced into the RHS. In sm8 this is done via %digit where the arguments corresponding to the digits are provided in the map call in a rule. Since sendmail X does not provide rulesets, a fixed assignment must be provided. A possible assignment for case 3 (see previous section) is:
| digit | refers to |
| 0 | entire LHS |
| 1 | user name |
| 2 | detail |
| 3 | +detail |
| 4 | omitted subdomain? |
Functions can return errors in different way:
We will not use one general error return mechanism just for sake of uniformity. It is better to write functions in a ``natural'' way and then choose the appropriate error return method.
Question: is timeout an error? Usually yes, so maybe it should be coded as one.
Question: Do we want to use an error stack like OpenSSL does? This would allow us to give more information about problems. For example, take a look at safefile(): it only tells us that there is a problem and what kind of problem, but it doesn't exactly say where. That is: Group writable directory can refer to any directory in a path. It would be nice to know which directory causes the problem.
OpenSSL uses a fixed size (ring) buffer to store errors (see openssl/include/err.h), which is thread specific.
A detailed error status consists of several fields (the status, i.e., all of its fields, must be zero if no error occurred):
As explained in 3.15.1 some functions return positive integers as valid results, hence negative values can be used to indicate errors. To facilitate this, the error codes will always be negative, i.e., the topmost bit is set.
So overall the error status is encoded in a signed 32 bit integer (of course typedef will be used to hide this implementation detail). Macros will be used to hide the partitioning of the fields to allow for changes if necessary.
In some cases a numeric error status is not sufficient, an additional description (string) is required or at least useful. This can be made available as a result parameter, however, see also the next section how errors can be returned.
If modules are used, it is hard to have a single function that converts an error code into a textual description like strerror(3) does as Section 3.17 explains. The subsystem field in the error value can be used to call the appropriate conversion function.
If we want to be extremely flexible, then a module can register itself with a global error handler. It submits its own error conversion function and it receives a subsystem code. This would make the subsystem code allocation dynamic and will avoid conflicts that otherwise may arise. Question: is this too complex?
Minor nit about tags in structures for assertion that the submitted data is of the right type. 8.12 uses strings, a nice integer value is sufficient, e.g., 0xdeadbeef, 0xbc2001. Then the check is just an integer comparison instead of a strcmp(). Currently it's just a pointer comparison, so it's probably not much difference. Question: is this guaranteed to work? Someone reported problems on AIX 4.3, it crashes in the assertion module. The reason for that is a bug in some AIX C compiler that does not guarantee the uniqueness of a C const char pointer. Bind 9 uses a nice trick defining a magic value as the ``concatenation'' of four characters (in a 32 bit word). Even though this restricts the range of magic values, at least it helps debugging since it could be displayed as string.
sendmail X should make use of many libraries such that the source code of the main programs is only relatively small and easy to follow. Most complexity should be hidden in libraries, such as different I/O handling with timeouts and for different OS as well as different actual lower layers (e.g., IPv4 vs IPv6). The more modules are implemented via libraries, the easier it should be to change the underlying implementations to accomodate different requirements and to actually reuse the code in other parts of sendmail X as well as other projects.
| _T | type |
| _E | enum |
| _F | function |
| _P | pointer |
| _S | structure |
| _U | union |
_T is default, the other should be only used if necessary.
| _new() | create a new object |
| or _create() | |
| _destroy() | destroy object (other name?) |
| _open() | open an object for use, this may perform an implicit new() |
| _close() | close an object, can't be used unless reopened, this does not destroy the object |
| _add() | add an entry to an object |
| _rm() | remove an entry from an object |
| _alloc() | allocate an entry and add it to an object |
| _free() | free an entry and remove it from an object |
| _lookup() | lookup an entry, return the data value |
| _locate() | lookup an entry, return the entry |
There are many alternative names used for lookup: search, find, and get. The latter is used by BBD and even though it implies that a value is returned, it is a bit overloaded by the I/O function with that name, which return the next element, without implying that a specific entry is requested.
| X_ctx | context for object X |
| X_next | pointer to next element for X |
| X_nxt | pointer to next element for X (if X is a long name) |
| _state | state (if the object goes through various states/stages) |
| _status | status: what happened to the object, e.g., SMTP reply code |
| _flags | (bit mask of) flags that can be set/cleared/checked |
| more or less independent of each other |
The distinction between state and status is not easy. Here's an example: A SMTP server transaction goes through various stages (states): none, got SMTP MAIL/RCPT/DATA command, got final dot. The status should be whether some command was accepted, so in this case the two are strongly interrelated. It probably depends on the object whether the distinction can be made at all and whether it's useful. For example, the status might be stored in the substructures, e.g., the mail-structure has the response to the SMTP MAIL command.
As shown in Section 3.16.1.1 a structure definition in general looks like this:
typedef struct abc_S abc_T, *abc_P;
struct abc_S
{
type1 abc_ctx;
type2 abc_status;
type3 abc_link;
};
| X_link | link for list X |
| X_lnk | link for list XYZ (if X is a long name) |
| X_l | link for list XYZ (if X is a really long name) |
Note: link is used for structure elements instead of next which is used for variables. This makes it easier to distinguish variables and structure elements.
The name of macros should indicate whether they can cause any side effects, i.e., whether they use their arguments more than once and whether they can change the control flow. For the former, the macro should be written in all upper case. For the latter, the macro should indicate how it may change the control flow as depicted in the next table.
| _B | break |
| _C | continue |
| _G | goto |
| _E | jump to an error label |
| _R | return |
| _T | terminate (exit) |
| _X | some of the above |
Macros that include assert statements don't need to be of any special form, even though _A could be used; however, many functions use assert/require too without indication of doing that in their name.
All include files in sendmail program code will refer to sendmail X specific include files. Those sendmail X specific files in turn will refer to the correct, OS dependent include files. This way the main program modules are not cluttered with preprocessor conditionals, e.g., #if, #ifdef.
sendmail X will use its own I/O layer, which might be based on the libsm I/O of sendmail 8.12. However, it must be enhanced to provide an OS independent layer such that sendmail X doesn't have to distinguish in the main code between those OSs. Moreover, it should be a stripped-down version containing only functions that are really needed. For example, it should have record oriented I/O functions (record for SMTP: a line ending in CRLF), and functions that can deal with continuations lines (for headers).
How should the I/O layer work?
It should buffer reads and writes in the following manner:
Requirements of SMTPS for data:
How to read the data with the least effort? We cannot just read a buffer and write it entirely to disk (give it to the CDB) because we need to recognized the trailing dot. The smtpsdata() routine should have access to the underlying I/O buffer. We could either be ugly and access the buffer directly (which violates basic software design principly, e.g., abstraction), or we can provide a function to do that. In principle, sm_getc() is that function, but it can trigger a read, which we don't want. If the buffer is empty, we want to know it, write the entire buffer somewhere, and then trigger a read. We could add a new macro: sm_getb() that returns SM_EOB if the buffer is empty. Note: to do this properly (accessing the buffer almost directly) we should provide some form of locking. Currently it's up to the application to "ensure" that the buffer isn't modified, i.e., the file must not be accessed in any other way inbetween.
The I/O buffer currently consists of the following elements:
| int | size | total size |
| int | r | left to read |
| int | w | left to write |
| int | fd | fileno, if Unix fd, else -1 |
| sm_f_flags_T | flags | flags, see below |
| uchar | *base | start of buffer |
| uchar | *p | pointer into buffer |
This implements a simple buffer. The buffer begins at base and its size is size. The current usage of the buffer is encoded in flags. The interesting flags for the use as buffer are:
| RD | currently reading |
| WR | currently writing |
RD and WR are never simultaneously asserted. RW open for reading and writing, i.e., we can switch from one mode to the other.
The following always hold:
flags&RD ![]() w = 0
w = 0
flags&WR ![]() r = 0
r = 0
This ensures that the getc and putc macros (or inline functions) never try to write or read from a file that is in `read' or `write' mode. (Moreover, they can, and do, automatically switch from read mode to write mode, and back, on "r+" and "w+" files.)
r/w denote the number of bytes left to read/write.
![]() is the read/write pointer into the buffer, i.e., it points
to the location in the buffer where to read/write the next byte.
is the read/write pointer into the buffer, i.e., it points
to the location in the buffer where to read/write the next byte.
|<- size ->| |----------------|--------| ^ ^ ^ base p base + size
RD
![]()
WR
![]()
The buffer acts as very simple queue between the producer and the consumer. ``Simple'' means:
``Real'' queues would have different pointers to write/read for
the producer and consumer such that the queue is entirely utilized.
However, that causes problems at ``wrap-around'', esp. if more than just
one item (byte) should be read/written: it must be done piecewise
(or at least special care must be taken for the wrap-around cases).
We can do something like that because ![]() is our
pointer to write more data into the buffer.
is our
pointer to write more data into the buffer.
The main part of most sendmail X programs is an event driven loop.
For example, the SMTP server reads data from the network and performs appropriate actions. The context for each server thread contains a function that is called whenever an I/O event occurs. However, if we use non-blocking I/O (which we certainly do), we shouldn't call a SMTP server function (e.g., smtps_mail_from) on each I/O event for that thread, but only if complete input data for that middle-level function is available. As stated before (see 3.16.3) the I/O layer should be able to assemble the input data first. So the thread has an appropriate I/O state which is used by the I/O layer to use the right function to get the input data. During the SMTP dialogue this would be an CRLF terminated line, if CHUNKING is active it would be an entire chunk.
Event driven programming can be fairly complicated, esp. if events can occure somewhere ``deep down'' in a function call sequence. We have to check which programs are easy to write in an event based model, and how we can deal with others (appropriate structuring or using a different model, e.g., threads per connection/task).
If a blocking call has to be made inside a function, it seems that the function must be split into two parts such that the blocking call is the divider, i.e., the function ends with a call that initiates the blocking function. The blocking function must be wrapped into an asynchronous call, i.e., an ``initiate'' call and a ``get result'' call. The function must trigger an event that is checked by the main loop. Such a wrapper can be implemented by having (thread-per-functionality) queue(s) into which the initiate calls are queued. A certain number of threads a devoted to such queue(s) and take care of the work items. When they are done they trigger an (I/O?) event and the main event loop can start the function that receives that result and continues processing. This kind of programming can be become ugly (see above).
sendmail X will reuse the rpool abstraction available in libsm (with the exception of not using exceptions). Moreover, there should be an rpool_free_block() function even though it may actually do nothing. An additional enhancement might be the specification of an upper limit for the amount of memory to use.
In addition to resource pools (which are only completely freed when a task is done), it might be useful to have memory (de)allocation routines that work in an area that is passed as parameter. This way we can restrict memory usage for a given functionality.
A debugging version of malloc/free can be taken from libsm. It might be useful to provide a version that can do some statistics, see malloc(9) on OpenBSD.
In case of memory allocation problems, i.e., if the system runs out of memory, the usage has to be reduced by slowing down the system or even aborting some actions (connections). The system should pre-allocate some amount of memory at startup which it can use in case of such an emergency to allow basic operation. The pre-allocated memory can either be explicitly used by specifying it as parameter for memory handling routines, or it can be simply free()d such that system operation can continue. It's not yet clear which of those both approaches is better.
sendmail X should have a string abstraction that is better than
the way C treats ``strings''
('![]() 0' terminated sequences of characters).
They may be modelled after postfix's VSTRING abstraction or libsmi,
the latter seems a good start.
They should make use of rpools to simplify memory management.
We have to analyze which operations are most needed and optimize
the string abstraction for those without precluding other
(efficient) usages.
Some stuff:
0' terminated sequences of characters).
They may be modelled after postfix's VSTRING abstraction or libsmi,
the latter seems a good start.
They should make use of rpools to simplify memory management.
We have to analyze which operations are most needed and optimize
the string abstraction for those without precluding other
(efficient) usages.
Some stuff:
Note: it might be useful to have a mode for snprintf() that denotes appending to a string instead of writing from the beginning. Should this be a new function or an additional parameter? The former seems the best at the user level, internally it will be some flag.
Even though strings should dynamically grow, there also need to be a way to specify an upper bound. For example, we don't want to read in a line and run out of memory while doing so because some attacker feeds an ``endless'' line into the program.
The string structure could look like this:
struct sm_str_S
{
size_t sm_str_len; /* current length */
size_t sm_str_size; /* allocated length */
size_t sm_str_maxsz; /* maximum length, 0: unrestricted? */
uchar *sm_str_base; /* pointer to byte sequence */
rpool_t sm_str_rpool; /* data is allocated from this */
}
Some strings are only created once, then used (read only) and maybe copied, but never modified. Those strings can be implemented by using reference counting and a simplified version of the general string abstraction.
struct sm_cstr_S
{
size_t sm_cstr_len; /* current length */
unsigned int sm_cstr_refcnt; /* reference counter */
uchar *sm_cstr_base; /* pointer to byte sequence */
}
Copying is then simply done by incrementing the reference counter. This is useful for identifiers that are only created once and then read and copied several times.
Available functions are:
/* create a cstr with a preallocated buffer */ sm_cstr_P sm_cstr_crt(uchar *_str, size_t _len); /* create a cstr by copying a buffer of a certain size */ sm_cstr_P sm_cstr_scpyn(const char *_src, size_t _n); /* duplicate a cstr */ sm_cstr_P sm_cstr_dup(sm_cstr_P _src); /* free a cstr */ void sm_cstr_free(sm_cstr_P _cstr); size_t sm_cstr_getlen(sm_cstr_P _cstr); bool sm_cstr_eq(const sm_cstr_P _s1, const sm_cstr_P _s2);
Triggering events at certain times requires either signals or periodic checks of a list which contains the events (and their times). If we use signals, then the signal handler must be thread-safe (of course). In a multi-threaded program there is one thread which takes care of signal handling. This thread is only allowed to use a few functions (signal-safe). If the main program is event-driven, then we can use one pipe to itself and the signal handler will just write a message to it which says that a timed event occurred. In that case, the event-loop will trigger due to the I/O operation (ready for reading) and the appropriate action can be performed.
The alternative is busy-waiting (polling), i.e., use a short timeout in the main event-loop (e.g., one second) and check whenever the thread awake whether a scheduled action should be performed. This seems to be more compute-intensive than the above solution.
Another way is to set the timeout to the interval to the next scheduled event. However, this causes slight problems when new events are added in the mean time that are supposed to be performed earlier than the previous next event.
Currently the signal-handler approach seems to be the best since it provides a clean interface and it doesn't change the main event handler loop logic. Note: take a look at libisc code.
System V shared memory can be used between unrelated processes (just share the key and give appropriate access). Other forms of shared memory (mmap()) require a common ancestor, which is available in form of the supervisor process. However, we have to be careful how such shared memory would be used (we can't create more on the fly, it's a fixed number).
We need an RFC 2821 and an RFC 2822 parser.
RFC 2821: Routing based on address (MX) and additional rules (configuration by admin).
RFC 2822: We also need a rewrite engine to modify addresses based on rules (configuration) by the admin.
The SMTP server/address resolver needs an RFC 2821 parser to analyze (check for syntactical correctness) and to decide what to do about addresses (routing to appropriate delivery agent).
Note: the syntax for addresses in the envelope (RFC 2821) and in the headers (RFC 2822) is different, the latter is almost a superset of the former. In theory we only need an RFC 2821 parser for SMTP server daemon, but some MTAs may be broken and use RFC 2822 addresses. Should we allow this? Maybe consider it as an option. This would require that we have a good library to do both where the RFC 2821 API is a subset of the RFC 2822 API.
The parser shouldn't be too complicated, the syntax is significantly simpler than RFC 2822. Quoting RFC 2821:
Reverse-path = Path
Forward-path = Path
Path = "<" [ A-d-l ":" ] Mailbox ">"
A-d-l = At-domain *( "," A-d-l )
; Note that this form, the so-called "source route",
; MUST BE accepted, SHOULD NOT be generated, and SHOULD be
; ignored.
At-domain = "@" domain
Domain = (sub-domain 1*("." sub-domain)) / address-literal
sub-domain = Let-dig [Ldh-str]
address-literal = "[" IPv4-address-literal /
IPv6-address-literal /
General-address-literal "]"
Mailbox = Local-part "@" Domain
Local-part = Dot-string / Quoted-string
; MAY be case-sensitive
Dot-string = Atom *("." Atom)
Atom = 1*atext
Quoted-string = DQUOTE *qcontent DQUOTE
String = Atom / Quoted-string
Some elements are not defined in RFC 2821, but RFC 2822; i.e., atext, qcontent.
IPv4-address-literal = Snum 3("." Snum)
IPv6-address-literal = "IPv6:" IPv6-addr
General-address-literal = Standardized-tag ":" 1*dcontent
Standardized-tag = Ldh-str
Snum = 1*3DIGIT ; representing a decimal integer
; value in the range 0 through 255
Let-dig = ALPHA / DIGIT
Ldh-str = *( ALPHA / DIGIT / "-" ) Let-dig
IPv6-addr = IPv6-full / IPv6-comp / IPv6v4-full / IPv6v4-comp
IPv6-hex = 1*4HEXDIG
IPv6-full = IPv6-hex 7(":" IPv6-hex)
IPv6-comp = [IPv6-hex *5(":" IPv6-hex)] "::" [IPv6-hex *5(":"
IPv6-hex)]
; The "::" represents at least 2 16-bit groups of zeros
; No more than 6 groups in addition to the "::" may be
; present
IPv6v4-full = IPv6-hex 5(":" IPv6-hex) ":" IPv4-address-literal
IPv6v4-comp = [IPv6-hex *3(":" IPv6-hex)] "::"
[IPv6-hex *3(":" IPv6-hex) ":"] IPv4-address-literal
; The "::" represents at least 2 16-bit groups of zeros
; No more than 4 groups in addition to the "::" and
; IPv4-address-literal may be present
Note about quoting: the addresses
<"abc"@abc.de> <abc@abc.de> <\a\b\c@abc.de>are the same. A string is just quoted because it may contain characters that could be misinterpreted. The ``value'' of the string is the string without quotes. Just its representation differs. Hence the parser (scanner) must get rid of the quotes and the value must be used. The quotes are only necessary for external representation. We have to be careful when strings with ``wierd'' characters are used to lookup data or passed to other programs/functions that may interpret that data, e.g., a shell. The address must be properly quoted when used externally. In some cases all ``dangerous'' characters should be replaced for safety, i.e., a list of ``safe'' characters exists and each character not in that list is replaced by a safe one. Whether this replacement is reversible is open for discussion. Some MTAs just use a question mark as replacement, which of course is not reversible.
The message submission program needs an RFC 2822 parser to extract addresses from headers as well from the command line. Moreover, addresses must be brought into a form that is acceptable by RFC 2822 (in headers) and RFC 2821 (for SMTP delivery).
atext = ALPHA / DIGIT / ; Any character except controls,
"!" / "#" / ; SP, and specials.
"$" / "%" / ; Used for atoms
"&" / "'" /
"*" / "+" /
"-" / "/" /
"=" / "?" /
"^" / "_" /
"`" / "{" /
"|" / "}" /
"~"
atom = [CFWS] 1*atext [CFWS]
dot-atom = [CFWS] dot-atom-text [CFWS]
dot-atom-text = 1*atext *("." 1*atext)
qtext = NO-WS-CTL / ; Non white space controls
%d33 / ; The rest of the US-ASCII
%d35-91 / ; characters not including "\"
%d93-126 ; or the quote character
qcontent = qtext / quoted-pair
quoted-string = [CFWS]
DQUOTE *([FWS] qcontent) [FWS] DQUOTE
[CFWS]
Address parsing (RFC 2822/2821) should be based on a tokenized version of the string representation of an address. Therefore we need a token handling library (compare postfix).
Question: can we create only one address rewriting engine or do we need different ones for RFC 2821 and 2822? Question: is it sufficient for the first version to just have a table-driven rewrite engine (only mapping like postfix, not the full rewrite engine of sendmail 8)?
The communication between program modules in sendmail X is of course hidden inside a library. This library presents an API to the modules. In its first implementation, the library will probably use sockets for the communication.
Note: we may use ``sliding windows'' just as TCP/IP does to specify the amount of data the other side can receive. This allows us to send data without overflowing the recipient. Question: can we figure this out at the lower level?
The data structures for internal communication consist of tagged fields, see also Section 3.13.12. Tagged fields are used to allow for:
Question: do we need a package header to identify packages? This may be required if ``garbled'' packages can be send over one connection. To find the begin of the next package, a linear scan for a package header would be necessary. TCP guarantees reliable connections (Unix sockets too?), so this may not be necessary. If a ``garbled'' package is received, the connection is closed such that the sender has to deal with the problem.
A record communication buffer (rcb)
can be realized as an extension of the string abstraction
(see Section 3.16.7)
by using one additional counter (![]() ) (or pointer) to keep track
of sequential reading out of it.
) (or pointer) to keep track
of sequential reading out of it.
struct sm_rcb_S
{
size_t sm_rcb_len; /* current length */
size_t sm_rcb_size; /* allocated length */
size_t sm_rcb_maxsz; /* maximum length */
uchar *sm_rcb_base; /* pointer to byte sequence */
rpool_t sm_rcb_rpool; /* data is allocated from this */
int sm_rcb_rw; /* read index/left to write */
}
Invariants:
![]() ,
,
![]()
If reading: ![]() .
If writing:
.
If writing: ![]() (no length specified)
or
(no length specified)
or ![]() size of the data to put into the RCB.
size of the data to put into the RCB.
Basic operations to create and delete RCBs:
| new() | create a new rcb |
| free() | free an rcb |
A RCB can be operated in two different modes, each of which consists of two submodes:
For 1a:
read record from file:
if we do only record oriented operations, then we can use
![]() to write data into the buffer and
to write data into the buffer and ![]() to keep track of
how much data is left to read.
to keep track of
how much data is left to read.
The first word from the file
(which is the record size,
see Section 3.13.12)
is written into ![]() (only if
(only if ![]() ). Make sure there is enough space in the buffer (right after
the size of the record is read) without exceeding the maximum size
(this may require reallocation);
read data from a file and put it into the buffer
(asserting the size will not be exceeded),
this may happen in pieces, so
). Make sure there is enough space in the buffer (right after
the size of the record is read) without exceeding the maximum size
(this may require reallocation);
read data from a file and put it into the buffer
(asserting the size will not be exceeded),
this may happen in pieces, so ![]() and
and ![]() are updated accordingly.
The buffer will be filled until
are updated accordingly.
The buffer will be filled until ![]() . Notice: the initial read may cause a problem if the number of
elements to read is specified too large: it may cause more than
one record to end up in the buffer.
. Notice: the initial read may cause a problem if the number of
elements to read is specified too large: it may cause more than
one record to end up in the buffer.
For 1b: After the entire record has been copied into the buffer we can read out of it (for decoding). Decode from buffer requires the following functionality:
rcb_getn(IN rcb_P rcb, OUT uchar *buf, IN size_t n): read ![]() characters
characters
rcb_getint(IN rcb_P rcb, OUT int *val): read an integer value
Even if we have a common encoding (e.g., lowest bit) to distingush between integers and strings we still can't use one decoding function because we need to pass a buffer and its size for strings to the function.
For 2a: encoding into rcb:
rcb_putn(IN rcb_P rcb, IN uchar *buf, IN size_t n): put ![]() characters into
characters into ![]() at current
at current ![]()
rcb_putint(IN rcb_P rcb, IN int val): put integer value into ![]() at current
at current ![]()
These functions check whether the expected record size is reached
unless it is ![]() .
.
Question: should we have an additional parameter: record type? Then we would just need one call (instead of three) to write (encode) one subrecord.
For 2b: writing to file:
rcb_snd(INOUT rcb_P rcb, IN fd_T fd):
read data from ![]() and write to
and write to ![]() .
.
Returns number of bytes left to write, i.e.,
![]() if it has to be called again,
if it has to be called again,
![]() if it is done,
if it is done,
![]() on error.
on error.
Notice:
The only (important) difference to the string abstraction explained in Section 3.16.7 is to keep track of sequential reading out of/writing into it. This is similar to I/O buffers (see Section 3.16.3.2).
As explained in Section 3.13.12 the end of a record should be marked. This is not only useful for data written to disk but also for data transferred over the network. Even though TCP offers a reliable connection, there is a change for receiving garbled RCBs, e.g., consider the following situation: a multi-threaded client sends RCBs to a client, one of the write attempts fails such that a partial RCB is transmitted, another thread sends an RCB whose begin will then mistaken as the end of the previous (partial) RCB. Even though the client should stop communicating with the server as soon as the timeout (write problem) occurs, an end-of-record marker will help to recognize the problem. However, the question is how to properly implement this. The best approach is to do this completely transparent to the application. Question: how?
As explained in Section 3.13.12 each record entry has a type field that describes the content. There is a small problem in selecting these type because they can encode information which may as well transported separately. For example, there might be errors for A, B, C, ..., then we can have
Option 1 is not easily extendible: we need to add record types for each new error and we need to recognize them on the decoding site (and obviously they have to be generated by the sender). Option 2 would cause one record type to describe a ``compound'' field. As long as the type of the subentries is clear this should not be a problem.
There are several libraries that need to be written which provide some kind of storage functionality, e.g., hash tables, (balanced) trees, RSC (4.3.5). If we can use (almost) the same API for them, then it can be fairly easy to replace an underlying implementation to trade one storage/access method against another. This can be useful if different access methods are required. For example, while all of these provide a simple lookup function (map key to value, i.e., the typical DB functionality), some provide also additional functionality, or at least a more efficient implementation of certain access methods than others. This is exemplified by the different Berkeley DB access methods (see [OBS99] and [Sleb]), e.g., hash, btree, queue. That API might serve as an example for others that need to be implemented. Starting with version 4.23.24Berkeley DB does support an in-memory database without a backup on disk. If this option would have been available earlier, it wouldn't have been necessary to (re-)implement some of the functionality.
Maps can be considered as a specialized version of (file) I/O: while (file) I/O is in general sequential (even though positioning can be used and some OS provide record-based I/O), map I/O is based on an access key (however, sequential access is usually provided too). It might be useful to treat maps as a subset of the generic (file) I/O layer, i.e., use its open(), close(), read(), write(), etc functions. Todo: investigate this further as time permits.
Note: there are basically two different kinds of maps that are used:
The first kind is used internally by sendmail X for various purpose to store and access data. The second kind is used to control the behavior of sendmail X, e.g., to map addresses from one form into another, to change options based on various keys like the name or IP address of the site to which an connection is open, etc. Even though it might be useful to distinguish between both, it seems more generic to use one common API. Maps that don't provide write access, e.g., a map of valid users usually is not written by an MTA, simply don't have the corresponding functions calls and trying to invoke those will trigger an appropriate error.
The basic API for BDB looks like this:
| db_create | create | Create a database handle |
| DB- |
open | Open a database |
| DB- |
close | Close a database |
| DB- |
lookup | Get items from a database |
| DB- |
add | Store items into a database |
| DB- |
rm | Delete items from a database |
| DB- |
destroy | Remove a database |
This doesn't fully match the naming conventions for sendmail X explained in Section 3.16.1.2; the names for the latter are listed in the second column.
Additional functions should include walk: walk through all items and apply a function to them, and for some access methods a way to get elements in a sorted order out of the storage. In Berkeley DB, the former can be implemented using the cursor functions, the latter works at least if btree is used as access method.
Generic API proposal:
| _create() | create a new object |
| _destroy() | destroy object (other name?) |
| _open() | open an object for use, this may perform an implicit create() |
| _close() | close an object, can't be used unless reopened, this does not destroy the object |
| _reopen() | close and open an object; this is done only if necessary, |
| e.g., for a DB if the file on disk has changed | |
| _add() | add an entry to an object |
| _rm() | remove an entry from an object |
| _alloc() | allocate an entry and add it to an object |
| _free() | free an entry and remove it from an object |
| _lookup() | lookup an entry, return the data value |
| _locate() | lookup an entry, return the entry |
| _first() | return first entry |
| _next() | return next entry |
Instead of creating a new function name for each map type,
the map (context) itself is passed to a generic function map_f(),
alternatively the context can provide function pointers such that
the functions are invoked as map_ctx-![]() f()
(as it is done by BDB, see above).
f()
(as it is done by BDB, see above).
An application uses the functions as follows:
To simplify the code the following shortcuts might be implemented:
Question: which level should handle the _reopen() function? It could be done in the abstraction layer but then it needs to know when to reopen a map. This could be done by checking where the underlying file has changed, but this is specific to some map implementation, e.g., Berkeley DB, while a network map does not provide such a way to check. This can be solved as follows: add a flag that indicates whether the simple check (file changed) should be performed in the abstraction layer, and add a function pointer to a _reopen() function in the map implementation which will be used if the flag is not set and the function pointer is not NULL. An additional problem is that if the _open() function takes a variable number of arguments, then those need either be resupplied when _reopen() is called, or they need to be stored in the map instance3.25(which would make it necessary to preserve that data across the sequence _close(), _open() somehow), or they need to be supplied in some other way. Such ``other way'' could be separate initialization and option settings functions, e.g., first _create() returns a map context, then various options are set via _setoption() which is a polymorphic function (compare setsockopt(2)) (and has a corresponding map_getoption() function), and finally _open() is called with the map context that has all options set in the proper way. Closing a map then requires either two steps or at least a parameter which indicates whether to discard (destroy) the map context too. However, this requires that the underlying map implementation actually supports this; Berkeley DB does not preserve the handle across the close3.26function. One way around this is to store the options in an additional abstraction layer between the map abstraction and the map implementation, or have a variable sized array of option types and option values in the map abstraction context in addition to the pointer to the map implementation context. Then the _setoption() function could store the options in that array and _reopen() could ``replay'' the calls to _setoption() by going through that array. Nevertheless, the same argument can be made here: it requires that the underlying map implementation actually supports a _create() and an _open() function; if there is only one _open() function that allocates the map context and its internal data while maybe taking several arguments, then this split can not be done.
Note: it might be useful to have a _load() callback for the _open() function to initialize data in the map, e.g., to read key and data pairs from a file. This is especially useful in conjunction with _reopen() to reload a file that has changed.
The following data seems to be sufficient to describe elements in a storage system (e.g., database):
uchar *STH_key; /* key */ uint32_t STH_key_len; /* length of key */ void *STH_data; /* pointer to data (byte string) */ uint32_t STH_data_len; /* length of data */
An alternative is to use the string type described in Section 3.16.7. The advantage of doing so is that the functions for it can be reused.
Berkeley DB uses the following structure (called DBT) to describe elements in the database as well as keys:
typedef struct {
void *data; /* pointer to byte string */
u_int32_t size; /* length of data */
u_int32_t ulen; /* length of user buffer */
u_int32_t dlen; /* length of partial record */
u_int32_t doff; /* offset of partial record */
u_int32_t flags; /* various flags */
} DBT;
For an internal read/write map the storage for the key itself is managed by the library or by the application, the data storage is by default managed by the application, i.e., the data must be persistent as long as the map is used. This is in contrast to BDB which manages the data itself since it has to store it on disk. The default can be changed by setting flags in the open() call to indicate whether the application supplies memory for storing the data in which case another field specifies the length of that memory section. This is done by the DEFEDB library. It is useful to provide callbacks for data allocation/deallocation3.27such that the library can (indirectly) manage the data storage if necessary, e.g., if it is supposed to automagically remove outdated entries, or if it can update an existing entry or create new entries based on whether the add function should allow for this, and for the destroy function to remove all allocated data (memory).
A map context should contain flags that describe how keys and data is handled. First a map implementation needs to specify whether the implementation can actually perform memory management functions (it may not have the required code). If it does not provide memory management function, then the application must take care of it. When a map is opened the application specifies whether keys and data are (de)allocated by the library (if available). The flags are per map instance, not per key/data pair; this would require to store the information in the key or data itself which would complicate the storage interface, e.g., it would have to encode the flags somehow and make sure that the application will only get the relevant part, not the additional control information (compare allocation contexts for malloc(3)).
Note: if the map abstraction uses the string type described in Section 3.16.7 then the memory management functions are those provided by the string implementation, there is no need to have additional functions and hence no function pointers are needed for this.
An abstraction layer should be placed on top of the various storages libraries to access the latter through a generic interface. This is similar to the Berkeley DB layer which specifies which type of database to use (open). To access the underlying implementation two methods are common:
The first method avoids an additional indirection, but the second can perform generic operations in one place before/after calling the specific storage library function. This is helpful for something like an expand function (sm_map_rewrite()) that replaces certain parts of the result by (parts of) the key, e.g., positional parameters (``%n'' in sendmail 8). Moreover, it makes it easier to deal with functions that aren't available because the wrapper can check for that (otherwise the function pointer must point to a dummy function).
The abstraction layer needs to provide functions to
For case 2 the abstraction layer also needs to provide the generic map functions (see Section 3.16.12).
Convention: functions that operate on
In its simplest form the maps context contains a list or a hash table (using the type as key) of registered map classes:
struct sm_maps_S
{
List/Hash sm_mapc_P;
}
A map class should look like this:
struct sm_mapc_S
{
sm_cstr_P sm_mapc_type;
uint32_t sm_mapc_flags;
sm_map_create_F sm_mapc_createf();
sm_map_destroy_F sm_mapc_destroyf();
sm_map_open_F sm_mapc_openf();
sm_map_load_F sm_mapc_loadf();
sm_map_close_F sm_mapc_closef();
sm_map_reopen_F sm_mapc_reopenf();
sm_map_add_F sm_mapc_addf();
sm_map_rm_F sm_mapc_rmf();
sm_map_alloc_F sm_mapc_allocf();
sm_map_free_F sm_mapc_freef();
sm_map_lookup_F sm_mapc_lookupf();
sm_map_locate_F sm_mapc_locatef();
sm_map_first_F sm_mapc_firstf();
sm_map_next_F sm_mapc_nextf();
}
Flags for map classes describe the capabilities of a map class, e.g., some of these are:
| MAPC-ALLOCKEY | Map can allocate storage for key |
| MAPC-ALLOCDATA | Map can allocate storage for data |
| MAPC-FREEKEY | Map can free storage for key |
| MAPC-FREEDATA | Map can free storage for data |
| MAPC-CLOSEFREEKEY | Map must free storage for key on close (destroy?) |
| MAPC-CLOSEFREEDATA | Map must free storage for data on close (destroy?) |
| MAPC-NORMAL-REOPEN | Map can be reopened using close/open |
These flags indicate whether the library can perform memory management functions. If it does not set those flags, then the application must take care of it.
A map is an instance of a map class:
struct sm_map_S
{
sm_cstr_P sm_map_name;
sm_cstr_P sm_map_type;
sm_mapc_P sm_map_class;
char *sm_map_path;
uint32_t sm_map_flags;
uint32_t sm_map_openflags; /* flags when open() was called */
uint32_t sm_map_caps; /* capabilities */
int sm_map_mode;
time_T sm_map_mtime; /* mtime when opened */
ino_t sm_map_ino; /* inode of file */
void *sm_map_db; /* for use by map implementation */
void *sm_map_app_ctx;
/* array of option types and option values */
sm_map_opt_T sm_map_opts[SM_MAP_MAX_OPT];
}
There are different type of flags for maps: some describe the state of the map, some describe the functionalities (capabilities) that are offered. Capabilities are also something that can be requested when a map is opened, if a map does not offer the requested functionality, the open fails. Note: it might be useful to have a query function that returns the capabilities of a map class.
Flags that describe the state of a map are: (some of these can probably be collapsed if locking is used)
| CREATED | Map has been created |
| INITIALIZED | Map has been initialized |
| OPEN | Map is open |
| OPENBOGUS | open failed, do not call close |
| CLOSING | map is being closed |
| CLOSED | map is closed |
| VALID | this entry is valid |
| WRITABLE | open for writing |
| ALIAS | this is an alias file |
Generic flags (options) that describe how the map abstraction layer should handle various operations:
| INCLNULL | include nul byte in key |
| OPTIONAL | don't complain if map can't be opened |
| NOFOLDCASE | don't fold case in keys |
| MATCHONLY | don't use the map value |
| ALIAS | this is an alias file |
| TRY0NUL | try without nul byte |
| TRY1NUL | try with nul byte |
| LOCKED | this map is currently locked |
| KEEPQUOTES | don't dequote key before lookup |
| NODEFER | don't defer if map lookup fails |
| SINGLEMATCH | successful only if match returns exactly one key |
The alloc() and free() functions receive the
application context as additional parameter:
typedef void *(*sm_map_*_alloc_F)(size_t size, void *app_ctx);
typedef void (*sm_map_*_free_F)(void *ptr, void *app_ctx);
The create() function creates a map instance:
typedef sm_ret_T (*sm_map_create_F)(sm_mapc_P mapc, sm_cstr_P name, sm_cstr_P type, uint32_t flags, sm_map_P *pmap, ...);
The open() function opens a map for usage:
typedef sm_ret_T (*sm_map_open_F)(sm_mapc_P mapc, sm_cstr_P name, sm_cstr_P type, uint32_t flags, char *path, int mode, sm_map_P *pmap);
Question: what is the exact meaning of the parameters, especially name, flags, path, and mode? name: name of the map, can be used for socket map? This is mostly a descriptive parameter. path: if there is a file on disk for the map this is the name of that file. So what are flags and mode? mode could have the same meaning as the mode parameter of the Unix system call chmod(2). flags could have the same meaning as the flags parameter of the Unix system call open(2), e.g.,
| O_RDONLY | open for reading only |
| O_WRONLY | open for writing only |
| O_RDWR | open for reading and writing |
| O_NONBLOCK | do not block on open |
| O_APPEND | append on each write |
| O_CREAT | create file if it does not exist |
| O_TRUNC | truncate size to 0 |
| O_EXCL | error if create and file exists |
| O_SHLOCK | atomically obtain a shared lock |
| O_EXLOCK | atomically obtain an exclusive lock |
| O_DIRECT | eliminate or reduce cache effects |
| O_FSYNC | synchronous writes |
| O_NOFOLLOW | do not follow symlinks |
Whether these flags actually make sense depends on the underlying map implementation. Questions:
Here is an example of the valid flags for a map implementation (Berkeley DB), some of which have equivalents from open(2):
| DB_AUTO_COMMIT | |
| DB_CREATE | O_CREAT |
| DB_EXCL | O_EXCL |
| DB_DIRTY_READ | |
| DB_NOMMAP | |
| DB_RDONLY | O_RDONLY |
| DB_THREAD | |
| DB_TRUNCATE | O_TRUNCATE |
The load() function needs the map context and the name of the file from which to read the data:
typedef sm_ret_T (*sm_map_load_F)(sm_map_P map, char *path);
The close() function requires only the map context:
typedef sm_ret_T (*sm_map_close_F)(sm_map_P map);
Adding an item requires the map context, the key, and the data (note: see elsewhere about whether the map needs to copy key or data).
typedef sm_ret_T (*sm_map_add_F)(sm_map_P map, sm_map_key key, sm_map_data data, unsigned int flags);
Removing an item requires the map context and the key:
typedef sm_ret_T (*sm_map_rm_F)(sm_map_P map, sm_map_key key);
typedef sm_ret_T (*sm_map_alloc_F)(sm_map_P map, sm_map_entry *pentry);
typedef sm_ret_T (*sm_map_free_F)(sm_map_P map, sm_map_entry entry);
typedef sm_ret_T (*sm_map_lookup_F)(sm_map_P map, sm_map_key key, sm_map_data *pdata);
typedef sm_ret_T (*sm_map_locate_F)(sm_map_P map, sm_map_key key, sm_map_entry *pentry);
typedef sm_ret_T (*sm_map_first_F)(sm_map_P map, sm_map_cursor *pmap_cursor, sm_map_entry *pentry);
typedef sm_ret_T (*sm_map_next_F)(sm_map_P map, sm_map_cursor *pmap_cursor, sm_map_entry *pentry);
Notes:
struct sm_mapn_S
{
sm_map_P sm_mapn_map;
uint32_T sm_mapn_refcnt;
}
sendmail 8 opens map dynamically on demand. This can be useful if some maps are not needed in some processes. Moreover, some map types do not work very well when shared between processes. For sendmail X it can be useful to close an reopen maps in case of errors, e.g., network communication problems. Question: which level should handle this: the abstraction layer or the implementation? If it's done in the abstraction layer then code duplication can be avoided, however, it's not yet clear what the proper API for this functionality is. It seems that using sm_map_close() and sm_map_open)() is not appropriate because we already have the map itself. Would sm_map_reopen() (see Section 3.16.12.0.1) be the appropriate interface?
The previous sections describe a synchronous map interface. Section 3.1.1 contains a generic description of asynchronous functions. The map abstraction layer can either provide just a synchronous map API, or it can provide the more generic approach described in Section 3.1.1, however, it should let the upper layer ``see'' whether the lower level implements synchronous or asynchronous operations.
In most cases access to maps must be protected by mutexes. This can be either provided by the abstraction layer or by the low-level implementation. Doing it in the former minimizes the amount of code duplication.
Some map implementations may be slow (e.g., network based lookups) and hence some kind of enhancement is required. One way to do this is to issue multiple requests concurrently. Besides asynchronous lookups (which are currently not supported, see Section 3.16.12.4) this can be achieved by having multiple map instances of the same map type provided the underlying implementation allows for that.
It would be very useful if this can be provided by the map abstraction layer to avoid having this implemented several times in the low level map types.
Question: how to do this properly? The map type needs to specify that it offers this functionality and some useful upper limit for the number of concurrent maps3.28.
Unfortunately older DNS resolvers (BIND 4.x) are not thread safe. The resolver that comes with BIND 8 (and 9) is supposed to be thread safe, but even FreeBSD 4.7 does not seem to support it (res_nsearch(3) is not in any library). In general there are two options to use DNS:
Option 1 does not directly work for applications that use state threads (see Section 3.20.3.1), the communication must at least be modified to use state threads I/O to avoid blocking of the entire application. Therefore it is probably not much different to chose option 2, which would be a customized (and hopefully simpler) version of the resolver library. This option however causes a small problem: how should the caller, i.e., the task that requested a DNS lookup, be informed about the result? See Section 3.1.1.1 for a general description of this problem. We could integrate the functionality directly into the application; e.g., for an application which uses event threads this is exactly the activation sequence that is used: a request is send, the task waits for an I/O event and then is activated to perform the necessary operations. However, this tightly integrates the DNS resolver functionality into the application which may not be the best approach. Alternatively the DNS request can include a context and a callback which is invoked (with the result and the context) by the DNS task. The latter is useful for an application using the event thread library. For a state threads application a different notification mechanism is used, i.e., a condition variable. See Section 4.1.2 for a description of the possible implementations.
A DNS request contains the following elements:
| name | hostname/domain to resolve |
| type | request type (MX, A, AAAA, ...) |
| flags | flags (perform recursion, CNAME, ...) |
| dns-ctx | DNS resolver context |
| event thread: | |
| app-ctx | application context |
| app-callback | application callback |
| state threads: | |
| app-cond | condition variable to trigger |
The DNS resolver context is created by a dns_ctx_new() function and contains at least these elements:
| DNS servers | list of DNS servers to contact |
| flags | flags (use TCP, ...) |
Available functions include:
| dns_mgr_ctx_new() | create a new DNS manager context |
| dns_mgr_ctx_free() | free (delete) DNS manager context |
| dns_rslv_new() | create a new DNS resolver context |
| dns_rslv_free() | free (delete) DNS resolver context |
| dns_tsk_new() | create a new DNS task |
| dns_tsk_free() | free (delete) DNS task |
| dns_req_add() | send DNS request; this may either receive a DNS request structure |
| as parameter or the individual elements |
There should be only one DNS task since it will manage all DNS requests. However, this causes problems due to:
If multiple DNS resolver tasks are used then there is the problem of distributing the requests between them and of a fallback in case of problems, e.g., timeout or truncations (UDP).
A DNS resolver task should have the following context:
| DNS server | which server? (fd is stored in task context) |
| flags | flags (UDP, TCP, ...) |
| dns-ctx | DNS resolver context |
| error counters | number of timeouts etc |
If too many errors occurred the task may terminate itself after it created a new task using a different DNS server.
Many functions can cause temporary errors of which timeouts, especially from asynchronous functions, are hard to handle. Question: should the caller implement a timeout or the callee? That is, should the caller set some timestamp on its request and the data where the result should be stored and check this periodically or should the callee implement the timeout and guarantee returning a result (even if it is just an error code) to the caller? The latter looks like the better solution because it avoids periodic scanning in the application (caller), however, then it needs to be in the callee, which at least has some centralized list of outstanding requests. The caller has to make sure that its open requests are removed after some time, e.g., some sort of garbage collection is required. If the caller removes a request but the callee returns a result later on, then the caller must handle this properly; in the simplest case it can just ignore the result. A more sophisticated approach would use a cancel_request() function such that the request is also discarded by the callee.
In some cases the caller can easily implement a timeout, e.g., SMTPS does this when it waits for a reply from QMGR. If the reply does not arrive within a time limit, then the SMTP server returns a temporary error code to the client.
Todo: structure this.
For example: after final dot a message must (probably) be fsync()ed, but we don't want to do this for each individually, but maybe a group. Then we use fsync(within-10-seconds) and the library can group several several requests together (compare softupdates).
ISC [ISC01] logging uses a context (type isc_log_t), a configuration (type isc_logconfig_t), categories and modules, and channels.
Channels specify where and how to log entries:
<channel> ::= "channel" <channel_name> "{"
( "file" <path_name>
[ "versions" ( <number> | "unlimited" ) ]
[ "size" <size_spec> ]
| "syslog" <syslog_facility>
| "stderr"
| "null" );
[ "severity" <priority>; ]
[ "print-category" <bool>; ]
[ "print-severity" <bool>; ]
[ "print-time" <bool>; ]
"}";
<priority> ::= "critical" | "error" | "warning" | "notice" |
"info" | "debug" [ <level> ] | "dynamic"
For each category a logging statement specifies where to log entries for that category:
<logging> ::= "category" <category_name> { <channel_name_list> };
Categories are ``global'' for a software package, i.e., there is a common superset of all categories for all parts of the package. Some parts may only use a subset, but the meaning of a category must be consistent across all parts, otherwise the logging configuration will cause problems (at least inconsistencies). Modules are use by the software (libraries etc) to describe from which part of the software a logging entry has been made.
The API is as follows:
isc_log_create(isc_mem_t *mctx, isc_log_t **lctxp, isc_logconfig_t **lcfgp); isc_log_destroy(isc_log_t **lctxp);
isc_logconfig_create(isc_log_t *lctx, isc_logconfig_t **lcfgp); isc_logconfig_use(isc_log_t *lctx, isc_logconfig_t *lcfg); isc_logconfig_get(isc_log_t *lctx); isc_logconfig_destroy(isc_logconfig_t **lcfgp);
isc_log_registercategories(isc_log_t *lctx, isc_logcategory_t categories[]); isc_log_registermodules(isc_log_t *lctx, isc_logmodule_t modules[]);
To create and use channels:
isc_log_createchannel(isc_logconfig_t *lcfg, const char *name, unsigned int type, int priority, const isc_logdestination_t *destination, unsigned int flags) isc_log_usechannel(isc_logconfig_t *lcfg, const char *name, const isc_logcategory_t *category, const isc_logmodule_t *module)
isc_log_write(isc_log_t *lctx, isc_logcategory_t *category, isc_logmodule_t *module, int priority, const char *format, ...) isc_log_vwrite(isc_log_t *lctx, isc_logcategory_t *category, isc_logmodule_t *module, int priority, const char *format, va_list args)
isc_log_setdebuglevel(isc_log_t *lctx, unsigned int level); isc_log_getdebuglevel(isc_log_t *lctx);
isc_log_wouldlog(isc_log_t *lctx, int priority);
isc_log_setduplicateinterval(isc_logconfig_t *lcfg, unsigned int interval); isc_log_getduplicateinterval(isc_logconfig_t *lcfg);
isc_log_settag(isc_logconfig_t *lcfg, const char *tag); isc_log_gettag(isc_logconfig_t *lcfg);
isc_log_opensyslog(const char *tag, int options, int facility); isc_log_closefilelogs(isc_log_t *lctx);
isc_log_categorybyname(isc_log_t *lctx, const char *name); isc_log_modulebyname(isc_log_t *lctx, const char *name);
There are some technical problems that must be solved by a clean design. For example, in sendmail 8.12 the function that returns error messages for error codes includes the basic OS error codes but also extensions like LDAP if it has been compiled in. This makes it hard to reuse that library function in different programs that don't want to use LDAP because it will be linked in since it is referenced in the error message function. This must be avoided for obvious reasons.
One possible solution is to have a function list where modules register their error conversion functions. However, this requires that the error codes are disjunct. This can be achieved as explained in Section 3.15.2. So the current approach (having a ``global' error conversion function) doesn't work in general. The error conversion must be done locally and the error string must be properly propagated.
Question: how do we build sendmail X on different systems? Currently we have one big file (conf.h) with a lot of OS-specific definitions and several OS-specific include files (os/sm_os_OS.h). However, this is ugly and hard to maintain. We should use something like autoconf to automagically generate the necessary defines on the build system. This should minimize our maintainance overhead, esp. if it also tests whether the feature actually works.
Since we do not have enough man power to develop yet another build system and since our current system is completely static, we will use the GNU autotools (automake, autoconf, etc) for sendmail X. We already have a (partial) patch for sendmail 8 to use autoconf etc (contributed by Mark D. Roth). We can use that as a basis for the build configuration of sendmail X.
Interestingly enough, most other open source MTAs use their own build system. However, BIND 9 and Courier MTA use also autoconf.
Note: there are some things which can't be solved by using autoconf. Those are features of an OS that cannot be (easily or at all) determined by a test program. Examples for these are:
In those case we need to provide the data in some script (config.cache?) that can be easily used by configure. The data should probably be organized according to the output of config.guess: ``CPU-VENDOR-OS'', where OS can be ``SYSTEM'' or ``KERNEL-SYSTEM''.
This section contains hints about some operating system calls, i.e., how they can be used.
This section should contain only standard (POSIX?) behavior, nothing specific to some operating system. See the next section for the latter.
Todo: structure this and then use it properly.
(OpenBSD man page, should apply to all OS) If the socket is marked non-blocking and no pending connections are present on the queue, accept() returns an error as described below.
It is possible to select(2) or poll(2) a socket for the purposes of doing an accept() by selecting it for read.
One can obtain user connection request data without confirming the connection by issuing a recvmsg(2) call with an msg_iovlen of 0 and a nonzero msg_controllen, or by issuing a getsockopt(2) request. Similarly, one can provide user connection rejection information by issuing a sendmsg(2) call with providing only the control information, or by calling setsockopt(2).
Question about the last sentence: how to do this and is it portable?
This section contains hints about the behavior of some system calls on certain operating system. That is, anything that is interesting with respect to the use of system calls in sendmail X. For example: don't use call xzy in these situations on this OS.
Todo: structure this.
Just some unsorted notes about worker threads.
We have a pool of worker threads. Can/should this grow/shrink dynamically? In first attempt: no, but the data structures should be flexible. We may use fixed size arrays because the number of threads will possibly neither vary much nor will it be very large. However, fixed size doesn't refer to compile time, but configuration (start) time.
We have a set of tasks. This set will vary (widely) over time. It will have a fixed upper limit (configuration time), which depends for example on the number of available resources of the machine/OS, e.g., file descriptors, memory.
We need a queue of runnable tasks (do we need/want multiple queues? Do we want/need prioritized queues?). Whenever a task becomes active (in our case usually: I/O is possible) then it will be added to the ``run'' queue (putwork()). A thread that has nothing to do, looks for work by calling getwork(). These two functions access the queue (which of course is protected by a condition variable).
Maybe we can create some shortcuts (e.g., if a task becomes runnable and there is an inactive worker thread, give it directly to it), but that's probably not worth the effort (at least in the first version).
A SMTP server is responsible for a SMTP session. As such it has a file descriptor (fd) that denotes the connection with the client. The server reads commands from that fd and answers accordingly. This seems to be a completely I/O driven process and hence it should be controlled by one thread that is watching I/O activities. This assumes that local operations are fast enough or that they can be controlled by the same loop.
There is one control thread that does something like this:
while (!stop)
{
check for I/O activity
- timeout? check whether a connection has really timed out
(inactive for too long)
- input on fd:
lookup context that takes care of this fd
add context to runnable queue
- fd ready for output:
lookup context that takes care of this fd
add context to runnable queue
- others?
}
Question: do we remove fd from the watch-set when we schedule work for it? If so: who puts it back? A worker thread when it performed the work?
The worker threads just do:
while (!stop)
{
get_work(&ctx);
ctx->perform_action(ctx);
}
See also Section 3.16.4 about programming problems.
It would be nice to build a skeleton library that implements this model. It then can be filled in with the appropriate data structure, that contain (links to) the actual data that is needed.
It would be even better to implement the generic model (multiple, pre-forked processes with worker threads) as a skeleton. This should be written general enough such that it can be tweaked (run time/compile time) to extreme situations, i.e., one process or one thread. The latter is probably not possible with this model, since there must be at least one control thread and one worker thread. Usually there's also a third thread that deals with signals.
However, this generic model could be reused in other situations, e.g., the first candidate would be libmilter.
This section contains some comments about available thread libraries. We try to investigate whether those libraries are suitable for use in sendmail X, and if so, for which components.
Some comments about [SGI01]: State Threads (ST) for Internet Applications (IA).
We assume that the performance of an IA is constrained by available CPU cycles rather than network bandwidth or disk I/O (that is, CPU is a bottleneck resource).
This isn't true for SMTP servers in general, they are disk I/O bound. Does this change the suitability of state threads for SMTPS?
The state of each concurrent session includes its stack environment (stack pointer, program counter, CPU registers) and its stack. Conceptually, a thread context switch can be viewed as a process changing its state. There are no kernel entities involved other than processes. Unlike other general-purpose threading libraries, the State Threads library is fully deterministic. The thread context switch (process state change) can only happen in a well-known set of functions (at I/O points or at explicit synchronization points). As a result, process-specific global data does not have to be protected by mutual exclusion locks in most cases. The entire application is free to use all the static variables and non-reentrant library functions it wants, greatly simplifying programming and debugging while increasing performance.
The application program must be extremely aware of this! For example: x = GlobalVar; y = f(x); GlobalVar = y; is ``dangerous'' if f() has a ``synchronization point''.
Note: Any blocking call must be converted into an I/O event, otherwise the entire process will block, because scheduling is based on asynchronous I/O. This doesn't happen with POSIX threads. Does this make ST unusable for the SMTPS? For example, fsync() may cause a problem. Question: can we combine ST and POSIX threads? The latter would be used for blocking calls, e.g., fsync(), maybe read()/write() to disk, or compute-intensive operations, e.g., cryptographic operations during TLS handshake. Answer: no [She01a].
Note: if you link with a library that does network I/O, it must use the I/O calls of ST [She01b]:
This is a general problem - external libraries should conform to the core server architecture. E.g., if the core server uses POSIX threads, all libraries must be thread-safe and if the core server is ST-based, all libraries must use ST socket I/O.That might be an even bigger problem than the compute-intensive operations. However, those libraries might only be used in the address resolver.
Since purely event based programming is hard as explained in Section 3.16.4, other approaches have been suggested.
The problems with a programming model that uses one thread for each connection have already been mentioned in Section 2.5.2, 4a. Additionally, the scheduling of those threads is entirely up to the OS (or the thread library).
We would like to reduce the number of threads without having to resort to the complicated event based programming model. Hence we use a worker model, but we do not need to split functions when they perform a blocking call. Instead, we add some mechanism such that the worker thread library ``knows'' whenever a thread executes those (compute intensive or blocking) functions. This ``helps'' the OS/thread library to schedule threads by restricting the number of threads in those sections (regions).
One way to deal with the problem explained above is to protect those regions by counting semaphores to limit the number of threads that can execute those (compute intensive or blocking) functions.
Example: we have one counting semaphore (iosem) for events that must be taken care of and one (compsem) for a compute intensive section. Before a worker thread takes a task out of the queue in which the event scheduler added them, it must acquire iosem. When a thread wants to enter the compute intensive section, it releases iosem (thus another worker thread can take care of an event task), and acquires compsem, which may cause it to block (thus allowing another thread to run). After the thread finished the compute intensive section, it releases compsem and acquires iosem again before continuing.
Notice: it is still possible that the OS scheduler will let a compute intensive operation continue without switching to another thread. Scheduling threads is usually cooperative, not time-sliced. Hence we may have a similar problem here as for state threads.
Another way to deal with tasks that can block is to increase the number of allowed threads dynamically whenever a task enters a code section in which it may block. When it leaves that code section, the number of allowed threads is decreased again.
Note: this looks like a very simple solution to deal with threads that can block, however, there are some details that need to be handled properly. For example, there can be many threads which wait for an event and hence each of them increases the number of allowed threads such that the system can continue to operate. Next all of the threads can be unblocked because the events for which they are waiting occurred -- e.g., the DNS library answers requests for the same item all at once -- hence the number of allowed threads is decreased significantly, such that there are more current threads than allowed threads. If the tasks that have been waiting for the events terminate almost immediately, e.g., just prepare the results for sending back to the clients, then the worker threads that executed those tasks become idle, but the number of current tasks exceeds the allow limit. Hence the scheduling of new tasks must not just take the number of current tasks and the allowed number of tasks into account but also the number of idle tasks that can be reused. However, instead of checking whether the number of idle tasks is greater than zero the value should be compared with the number of allowed tasks. The intention is that the number of active tasks is less than the number of allowed tasks.
Instead of changing the limits of allowed threads, it might be simpler to count the number of active threads, especially considering the last paragraph in the previous section. Initially the number of active threads is obviously zero. Whenever a worker executes a task, the number is increased, and decreased then the (user) function returns. The number of active threads is decreased whenever a task enters a code section in which it blocks, and increased after it unblocks.
New tasks can be scheduled if the number of active tasks (instead of the number of total/current tasks) is less than the number of allowed tasks. This check is easier than the one described in the previous section.
Only the proposal explained in Section 3.20.4.1 actually restricts the number of threads that may perform a compute intensive function. None of the proposals however restricts the number of threads because there can always be threads that are blocked waiting to acquire a semaphore or waiting for a condition. To avoid this, functions must actually be written in a different style (as ``continuations''). However, even that approach does not solve all the problems because in some cases it is impossible to know at the application level whether a (library) function may block.
An event thread library provides the basic framework for a worker based thread pool that is driven by I/O events and by wakeup times for tasks.
The library uses a general context that describes one event thread system and a per task context. It maintains two queues: a run queue of tasks that can be executed, and a wait queue of tasks that wait for some event (IS-READABLE, IS-WRITABLE, TIMEOUT, NEW-CONNECTION (listen())). Each task is at most in one of the queues at each time; if it is taken out of a queue, it is under the sole control of the function that removed it from the queue. If this model can be achieved then no per-task mutex is required, i.e., access to a task is either protected by the mutex for the queue it is in or is is ``protected'' by the fact that it isn't in a queue.
The system maintains some number of worker threads between the specified minimum and maximum. Idle threads vanish after some timeout until the minimum number is reached. An application first initializes the library (evthr_init()), then it creates at least one task (evthr_task_new()), and thereafter calls evthr_loop() which in turn monitors the desired events (I/O, timeout) and invokes the registered callback functions. Those callback functions return a result which indicates what should happen next with the task:
| flag | meaning |
| OK | do nothing, task has been taken care of |
| WAITQ | put in wait queue |
| RUNQ | put in run queue |
| SLPQ | sleep for a while |
| DEL | delete task |
| TERM | terminate event thread loop |
Additionally the task may want to change the events it is waiting for. This can be accomplished in several ways:
Solution 2 would extend the return values given before by more flags (the required values can be easily encoded as bits in an integer value). These flags could be returned as ``SET'' and ``CLEAR''.
| flag | meaning |
| RD | IS-READABLE |
| WR | IS-READABLE |
| SL | TIMEOUT |
| LI | NEW-CONNECTION |
To maximize concurrency, the system must be able to handle multiple requests over one file descriptor concurrently. This is required for the QMGR if it serves requests from SMTPS, which is multi-threaded and will use only one connection per process, over which it will multiplex all requests to (and answers from) the QMGR. Hence there must a (library supplied) function that can be called from an application to put a task back into the wait queue after it read a request (usually in form of an RCB, see Section 3.16.11.1.1). Then the thread can continue processing the request while the task manager can wait for an event on the same file descriptor and schedule another thread to take care of it. This way multiple requests can be processed concurrently.
This raises another problem: usually tasks in a server wait for incoming requests. Then they process them and send back responses. However, if an application returns a task as soon as possible to the wait queue, then it can't change the event types for the task (to include IS-WRITABLE so the answer is sent back to the client), because it relinquished control of it. So either the task descriptions must be protected by a mutex (which significantly complicates locking and error handling), or a different way must be used to change the event mask of a task (see 3.20.5.1.2). One such way is to provide a function that informs the task manager of the change of the event mask, i.e., send the task manager (over an internal communication mechanism, usually a pipe) the request to enable a certain event type (e.g., IS-WRITABLE). Since the task manager locks both queues as soon as an event occurred, it can easily change the task event type without any additional overhead. Moreover, this solution has the useful side effect that the wait queue is scanned again and the new event type is added to the list of events to wait for. However, the task might be active, i.e., in neither of the queues. In that case, we can either request that the user-land program does not change the status flags (which is probably a good idea anyway), or we actually have to use a mutex per task, or we need to come up with another solution.
A related problem is ``waking'' up another task. For example, we may have a task that periodically performs a function if data is available on which to act. If no data is available, then this task should not wake up at all, or only in long intervals. Initially the task may wake up in long intervals, look for data, and go back to sleep for the long interval if no data is available. If however data becomes available while the task is sleeping for the long interval, its timeout should be decreased to the short interval. There might be varying requirements:
This can probably be handled similar to the problem mentioned before, in addition to telling the task manager that a certain event type should be enabled, it also tells it the new timeout.
The task context should contain the following status flags:
There doesn't seem to be a way around using a mutex to protect access to the event request flags (1) and similar data, e.g., the timeout of a task. If some data can be modified in a task context while it is not ``held'' because it's in one of the queues, then we need to protect it.
Maybe we can split the event request flags:
Then we can modify the event request flags of a task when it is ``under control'', i.e., when it is in a queue and the main control loops examines the tasks. That is, a function adds a change request for a task to a list; the change request includes the new event request flags and the task identifier (as well as other data that might be necessary, e.g., new sleep time). When the main loop is invoked, it will check the change request list and apply all changes to tasks that are under its control, i.e., in the wait queue. This should allow us to avoid per-task mutexes.
Alternatively, we can use mutexes just to protect the ``new request'' flags (see list above: item 2). That way the protected data is fairly small and there should almost never be any contention. Moreover, we can avoid having a list (with all its problems: allocation, searching for data, etc).
It might be useful to be able to specify a task that is invoked if the system is idle (the so-called ``idle task''). For example, if the system doesn't do anything (all threads idle), invoke the idle task. That task may take some options like:
Question: how to "signal" the idle task when the system is busy again? It might be useful to give this task a low priority in case other tasks are started while it is running such that the scheduler can act accordingly. Notice that some pthread implementation do not care much about priorities, some even implement cooperative mult-threading.
Question: what about callback functions for signals?